
![]()
DumboDB is a document database inspired by MongoDB, built on top of Dolt’s storage. DumboDB combines the flexibility of a document database with the power of Git-like version control, allowing you to track changes, branch, and merge your data with ease.
It’s early days for DumboDB, but thanks to leveraging Dolt’s underlying architecture, we’re able to rapidly iterate and add new features. In release 0.1.3, we’re excited to announce the addition of garbage collection (GC) to DumboDB!
What is Garbage Collection?#
In many databases, as you update your data on disk, old versions of your data will accumulate over time. Cleaning up this data goes by many names. In PostgreSQL, it’s called VACUUM. In MySQL, it’s called purging. In Dolt, it’s called garbage collection.
In traditional databases, it makes sense that garbage would exist. When you update a row in a table, the old version of that row is still on disk until the database decides to clean it up.
Dolt and Dumbo are version-controlled databases, so it’s reasonable to assume we store every version of the data forever. Unfortunately, it’s not that simple. Dolt and Dumbo keep track of all committed data, specifically data that has been committed to the database and is part of the commit history.
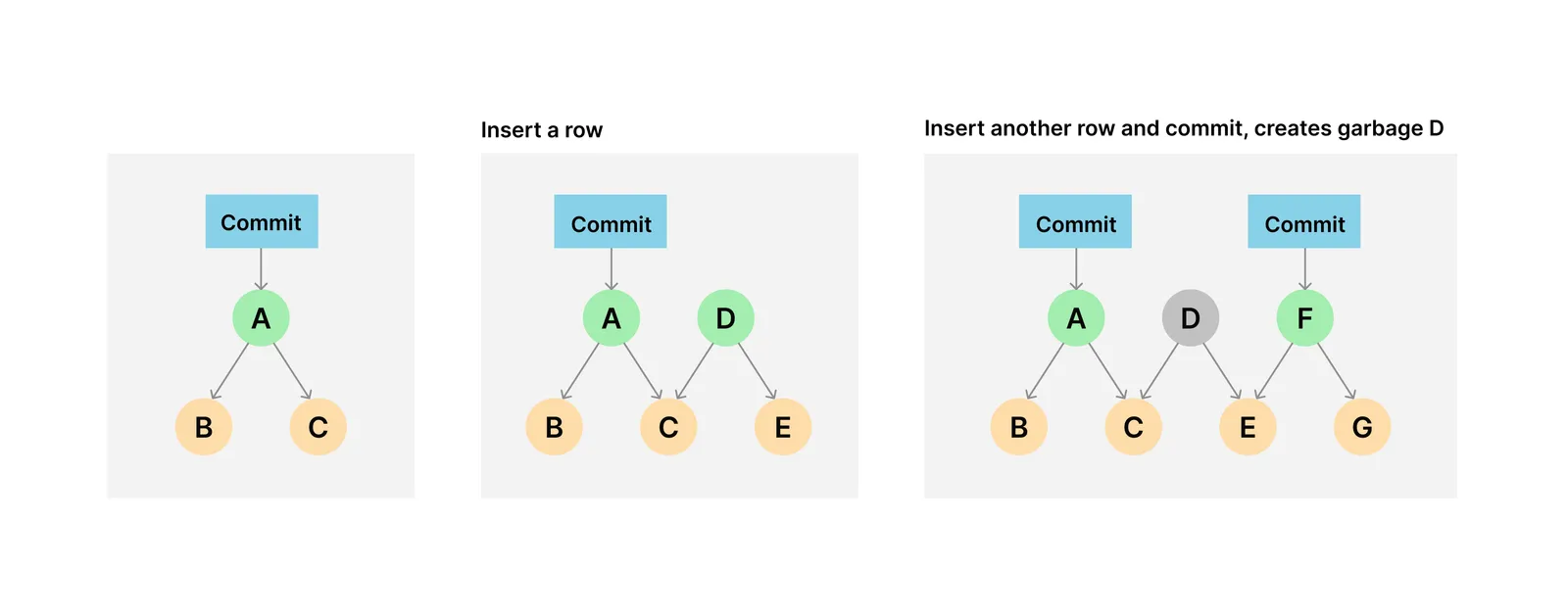
In scenarios where you insert or update many documents, there are intermediate versions of the data that are not committed to the commit history. These intermediate versions take up disk space and may not be necessary to keep around indefinitely. This is where garbage collection comes in.
How Does Dumbo’s Garbage Collection Work?#
The short answer is that it’s just like Dolt’s Session Aware GC.
I won’t go into that level of detail here, but at a high level, every chunk of data in a Dolt (and Dumbo) database must be reachable from the commit history of all branches. We build a list of all chunks in the database, then walk the commit history to find all chunks that are reachable from commits. Any chunks that are not reachable from the commit history are considered garbage and can be safely deleted.
This becomes more complicated when you consider that there may be active sessions in the database that are still using some of the intermediate versions of the data. We don’t want to delete any chunks that are still being used by active sessions, so we need to keep track of those as well.
Dolt’s GC process takes this into account by keeping track of the active sessions and ensuring that any chunks that are still being used by those sessions are not deleted during the GC process. This allows us to safely clean up any garbage data without affecting any active operations in the database.
DumboDB uses the same storage engine as Dolt, so we were able to leverage the existing GC implementation in Dolt to add GC support to DumboDB. This means that DumboDB can now automatically clean up any garbage data that may be taking up space on disk, without affecting any active sessions or operations in the database.
Using Garbage Collection in DumboDB#
Garbage collection has been added in the latest release of DumboDB.
Be sure that the mongo driver is installed for Python:
pip install pymongoThen create a script that creates a bunch of garbage chunks. Put this text in a file called make_garbage.py:
import random
import secrets
from pymongo import MongoClient
client = MongoClient("mongodb://127.0.0.1:27017")
db = client["gcdemo"]
coll = db["items"]
for b in range(50):
docs = []
for i in range(100):
docs.append({
"_id": f"b{b}-d{i}-{secrets.token_hex(4)}",
"name": f"user-{secrets.token_hex(3)}",
"email": f"{secrets.token_hex(4)}@example.com",
"age": random.randint(18, 80),
"score": random.random() * 100,
})
coll.insert_many(docs)
db.command({"dumboCommit": 1, "message": f"batch {b}", "author": "gcdemo <gcdemo@example.com>"})
print(f"batch {b + 1}/50 committed")
client.close()This script creates 50 commits, each with 100 new random documents. As a result, it creates a lot of intermediate data versions that are not committed to the commit history and are therefore considered garbage. Run the script:
$ python make_garbage.py
batch 1/50 committed
batch 2/50 committed
[... snip ...]
batch 49/50 committed
batch 50/50 committedIn another file, run_gc.py, add the following code to trigger the GC process:
from pprint import pprint
from pymongo import MongoClient
client = MongoClient("mongodb://127.0.0.1:27017")
res = client["gcdemo"].command({"dumboGC": 1})
pprint(dict(res))
client.close()When you run this script, it will trigger the GC process in DumboDB and print out the results:
$ python run_gc.py
{'chunksAfter': 6608.0,
'chunksBefore': 7119.0,
'db': 'gcdemo',
'durationMs': 163.0,
'mode': 'default',
'ok': 1.0,
'sizeAfter': 5929327.0,
'sizeBefore': 7452156.0}The command returns statistics about the number of chunks before and after the GC process, the database size before and after, and how long the GC process took to run.
Comparison to Dolt#
One of the reasons I wanted to add GC to DumboDB is to see how Dumbo’s storage usage compares to Dolt’s. I added parity tests to generate equivalent data in both Dolt and Dumbo, then ran GC on both databases to see how much space was used for each.
The results aren’t fantastic, I’m not gonna lie. There is clearly something amiss. When storing about 1M documents, Dumbo is using about 6x the amount of space after GC compared to Dolt.
It’s not clear yet if this is the result of a bug in how Dumbo stores data or if we are being too conservative when we garbage collect. As we discussed in a previous post, this kind of side-by-side comparison is one of the main ways we can verify that a vibe-coded product such as Dumbo is working correctly. My gut says that we should have collected more data in our example and we are being too conservative. We will be investigating this issue in the coming weeks and will share our findings in a future blog post.
What’s Next?#
Sorting out the storage discrepancy just mentioned is the top priority. After we sort that out, automatic garbage collection is the next step. Similar to Dolt, when the server determines that there is a reasonable amount of garbage data that can be cleaned up, it will automatically trigger the GC process. This will help ensure that your DumboDB instance stays clean and efficient without requiring manual intervention.
Want to learn more about Dolt and Dumbo? Hop on our Discord to ask questions and nerd out about version-controlled databases!