
Here at DoltHub, we have immense respect for fellow Canadian and former Head of Self Driving at Tesla, Andrej Karpathy. Andrej’s computer vision and artificial intelligence opinions and teachings are stuff of legend. He’s currently working on an education crossed with artificial intelligence startup called Eureka.
Going all the way back to 2017, Andrej’s Software 2.0 blog article was one of the original inspirations for Dolt and DoltHub.
Is there space for a Software 2.0 Github? In this case repositories are datasets and commits are made up of additions and edits of the labels.
That’s a pretty good description of the data sharing for training data use case for Dolt and DoltHub.
In 2023, as ChatGPT was just reaching mass market fame, Andrej’s NanoGPT was the best way to learn how to train a language model. I wrote a detailed article about how to use it. Andrej has a knack for distilling complex technical topics down to their essence.
Last Monday, Andrej was on the Dwarkesh Podcast for a wide ranging conversation on artificial intelligence. One particular section caught our attention.

Andrej thinks agents need diffs! Frankly, I’m kind of sad he beat me to this take.
I’ve said all of the following. Agents need branches. Agents need tests. Agents need clones. But somehow, I hadn’t gotten to agents need diffs.
Let’s just settle on agents need version control. Dolt brings version control to everything that isn’t files. Once again, Andrej is inspiring us.
The Setup#
Andrej is a legend in the artificial intelligence community. He was on the founding team at Open AI and then moved to Tesla in 2017 to focus on self driving where he became one of the world’s leading experts in computer vision. He went back to Open AI for a short stint in 2023 before starting his latest venture, Eureka.
Thus, Dwarkesh is very interested in Andrej’s takes on Artificial General Intelligence or AGI and the process by which that may be achieved. Andrej is a bit of a realist when it comes to AI, having been in the trenches for over a decade. Andrej unleashes a few takes, the most memorable being “I said we’re not building animals. We’re building ghosts or spirits.”
Eventually, Andrej and Dwarkesh start discussing why coding agents work so well which gets to the following point.
The Conversation#
Dwarkesh tees up Andrej with the following lead in.
It’s very much like programmers are getting more and more chiseled away at their work. If you look at the revenues of these companies, discounting normal chat revenue—which is similar to Google or something—just looking at API revenues, it’s dominated by coding. So this thing which is “general”, which should be able to do any knowledge work, is just overwhelmingly doing only coding. It’s a surprising way that you would expect the AGI to be deployed.
And Andrej responds.
There’s an interesting point here. I do believe coding is the perfect first thing for these LLMs and agents. That’s because coding has always fundamentally worked around text. It’s computer terminals and text, and everything is based around text. LLMs, the way they’re trained on the Internet, love text. They’re perfect text processors, and there’s all this data out there. It’s a perfect fit.
We also have a lot of infrastructure pre-built for handling code and text. For example, we have Visual Studio Code or your favorite IDE showing you code, and an agent can plug into that. If an agent has a diff where it made some change, we suddenly have all this code already that shows all the differences to a code base using a diff. It’s almost like we’ve pre-built a lot of the infrastructure for code.
Contrast that with some of the things that don’t enjoy that at all. As an example, there are people trying to build automation not for coding, but for slides. I saw a company doing slides. That’s much, much harder. The reason it’s much harder is because slides are not text. Slides are little graphics, they’re arranged spatially, and there’s a visual component to it. Slides don’t have this pre-built infrastructure. For example, if an agent is to make a change to your slides, how does a thing show you the diff? How do you see the diff? There’s nothing that shows diffs for slides. Someone has to build it. Some of these things are not amenable to AIs as they are, which are text processors, and code surprisingly is.
Agents Need Diffs#
Andrej is making a specific point about diff here. In order for agents to work, you need to be able to show the human operator what changed. He contrasts agents writing code with agents making slides. In the realm of code, the diff is available via Git or any other version control system. In the realm of slides, the diff is not available. So, Andrej’s contention is that diff for slides is a pre-requisite to having an agent produce slides.
This implies a much broader claim that agentic workflows require “human in the loop” review. Agents cannot solve every problem correctly on the first try. Agents should propose solutions for humans to review before accepting.
There is a broader point here that in order to provide “human in the loop” at scale, you need all of Git’s version control functionality: clones, branches, merge, and diff. I think Andrej is using diff as a shorthand for version control in general. This is reinforced when he says, “It’s almost like we’ve pre-built a lot of the infrastructure for code”. I think he is referring to Integrated Development Environments (IDEs) and version control systems like Git.
Dolt and Diffs#
For those of you unfamiliar with Dolt. Dolt is the world’s first version controlled SQL database. It’s the only database with branches. Dolt provides Git-style version control functionality to database tables instead of files including diff. Diff in particular is fast based on the Dolt’s novel storage format.
In Andrej’s slides example, if the team was able to represent a slide deck as structured data, Dolt could produce the diff between two versions of that structured data at scale, quickly. Slides aren’t the ideal Dolt example but any application backed by a SQL database is. Move your backend database to Dolt and your application is agent-ready, complete with diff for human review.
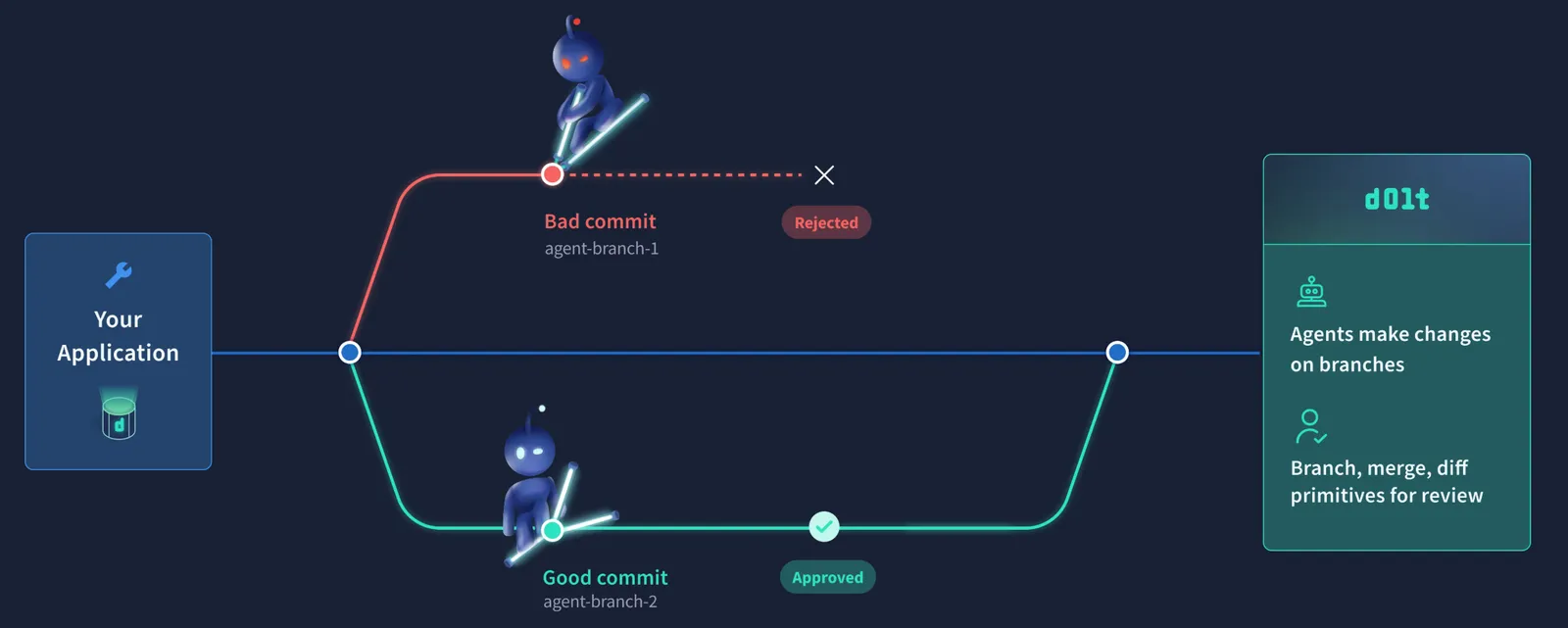
Conclusion#
Andrej Karpathy has been inspiring us here at DoltHub coming on a decade. I’m not even sure he knows Dolt exists. If you know him, send him this article. Make sure to come by our Discord to tell us you did.