
AI agents are hot right now. Every week, billions of dollars are being poured into tools like Claude Code and Cursor Agent or app builders like Replit and v0. This is representative of a broader trend towards making AI actually do things beyond just text generation. It does appear, however, that the most sophisticated agentic systems (or at least the ones with the most funding and users) are those built for writing code.
That feels counterintuitive to me. Writing and integrating working code into a complicated codebase should be a harder task than making changes to a spreadsheet, or responding to support tickets, or managing a CRM, yet the agent-equivalents in these domains are far weaker. The reason for this is not because AI is “better” at generating code than it is at generating anything else. It’s because code is under version control. Code can compile. Code has tests.
To explain what I mean, I want to walk through a simple application with some agentic features, backed by a Dolt database. Dolt is a version-controlled SQL database. It gives you access to all the standard Git operations (branch, commit, merge, revert, etc.), but it operates on database tables rather than text files. Using Dolt, you can bring version control to anything. In this article, I’ll explain why that unlocks so much potential for agents in domains outside of code.
The Generative Step and the Operational Step#
Before getting into the benefits of version control, I want to make a distinction between the two types of actions taken by any agentic system: the generative step and the operational step.
-
The Generative Step - This is where the model reasons about the user’s query and produces something to address it. In the case of coding agents, for example, given an arbitrary natural language query like “fix this bug”, the generative step comes up with code that (hopefully) fixes it. This is reliant on the generalized knowledge of the model.
-
The Operational Step - This is where the agent takes some tangible action based on the conclusion drawn from the generative step. Unlike the generative step, the actions the model chooses to take here are generally things that a user (or application code) would be able to do on their own. Given the code that fixes a bug, for instance, I could very easily integrate that code into my codebase, compile it, and run tests myself.
The vast majority of applications that use AI have the generative step, but lack the operational one. For truly agentic systems to work, you must have both. My contention is that you cannot have both without version control.
Why Version Control Is Necessary#
Allowing agents to perform the operational step introduces nondeterminism into your application. If you let an agent do real work, you can no longer make hard guarantees about state or behavior. Version control introduces an explicit way to reason about this nondeterminism. Specifically, it enables:
- Committing - Every change an agent makes must be auditable and reversible.
- Branching - For agents to do real work, they need access to isolated, reproducible environments where they can operate without affecting the production system. A branch gives the agent a private workspace.
- Diffing - It must be immediately clear what an agent did. Diffs reveal exactly what changed after the operational step.
- Merging - If you need branches and diffs to safely handle the case where the agent is wrong, you need merges to handle the case where its right. There must be some controlled mechanism for applying the changes made on an agent branch to a production branch.
Together, the above operations preserve predictability, a trait that agents on their own inherently lack.
Blame Is Important#
Version control doesn’t just allow agents to operate safely and reliably, it also improves quality. If you use a coding agent, force push without review, and break production, that mistake belongs to you, not the agent. As much as we may like to claim that it was the agent’s fault, it was ultimately your decision to approve the changes. The act of pressing “Approve” offloads the blame from the agent to the human. That’s why pull-request-style workflows are essential for agentic systems. This transfer of accountability functions as quality assurance, and it’s made possible by branch, diff, and merge.
Why Are Coding Agents Better Than Other Agents?#
This is a question I see often, and the answer almost always boils down to the following:
- LLMs are trained on text.
- Code is text.
- There exists a near-infinite supply of code samples available for training.
My issue with this argument is that it only answers half the question. It offers a reasonable explanation for why coding agents are good at the generative task of producing code, but not why they outperform in the operational sense, where they modify, execute, and manage code within real systems.
Tools like Claude Code do both. The generative action is the model reasoning about the user’s query, then producing code that addresses it. The operational step may involve writing to the filesystem, compiling code, running test suites, fixing bugs, etc. So, then, why are coding agents better at the operational step? Well, they aren’t. The difference is that they operate in an environment where it’s okay to be wrong.
If you don’t like the changes the agent made, you revert instantly. If you want to allow the agent to work unimpeded, create a new branch and let it run free. Come back later and you have a clear diff and the ability to merge automatically. There is virtually zero risk associated with an agent working on code for you.
Coding agents frequently hallucinate, spit out entirely incorrect code, then loudly proclaim that they fixed your issues. They are undoubtedly useful tools, but the reason they’re seeing such widespread adoption relative to other agentic tools is certainly not because they produce perfect code. It’s because incorrect output doesn’t result in catastrophe. Claude Code and its peers were born into an ecosystem that already had version control baked in. In order for other domains to catch up, the agentic systems that operate on them must adopt similar foundations.
Dolt Lists#
Now that I’ve made my case for version control, let’s talk about what that actually looks like in a real application. I built a simple list app, where users can create lists and add or delete items. The “agentic” feature comes from a chat interface that allows you to prompt the agent to make changes to your list. This is done using the Claude API paired with a Dolt MCP server. After the changes are made, the diff is displayed and users have the option to accept or reject the agent’s changes.
This is the main user interface:
Lists are stored in a Dolt database, and there’s a simple backend API for handling updates. Let’s show off something more interesting.
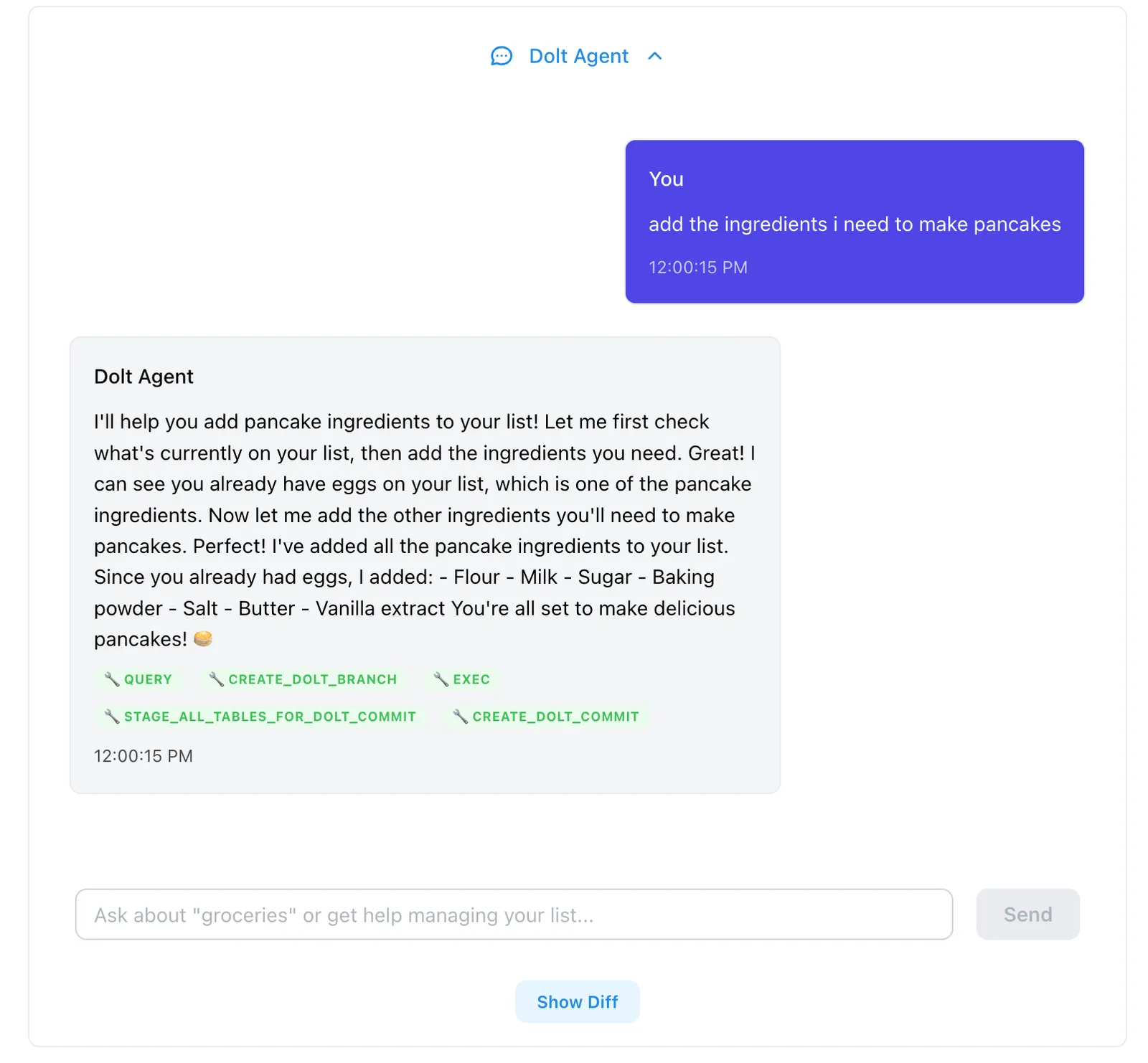
The chat interface allows you to prompt the agent to do something with your list. In this example, I asked it to add the ingredients for pancakes. Let’s see what it came up with.
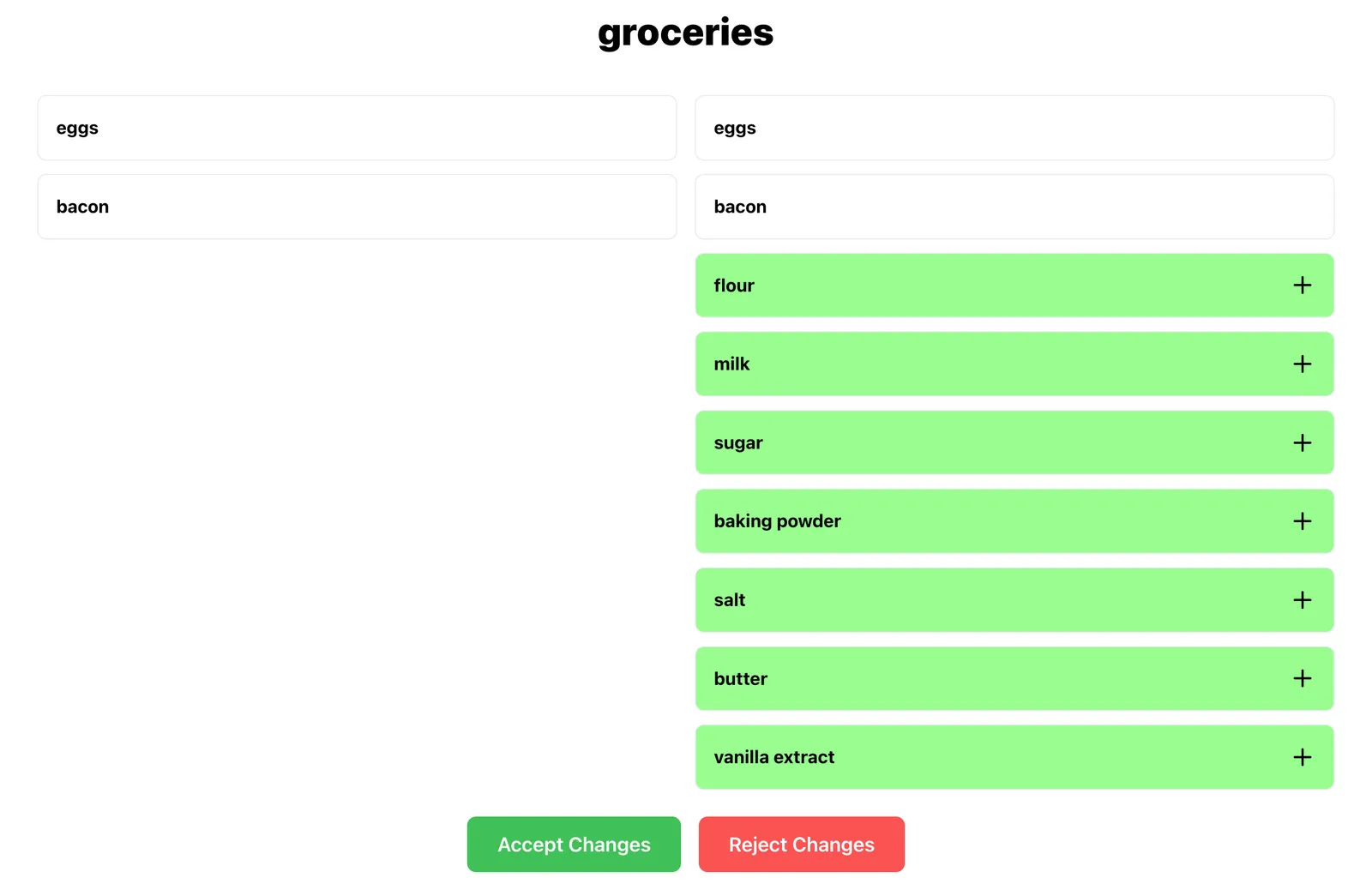
That seems reasonable to me. After I accept the changes, the new items will officially be added to my list. Additionally, I can have multiple conversations going at the same time, all of which are persisted.
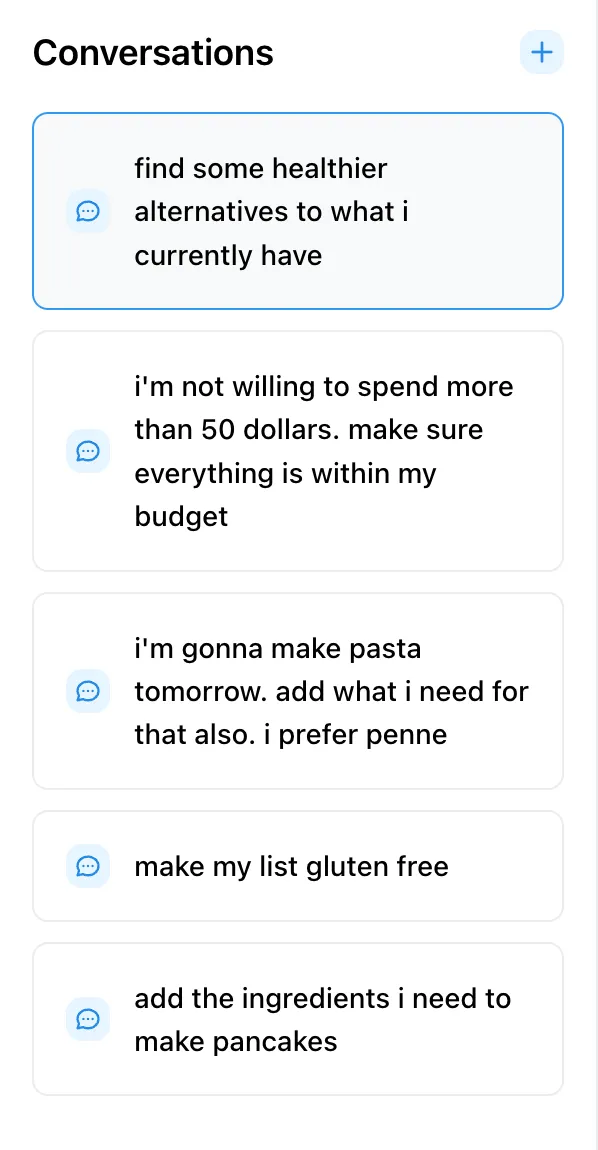
Different conversations might correspond to different changes to my list. If I switch to a different conversation, I can immediately see the changes the agent made as a result of that conversation. For instance, this is what I see after selecting the conversation where I asked it to make my list gluten-free.
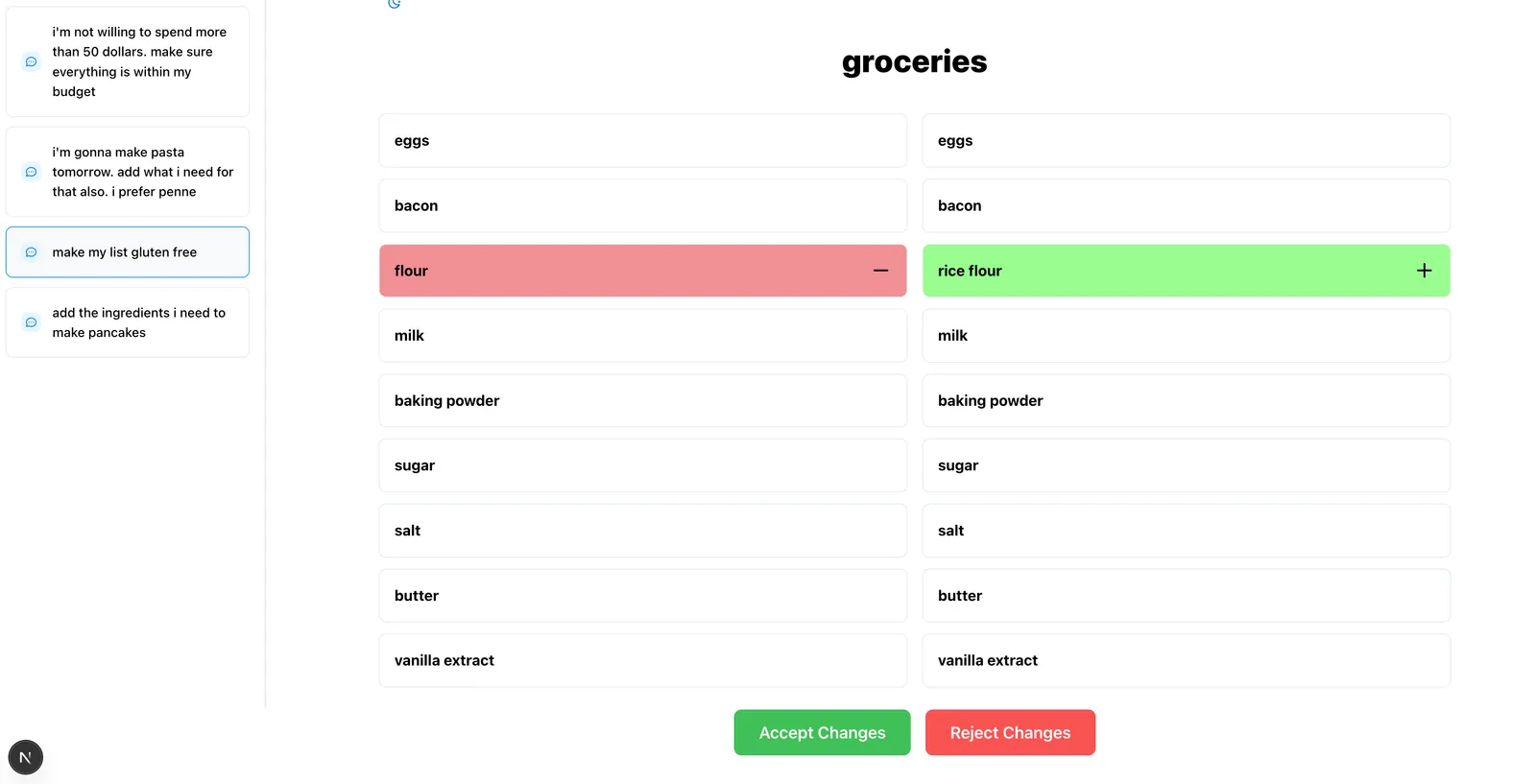
If you’re not familiar with Dolt, you might have a few different ideas about how this works. Maybe there’s a shadow table where the agent writes its proposed edits. Maybe there’s some flag that marks “pending” versus “approved” rows. Such approaches are plausible for an application as simple as this one, but they come with significant risk. If I had a proposed_edits table, any agent run would be writing to a table that stored all other agent edits. You would need a separate shadow table for every agent run to achieve real write isolation. With a “pending/approved” flag, you run into the same issue.
These sorts of problems, among others, are why most database MCP servers disallow writes by default. It is simply too great a risk to give an agent the ability to modify production data. Dolt eliminates that risk by introducing version control at the data layer.
How it Works#
Let’s first discuss the data models. These are the table schemas:
CREATE TABLE `lists` (
`name` varchar(255) NOT NULL,
PRIMARY KEY (`name`)
)
CREATE TABLE `list_items` (
`id` int NOT NULL AUTO_INCREMENT,
`item` text NOT NULL,
PRIMARY KEY (`id`)
)There are no foreign key relationships here at all. This is achieved using branches. Every list lives on its own branch, and the main branch just holds the table definitions. When a user creates a new list, we create a new branch off of main, resulting in an empty list_items table. This allows us to completely isolate the list data to a branch. When items are modified, those edits only happen on the branch. We call this the customer-per-branch pattern.
So, what happens when you ask the agent to make changes? This is the sequence of events taken by the agent:
- Reads data from the user’s branch.
- Determines what action to take (add items, remove items, update items, etc.).
- Creates a new branch off of the user’s branch, let’s call it
agent_branch. - Applies its changes on
agent_branch. - Commits its changes on
agent_branch.
At no point does the agent ever modify data on the user’s list branch. Instead, it reads from the user’s branch and writes to its own branch via the Dolt MCP server. For example, this is my branch on the left and the agent’s branch on the right after asking it to add pancake ingredients to my list:
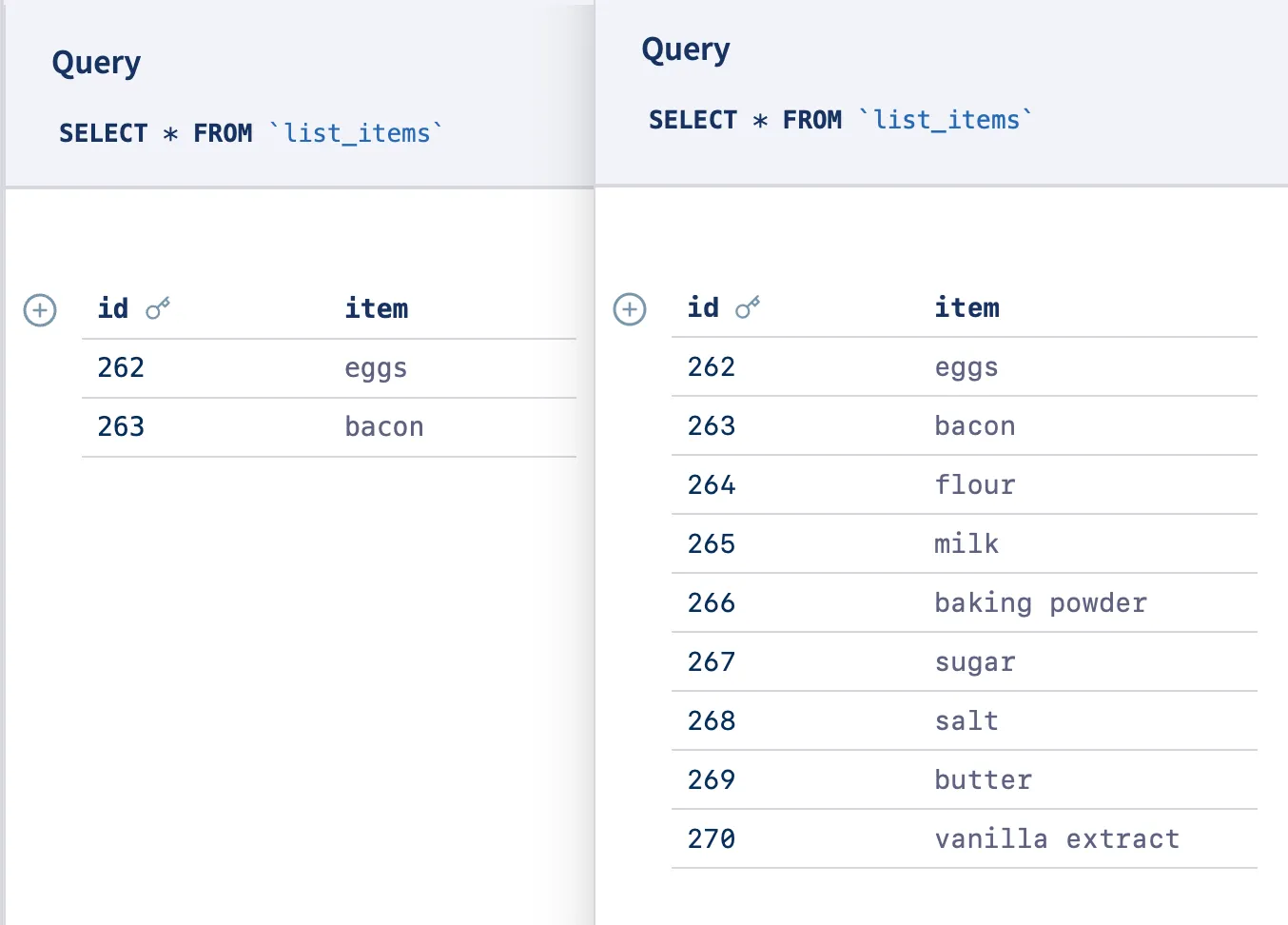
Now I have two branches, one containing my original list items and one with the agent’s edits. How do I know what changed?
SELECT from_item, to_item, diff_type FROM DOLT_DIFF('my_branch', 'agent_branch', 'list_items');
+-----------+-----------------+-----------+
| from_item | to_item | diff_type |
+-----------+-----------------+-----------+
| NULL | flour | added |
| NULL | milk | added |
| NULL | baking powder | added |
| NULL | sugar | added |
| NULL | salt | added |
| NULL | butter | added |
| NULL | vanilla extract | added |
+-----------+-----------------+-----------+
7 rows in set (0.00 sec)In Dolt, diffs are fast. There are no manual diff calculations happening here. In fact, Dolt computes diffs in time proportional to the size of the diff, not the total size of the data. If you’re curious about how that’s possible, check out this blog about the Dolt storage engine.
So, we have two branches, and we have the ability to quickly see what changed between them. How do we merge the two together?
CALL DOLT_MERGE('agent_branch')Again, a native Dolt operation that hinges on fast diffs. When you hit the “Accept Changes” button, this is what’s running under the hood. The changes made on the agent’s branch are immediately applied to your branch. You can have an arbitrary number of agents working on different, isolated branches that all point back to the same base.
It’s also worth mentioning that any write to a table results in a Dolt commit. Dolt commits work the same as Git commits. This means that auditability is built into the application by default, and that you can revert any commit at any time. This is especially powerful here because our data is isolated to branches. If any unwanted changes make it into a list branch, you don’t have to roll back the entire database state. Instead, you get immediate point-in-time recovery for just that branch.
Conclusion#
Version control is the missing ingredient in agentic applications outside of code. The “Dolt Lists” app was a simple experiment aimed at highlighting how version control allows agents to operate autonomously without sacrificing predictability and reliability. Without version control, agents can either act recklessly or not act at all.
Dolt is the only database where version control operations are primitives. If you’re building an agentic system and want it to do real work, give Dolt a try. Come by our Discord with any questions about Dolt, version control, or agents.