
As COVID-19 continues to affect the lives of millions of people around the world, having the most recent and accurate information is an increasingly important tool to help combat the disease.
We’ve been tracking COVID-19 cases for a few months in our coronavirus dataset. In addition to tracking case information, keeping up with policies and guidelines is also integral to flattening the coronavirus curve. This blog will explore the Coronavirus State Actions dataset and how we used collaborative tools in DoltHub to improve and add value to state actions data.
Coronavirus state actions#
The National Governors Association (NGA) has a State Action Tracking Chart, which tracks the steps US states and territories have taken to address coronavirus. We started importing this dataset into Dolt on April 2, 2020, but were able to backfill the data starting from March 25, 2020.
NGA updates this data on weekdays, and adds new actions when they become relevant. For example, the March 25 data does not include domestic_travel_limitations or statewide_mask_policy. You can see the first 15 states to institute domestic travel limitations since then:
doltsql> select * from state_action_dates where state_action = "domestic_travel_limitations" and start_date is not null order by start_date asc limit 15;
+----------+-----------------------------+--------------+-------------------------------+----------+
| state_id | state_action | sequence_num | start_date | end_date |
+----------+-----------------------------+--------------+-------------------------------+----------+
| AK | domestic_travel_limitations | 1 | 2020-03-27 00:00:00 +0000 UTC | <NULL> |
| HI | domestic_travel_limitations | 1 | 2020-03-27 00:00:00 +0000 UTC | <NULL> |
| KS | domestic_travel_limitations | 1 | 2020-03-27 00:00:00 +0000 UTC | <NULL> |
| MD | domestic_travel_limitations | 1 | 2020-03-27 00:00:00 +0000 UTC | <NULL> |
| PR | domestic_travel_limitations | 1 | 2020-03-27 00:00:00 +0000 UTC | <NULL> |
| RI | domestic_travel_limitations | 1 | 2020-03-27 00:00:00 +0000 UTC | <NULL> |
| SC | domestic_travel_limitations | 1 | 2020-03-27 00:00:00 +0000 UTC | <NULL> |
| TX | domestic_travel_limitations | 1 | 2020-03-27 00:00:00 +0000 UTC | <NULL> |
| ND | domestic_travel_limitations | 1 | 2020-03-30 00:00:00 +0000 UTC | <NULL> |
| NM | domestic_travel_limitations | 1 | 2020-03-30 00:00:00 +0000 UTC | <NULL> |
| OK | domestic_travel_limitations | 1 | 2020-03-30 00:00:00 +0000 UTC | <NULL> |
| AR | domestic_travel_limitations | 1 | 2020-03-31 00:00:00 +0000 UTC | <NULL> |
| CT | domestic_travel_limitations | 1 | 2020-03-31 00:00:00 +0000 UTC | <NULL> |
| DE | domestic_travel_limitations | 1 | 2020-03-31 00:00:00 +0000 UTC | <NULL> |
| FL | domestic_travel_limitations | 1 | 2020-03-31 00:00:00 +0000 UTC | <NULL> |
+----------+-----------------------------+--------------+-------------------------------+----------+You can also use this dataset to get details about the status of upcoming primary elections:
doltsql> select * from state_events where event = "primary_election" and event_status = "Delayed/Rescheduled" or event_status = "On Schedule" order by original_date asc;
+----------+------------------+---------------------+-------------------------------+-------------------------------+-----------------------------------------------------------------------------------------------------+
| state_id | event | event_status | original_date | new_date | notes |
+----------+------------------+---------------------+-------------------------------+-------------------------------+-----------------------------------------------------------------------------------------------------+
| OH | primary_election | Delayed/Rescheduled | 2020-03-17 00:00:00 +0000 UTC | 2020-04-28 00:00:00 +0000 UTC | <NULL> |
| GA | primary_election | Delayed/Rescheduled | 2020-03-24 00:00:00 +0000 UTC | 2020-05-19 00:00:00 +0000 UTC | <NULL> |
| LA | primary_election | Delayed/Rescheduled | 2020-04-04 00:00:00 +0000 UTC | 2020-06-20 00:00:00 +0000 UTC | <NULL> |
| CT | primary_election | Delayed/Rescheduled | 2020-04-28 00:00:00 +0000 UTC | 2020-06-02 00:00:00 +0000 UTC | <NULL> |
| DE | primary_election | Delayed/Rescheduled | 2020-04-28 00:00:00 +0000 UTC | 2020-06-02 00:00:00 +0000 UTC | <NULL> |
| MD | primary_election | Delayed/Rescheduled | 2020-04-28 00:00:00 +0000 UTC | 2020-06-02 00:00:00 +0000 UTC | <NULL> |
| NY | primary_election | Delayed/Rescheduled | 2020-04-28 00:00:00 +0000 UTC | 2020-06-23 00:00:00 +0000 UTC | <NULL> |
| PA | primary_election | Delayed/Rescheduled | 2020-04-28 00:00:00 +0000 UTC | 2020-06-02 00:00:00 +0000 UTC | <NULL> |
| RI | primary_election | Delayed/Rescheduled | 2020-04-28 00:00:00 +0000 UTC | 2020-06-02 00:00:00 +0000 UTC | <NULL> |
| KS | primary_election | On Schedule | 2020-05-02 00:00:00 +0000 UTC | <NULL> | Democratic only; in-person voting has been cancelled and the election will be held entirely by mail |
| IN | primary_election | Delayed/Rescheduled | 2020-05-05 00:00:00 +0000 UTC | 2020-06-02 00:00:00 +0000 UTC | <NULL> |
| NE | primary_election | On Schedule | 2020-05-12 00:00:00 +0000 UTC | <NULL> | <NULL> |
| WV | primary_election | Delayed/Rescheduled | 2020-05-12 00:00:00 +0000 UTC | 2020-06-09 00:00:00 +0000 UTC | <NULL> |
| KY | primary_election | Delayed/Rescheduled | 2020-05-19 00:00:00 +0000 UTC | 2020-06-23 00:00:00 +0000 UTC | <NULL> |
| OR | primary_election | On Schedule | 2020-05-19 00:00:00 +0000 UTC | <NULL> | <NULL> |
| DC | primary_election | On Schedule | 2020-06-02 00:00:00 +0000 UTC | <NULL> | <NULL> |
| MT | primary_election | On Schedule | 2020-06-02 00:00:00 +0000 UTC | <NULL> | <NULL> |
| NJ | primary_election | On Schedule | 2020-06-02 00:00:00 +0000 UTC | <NULL> | <NULL> |
| NM | primary_election | On Schedule | 2020-06-02 00:00:00 +0000 UTC | <NULL> | <NULL> |
| SD | primary_election | On Schedule | 2020-06-02 00:00:00 +0000 UTC | <NULL> | <NULL> |
+----------+------------------+---------------------+-------------------------------+-------------------------------+-----------------------------------------------------------------------------------------------------+Coronavirus county school closures#
The US state actions data from NGA was readily available in an easy-to-digest format. School closures are an important measure of economic impact during this unprecedented time, and while the NGA data has school closure information by state, we also wanted to track this information at a more granular level. We decided school closure data by county could add more value than just closures by state. Some schools closed before the state shut down, and some after. This was an interesting natural experiment that we wanted to document.
When I first started to research, I could not find a pre-cooked dataset with all county school closure information. It would take me too long to search for school closures for all 3,142 counties and county equivalents on my own, so I decided to utilize some DoltHub tools, like pull requests, to assist with team collaboration and data review.
What are pull requests?#
For those less familiar with Git and GitHub, this is the definition of a pull request (PR) on GitHub:
Pull requests let you tell others about changes you’ve pushed to a branch in a repository on GitHub. Once a pull request is opened, you can discuss and review the potential changes with collaborators and add follow-up commits before your changes are merged into the base branch.
Dolt and DoltHub are Git and GitHub for data. In terms of data, a pull request is a way of notifying team members of a change in the data and/or schema. The team has the ability to review these changes and approve or reject them before they get merged into the master branch.
If I wanted to add some data to the county_state_closures table, an example of a simple workflow would look like this:
- I clone the Coronavirus state actions dataset
$ dolt clone dolthub/corona-virus-state-action- I create a dedicated branch in my local Dolt repo and add some data to
county_school_closures
$ dolt checkout -b taylor/add-CA-counties
$ dolt table import -r county_school_closures all-ca-school-closures.csv
$ dolt add county_school_closures
$ dolt commit -m "Add school closures for all CA counties"
- I push the branch to the remote repo on DoltHub
$ dolt push origin taylor/add-CA-counties-
I open a pull request with my new branch
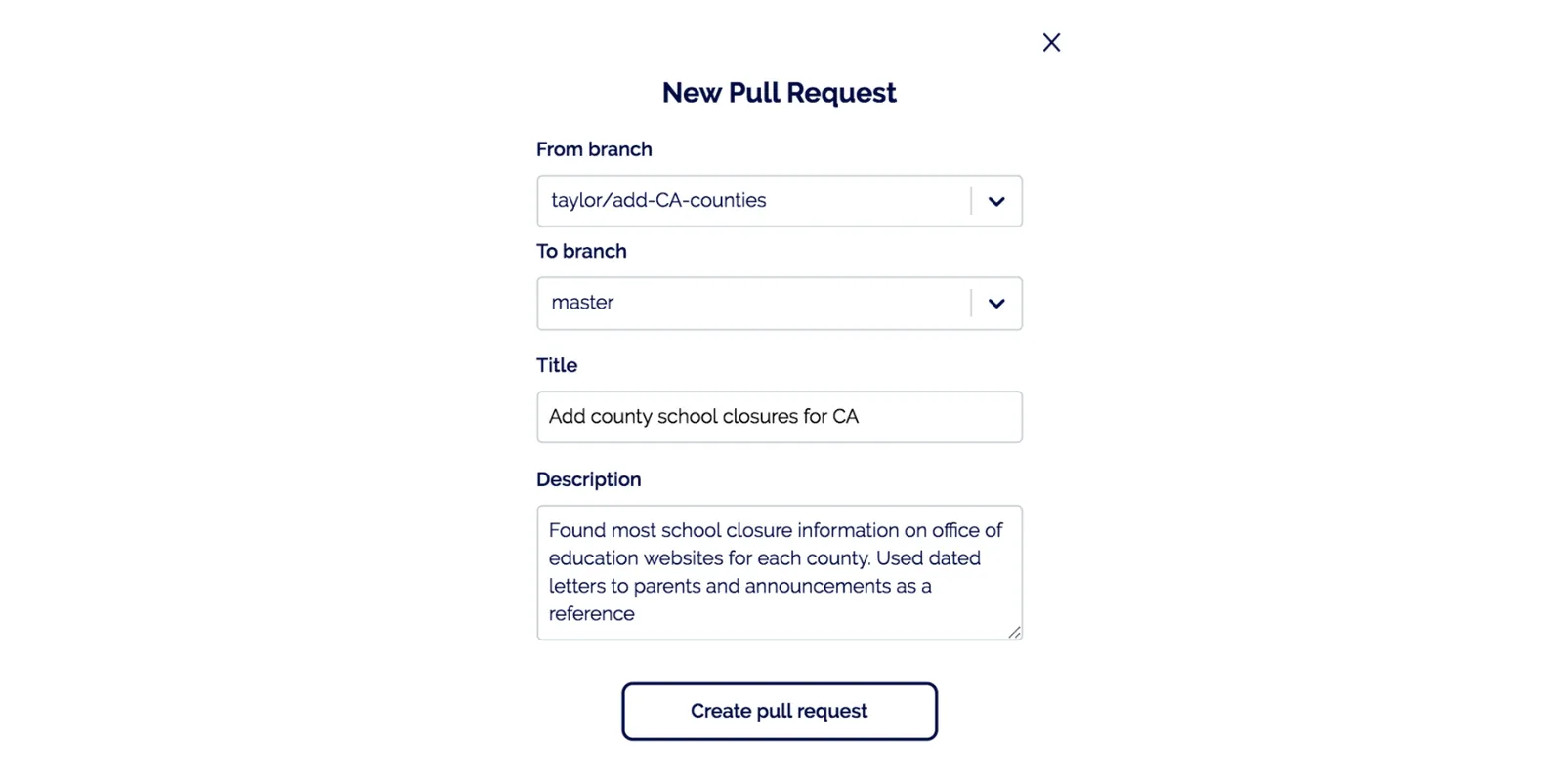
-
Team member Tim reviews the data, discusses it, and recommends changes
-
Tim is eventually satisfied with changes after an iteration or two

-
I merge my branch into the master branch (web merge coming soon!)
$ dolt checkout master
$ dolt merge taylor/add-CA-counties
# If there are conflicts:
$ dolt conflicts cat .
$ dolt conflicts resolve --help
$ dolt push origin masterTeam data collaboration using pull requests#
When I started looking for a single source with school closure data by county, I came up dry. This was both exciting and disappointing, as we could be the first to provide this novel information, but finding current data from outdated school websites is difficult and time-consuming.
As a proof-of-concept, I used California as an example to find school closure dates for all CA counties. It took about 3 hours to go through county office of education websites and social media for all 58 California counties. This felt like a reasonable amount of time for one state, but spending 150 hours extracting data for all states is a different story.
I decided to recruit our brilliant 11-person team to help me out. I gave them two days to complete some homework: open a PR with all county school closures for one state.
Here begins a day-long data collaboration journey that was overall productive, but admittedly a bit bumpy along the way:
Step 1: Schema#
Before I asked the team to help me out, I needed to come up with a schema so it would be clear what the shape of the data should look like as everyone was researching. I opened a pull request with a schema I thought could work:
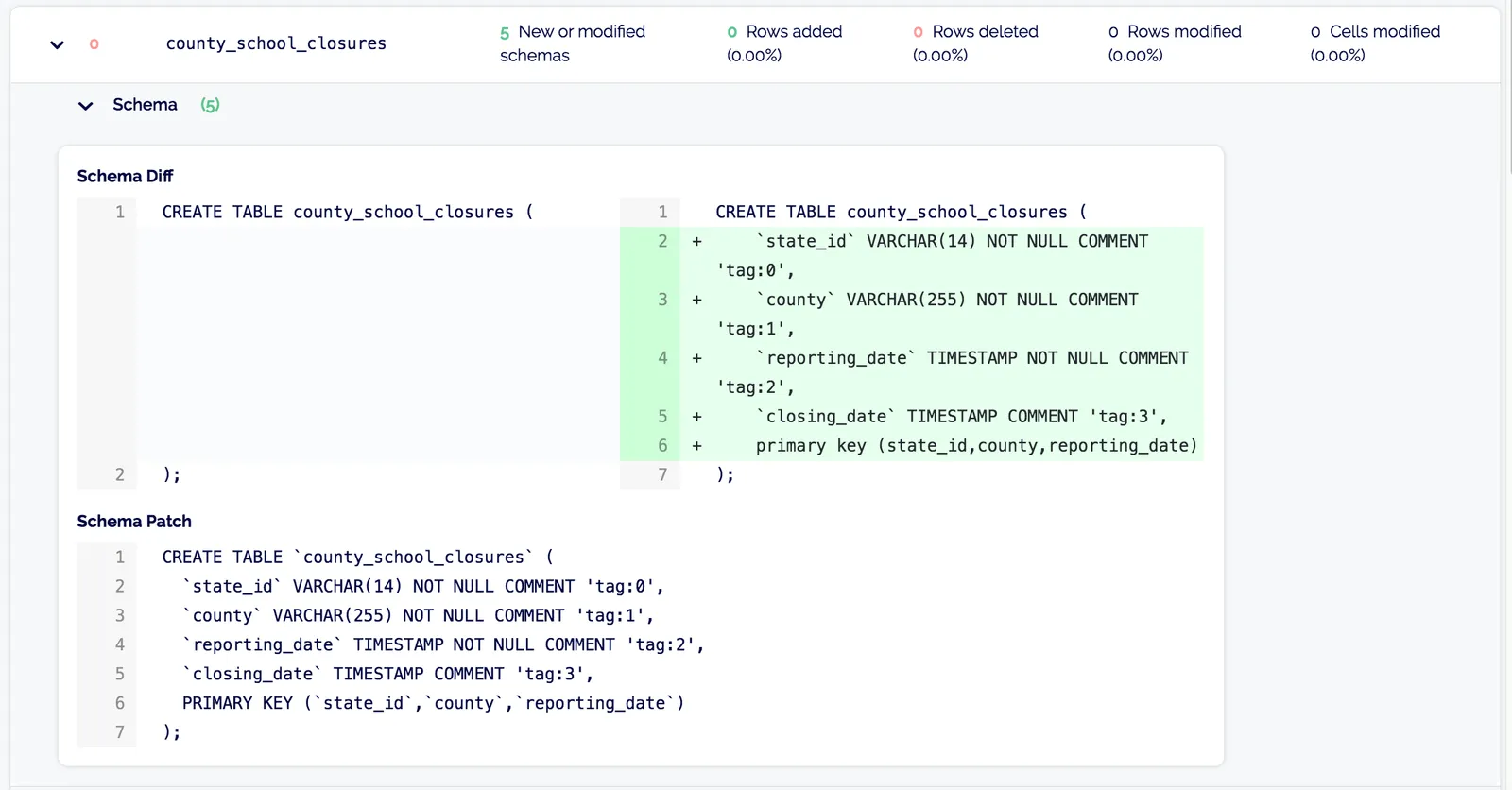
Tim reviewed my schema and had some ideas for improvement:
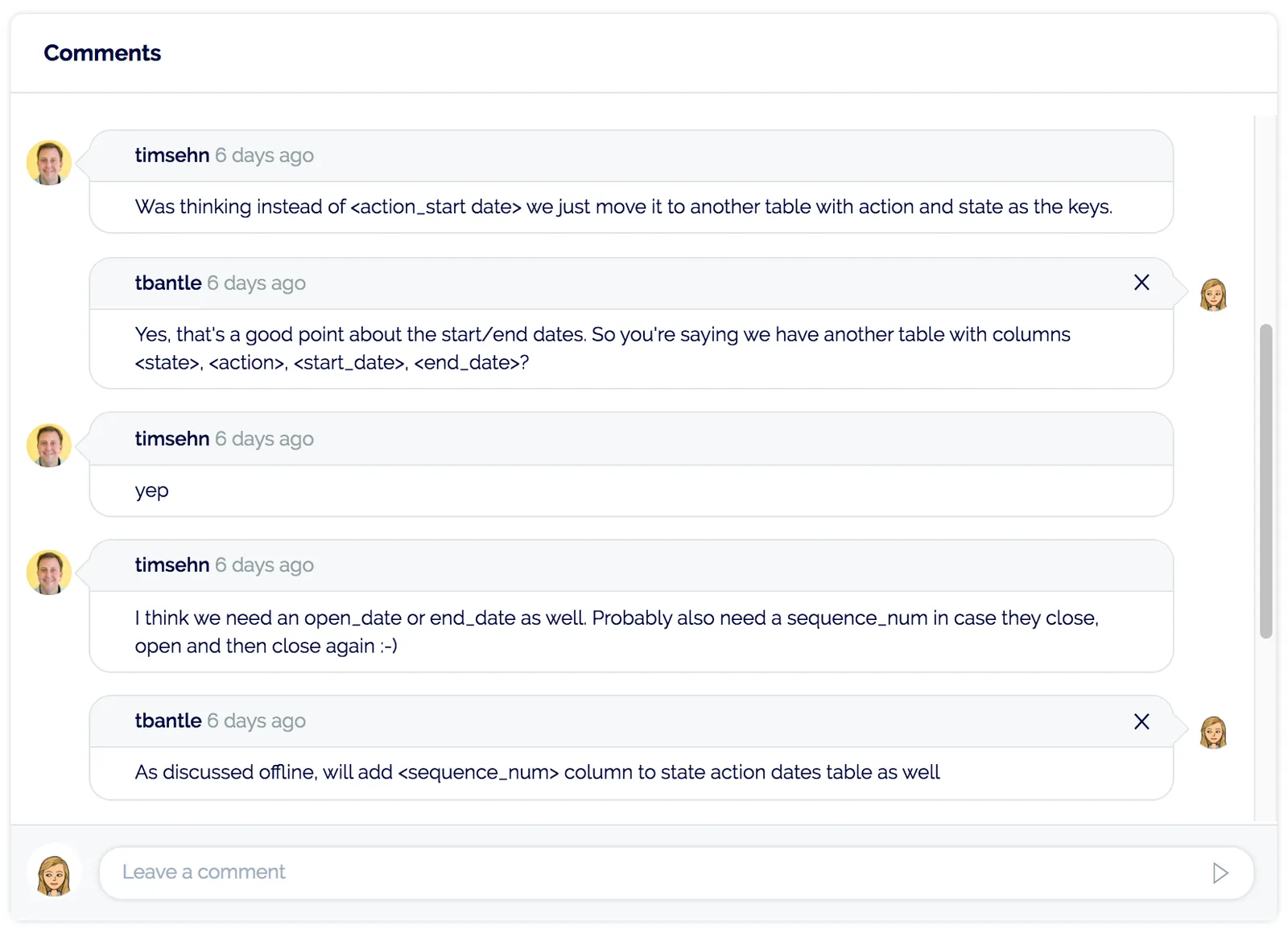
I added another table, changed some columns, and my schema was ready to be merged into the master branch.
Step 2: Homework#
Time to get the team involved. I assigned everyone 4-5 states and gave them two days to submit a PR with the county school closures for just one of their assigned states.
Things started off pretty well. People were sharing ideas for efficiently getting county names from Wikipedia, and another suggested I add a source column to make it clear where the school closure date came from.
As they started getting deeper into trying to find county school closure dates, a few problems bubbled up. While California county education websites had enough barebones information to determine a closure start date, this was not the case for every state. Not all websites had dated letters and announcements, if they even had websites at all. The digging for some states took longer than expected, making this process pretty painful. One teammate compared finding this data to “solving the world’s stupidest murder mystery”.
Although difficulty finding county school closure data led to some (probably deserved) frustration toward me and my homework, this process brought up an important question: did I have the wrong schema to begin with?
Step 3: Reevaluation#
Every county in California had some kind of county office of education website with either a dated coronavirus letter/announcement or Facebook group with dated posts. For example, if I googled “Ventura County CA school closures”, the first search result is a website that looks like this:
However, not all states are the same. If you google “Big Horn County WY school closures”, this is what the results look like:
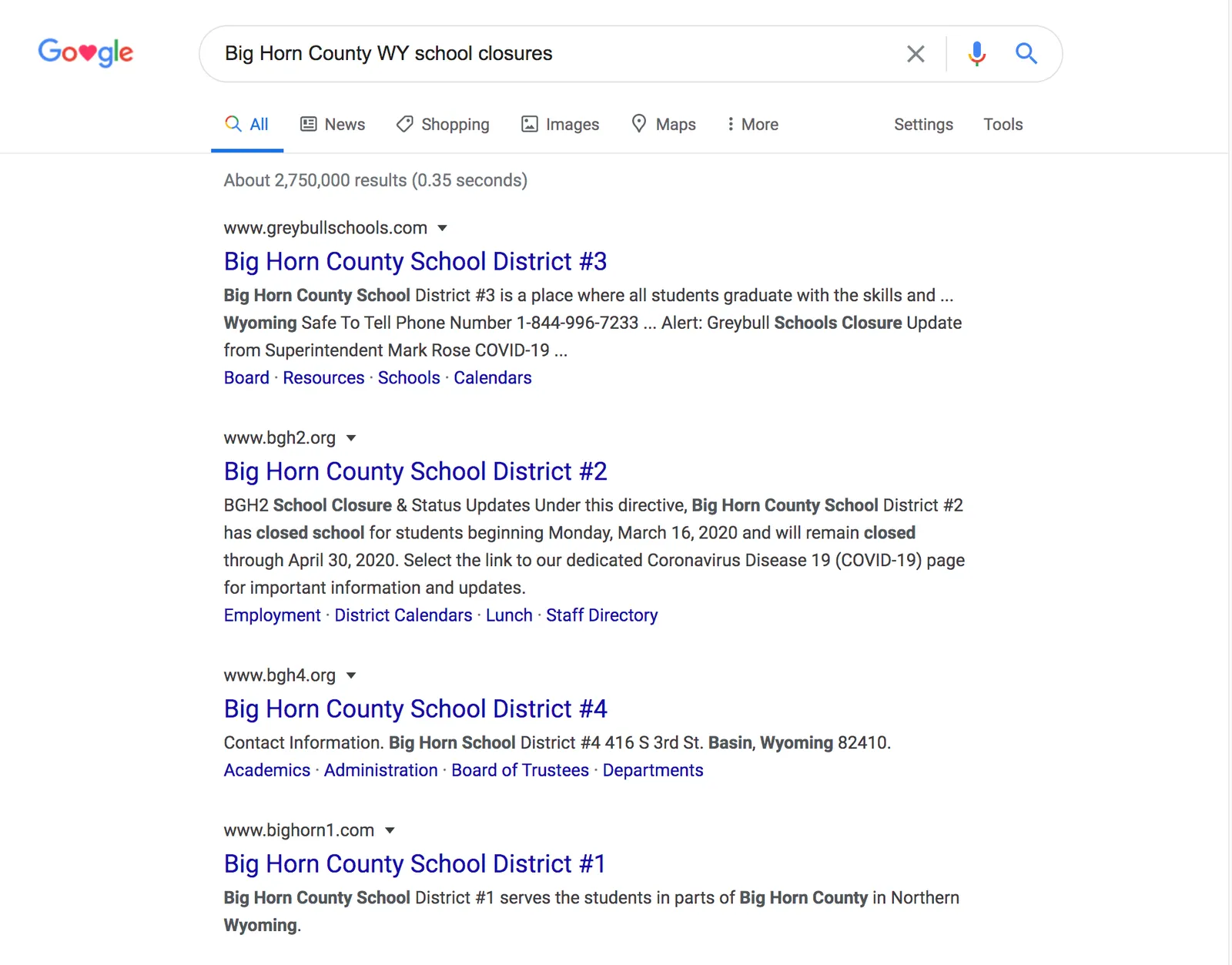
Where’s the county office of education website? Dustin, who was the first to complete his homework, was researching Wyoming and ran into this problem. Before this problem came to light in our bigger group, Dustin opened a PR with his own solution:
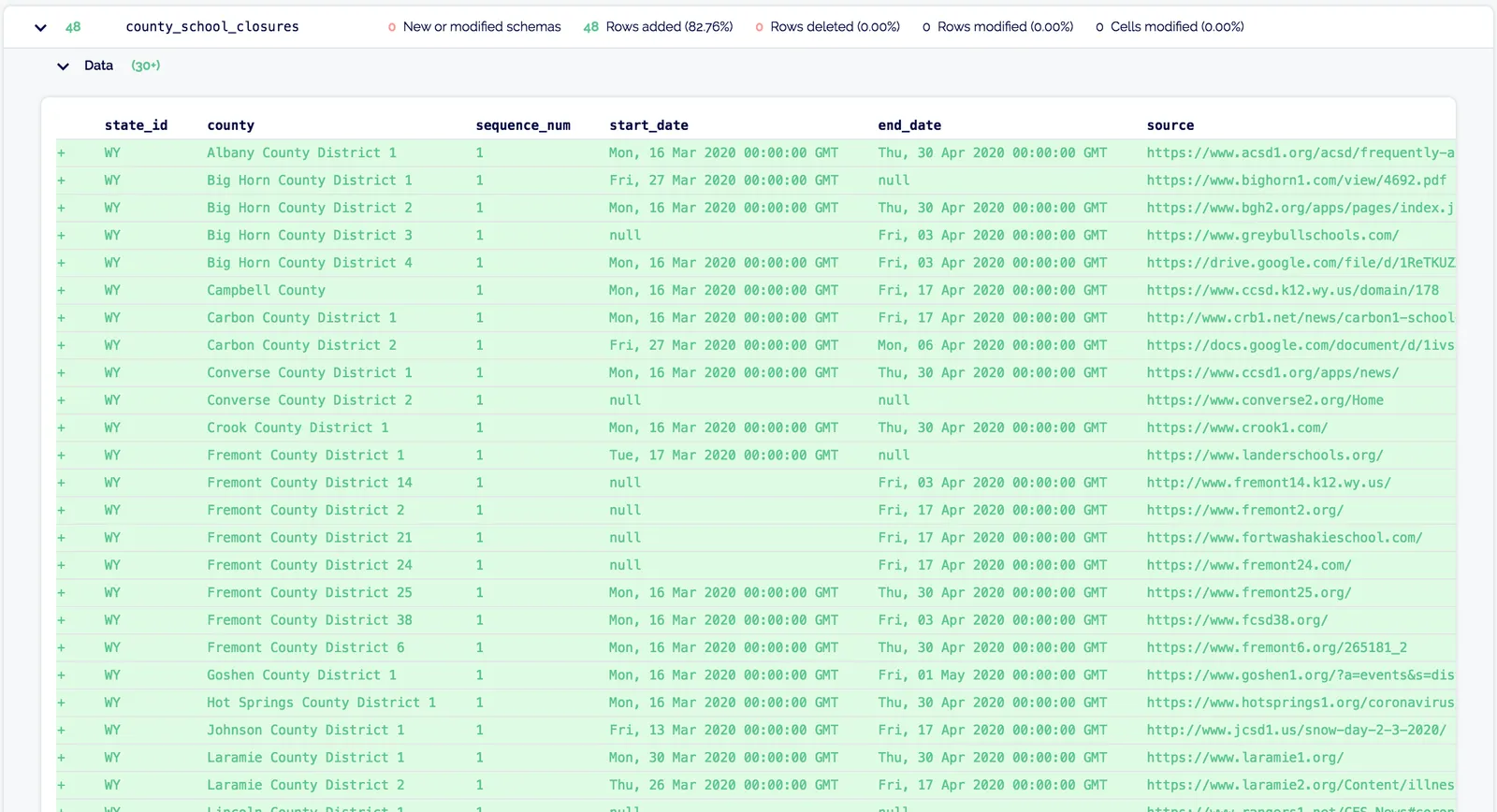
It seemed reasonable in this case to simply add a district column to this table. However, Wyoming only has 23 counties. What would it look like if I added California school closures by district?
If it took me 3 hours to go through 58 counties, it was going to take me about 50 hours to go through 977 school districts. If we wanted to track the closure start and end dates over time, this was not reasonable to do by hand. And I definitely couldn’t ask the same of the rest of the team.
Step 4: Solutions#
As more and more people worked through their homework, it became clear that counties were not going to be the most consistent level to measure school closures for every state.
Using collaboration and data review in this case was advantageous for a few reasons. For starters, it’s possible if I had been working on this project alone that I would have spent weeks going through all 50 states before someone looked at my data and told me to start over with a different schema. With many eyes and hands on this project, we came to that same conclusion in less than a day.
When you put more than one brain together to work on a problem, you come up with varied perspectives and solutions. There wasn’t necessarily a right answer for what this data should look like, but each person who did their homework came up with their own solution. Here are some examples:
- Katie found that most counties in Massachusetts closed schools when the governor mandated, and was able to use a news article as most closure date sources (see her pull request for MA here)
- Tim chose a district within each county as a reference for when the schools closed, citing the district as the
source(see his pull request for Illinois here) - Zach used Educational Service Units (ESAs) as a measurement instead of counties (see his pull request for Nebraska here)
- Aaron discovered that Hawaii has a state-wide school district, so he used those dates for all 5 counties (see his PR for Hawaii here)
- Oscar found local education agency (LEA) school closures for Missouri and suggested we use school district level information instead of county information, but also collect county/district mappings to define if all districts in a county are closed
Ultimately, we were able to take everyone’s feedback and decide as a team to go in a different direction than school closures by county. School districts, or LEAs, were more standard across states, but getting this data by hand was going to be too expensive for our 11-person team. In my search for a better solution a few days after I started this project, I found a school status updates dataset by MCH Strategic Data. We’re looking into collaborating with them, so stay tuned!
Conclusion#
Data collaboration and review is a newer concept, but we’re making it possible using pull requests on DoltHub. Getting more eyes on data only increases the data’s integrity and helps catch problems earlier, saving both time and resources.
We’re continually updating the Coronavirus state actions dataset on Dolt. If you have an idea to add school closure information or want to contribute to this dataset in any way, let us know and we can give you the permissions to open your own pull request.