
Tracking Dolt’s SQL regressions#
As part of our journey to make Dolt a great SQL database, we set out to track the correctness of Dolt’s SQL engine against a suite of SQL tests called the sqllogictests. These tests are what we use to measure how closely Dolt’s SQL engine meets conventional SQL standards, or “correctness”. Last year Dolt achieved one nine of SQL correctness based on this suite of tests. You can read more about this achievement here.
More recently, we started using these tests to benchmark how long Dolt takes to execute various SQL statements and queries, giving us insight into how well or how poorly Dolt’s SQL engine is performing. Our goal was to use these insights to detect and monitor any SQL performance regressions occurring in Dolt, as we work to improve it.
After running the test suite against Dolt’s SQL engine, we receive a log file containing the results of each test the suite contains. For our regression tracking project, we decided to focus on two key fields in these result logs. The first field, a test’s duration (measured in milliseconds), shows how long it took Dolt’s SQL engine to complete a test. The second field, a test’s result field, helps us determine the correctness of Dolt’s SQL engine.
The more tests that finish with a result of “ok”, meaning the test passed, the more correct Dolt’s SQL engine is. The shorter the duration of a test, meaning it took less time for Dolt to complete the test, the better Dolt’s SQL performance. Using our comprehensive suite of tests and corresponding result logs, we can now detect SQL regressions in Dolt.
We reasoned we could detect a regression by comparing the logs generated by a Dolt release to logs generated by nightly builds of Dolt from master. If a test’s duration changed too much between a Dolt release and a nightly build, or if a test’s result changed from “ok” to “not ok”, we’d consider these regressions and subsequently alert our dev team. We set this job up to run nightly, instead of continuously, since it takes about 4 hours to complete a single run of the sqllogictests.
Next, we set up a Dolt repository to track these regressions, then automated regression detection and alerting using our CI/CD pipeline.
Repository Workflow#
We setup a Dolt repository for tracking regressions, designed around the following workflow:

The repository has 3 branches, releases, nightly, and regressions. Test result logs from Dolt releases will be imported onto branch releases, those from Dolt nightly builds will be imported onto branch nightly, and branch regressions will be used to detect a regression between releases and nightly. The Dolt branching structure of this repo was chosen to isolate writes to produce easily readable diffs as well as to provide a logical repo structure for future collaborators.
The above illustration depicts the flow of log data into tables releases_dolt_results and nightly_dolt_results. Next, a query is run against the history of these tables to calculate the mean duration of each test. This mean data is stored in the tables releases_dolt_mean_results and nightly_dolt_mean_results. Finally, we merge all tables from branches releases and nightly into branch regressions, which will always contain the most recent versions of *_dolt_mean_results. Branch regressions also contains two view tables we’ve setup to make regression detection easy.
Automated Detection and Alerting#
As part of our CI/CD pipeline we use Jenkins. For this project, we created two Jenkins jobs to automatically update our repo and to alert us when a regression is detected. Both jobs use this bash script which defines each job’s workflow.
The first job is our release job. After we cut a new Dolt release, this job runs the sqllogictests against that release n times. After each suite run, the result data is imported into branch releases and committed. To calculate the mean duration of each test in the suite over n test runs, we run the following query against Dolt’s history table:
select
version,
test_file,
line_num,
avg(duration) as mean_duration,
result
from dolt_history_$BRANCH_NAME$_dolt_results
where
version=$DOLT_VERSION
group by test_file, line_num;This query calculates the average duration of each test. The dolt_history table makes accessing all data for a given table, across commits, very easy. To query a history table, we just added the dolt_history_ prefix to our table names.
At the time of this writing, the current Dolt version’s (0.15.2) dolt_history table implementation doesn’t distinguish between branches, so our work-around to ensure our tables’ histories are divided by branch is to prefix our table names with the branch name.
The query yields the data we store in releases_dolt_mean_results. Once this table has been updated, this job merges branch releases into branch regressions and pushes these changes to DoltHub.
The second Jenkins job we created, our nightly job, runs every night and follows the same workflow as our release job. The test suite is run n times against a nightly build of Dolt and the results data is imported and committed. The mean data is calculated by querying Dolt’s history table, and branches nightly and regressions are updated with their changes pushed to DoltHub.
This job, however, is also responsible for querying the views on regressions. Those views will return rows only if a regression has occurred, which will cause this job to fail and our dev team to be alerted. These are the view definitions:
create view `releases_nightly_duration_change`
as
select *
from
(
select
r.test_file,
r.version as release_version,
sum(r.mean_duration) as release_mean_duration_sum_ms,
n.version as nightly_build,
sum(n.mean_duration) as nightly_mean_duration_sum_ms,
(100.0 * (cast(sum(r.mean_duration) as decimal(48, 16)) -
cast(sum(n.mean_duration) as decimal(48, 16))) /
(cast((sum(r.mean_duration)) as decimal(48, 16)) + .00001)) as percent_change
from releases_dolt_mean_results as r
join nightly_dolt_mean_results as n
on r.test_file = n.test_file and r.line_num = n.line_num
)
as wrapped where percent_change < -5.0;
create view `releases_nightly_result_change`
as
select
r.test_file,
r.line_num,
r.version as release_version,
r.result as release_result,
n.version as nightly_build,
n.result as nightly_result
from releases_dolt_mean_results as r
join nightly_dolt_mean_results as n
on r.line_num = n.line_num
and r.test_file = n.test_file
and (r.result = "ok" and n.result != "ok");The first view, called releases_nightly_duration_change, detects if a duration regression of greater that 5% has occurred. The second view, releases_nightly_result_change, detects if a result regression has occurred. In our nightly job, we query these views and save the output in variables:
duration_query_output=`sqlite3 regressions_db 'select * from releases_nightly_duration_change'`
result_query_output=`sqlite3 regressions_db 'select * from releases_nightly_result_change'`As you can see, we actually execute these queries using sqlite3 despite our Dolt repo being set up to execute them. At the time of this writing, Dolt’s SQL engine isn’t fast enough to execute these queries in our nightly job, but as we continue to improve Dolt, it will get there. In the meantime, we installed sqlite3 as a temporary work-around for this job, and we will swap it out with Dolt at a later date.
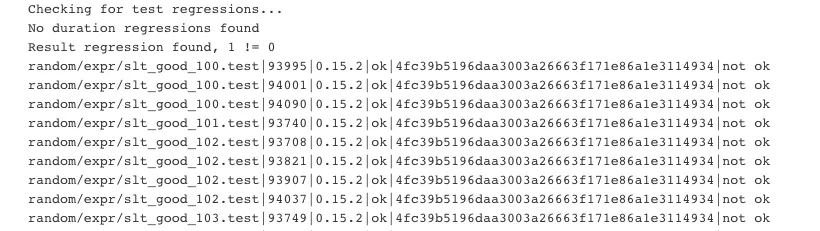
If a regression ever occurs in our nightly job we log the regression information in Jenkins, and it looks like this:
Conclusion#
We now have a fully automated SQL regressions monitoring pipeline setup for Dolt. This project is also one of our first internal production uses of Dolt and we are excited to explore more ways to use Dolt within our own production environments. We also believe dogfooding our product is one of the best ways to encounter bugs and customer pain points, so we can address them early.
The Dolt repo used for this project is publicly available so anyone can clone it and inspect the data. As of today (April 6th, 2020) we are in the process of adding the sqllogictest results for our current Dolt release, but this repo already contains data for releases 0.14.0 - 0.15.1. Tonight we are also kicking off our first nightly job. We continue to make Dolt better each day and as we do it’s value and utility only becomes more obvious. Thanks for reading!