
Dolt is the world’s first SQL database with Git-style version control. It is a distributed database that allows you to clone, branch, and merge databases just like you would with code.
And it’s Open Source! You can find the source code on GitHub.
One of the great benefits of being open source is that we don’t really have any secrets, and so we can share every little detail of how Dolt works through our blog and documentation.
The “Conjoin” process is one such detail which we’ve never really talked about before. Not because it’s off limits, but simply because it’s not something that is publicly visible in the product at all.
So, what is Conjoin, why do we do it, and how does it work? Let’s dive in!
Searching for Chunks#
Dolt’s data is stored in files on disk or in the cloud. I’ve written about this before, but to summarize, we have a binary format that stores many small content-addressed pieces of data, called “chunks”. Every aspect of your data is stored in these chunks, including the schema, the data itself, all your indexes, and all history.
Storage files can be anywhere from a few kilobytes to many gigabytes in size—even tested up to a terabyte! And these files are immutable, meaning that once they are written, they cannot be updated. The chunks within the files are about 4Kb in size, so there are typically many chunks in each storage file.
In order to perform fast operations in Dolt, we need to be able to quickly find many chunks and retrieve them from storage. To do this, we maintain an “index” which is a mapping of chunk hashes to their location in the storage file. Every storage file has its own index, and just to be complete there is an additional “footer” at the end of the file as well which we don’t need to mention for today’s discussion.

You can read more about the index elsewhere, but the important thing to know is that using the index to find a chunk performs a binary search, which is O(log n) in complexity. For those who haven’t thought about this in a while, O(log n) is considered a fast operation.
We’ve arrived at the crux of the problem. If we need to find a chunk in a database with 1,000 storage files, we need to search through 1,000 indexes. While each index is fast, searching through 1,000 of them is not. Stated in a mathy way:
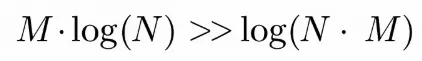
This is where Conjoin comes in.
What is Conjoin?#
Conjoin is a process that Dolt runs to combine storage files and their indexes into a single storage file. This process is designed to improve the performance of Dolt by reducing the number of storage file indexes that need to be searched when looking for a chunk. Conjoin takes any number of storage files and combines them into one.
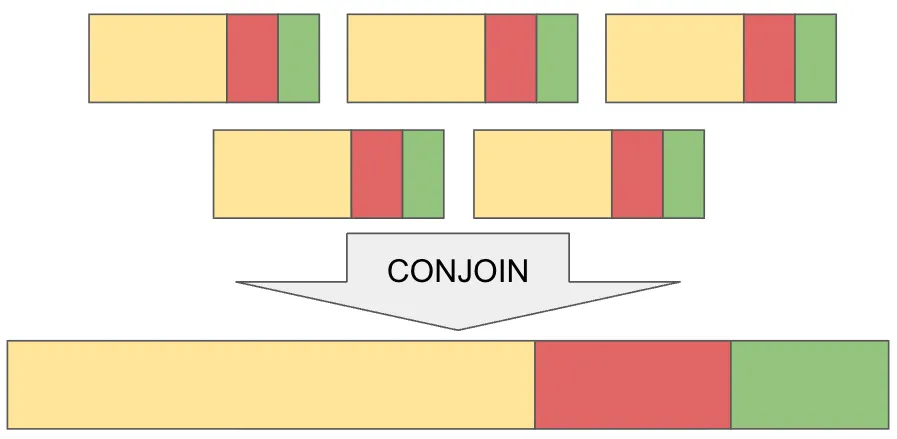
You’ve never heard about this because conjoins are performed as part of garbage collection, and the user has no idea it’s even happening. When garbage collection is executed, either manually or automatically, Dolt will determine if there are too many storage files and conjoin will be executed if so.
If you want to witness conjoin happening, do the following 256 times:
- Insert some data into a table
- Commit the change
- Run
dolt gcorcall dolt_gc()in a sql context. - Count the number of files in your dolt data directory:
find .dolt -type f | wc -l
Each time you do this, the number of files will increase by one. On the 256th time, you will see the number of files drop significantly. This is the conjoin process in action.
Why Do We Conjoin?#
Hopefully it’s obvious by now that the reason we conjoin is to maintain fast performance. By reducing the number of storage files and indexes, we can speed up chunk retrieval which makes Dolt faster overall. By having a small number of larger indexes to search we maintain our fast O(log n) search time. Remember that a single query can require thousands of chunk lookups, so reducing the number of lookups is critical to maintaining performance.
How Does Conjoin Work?#
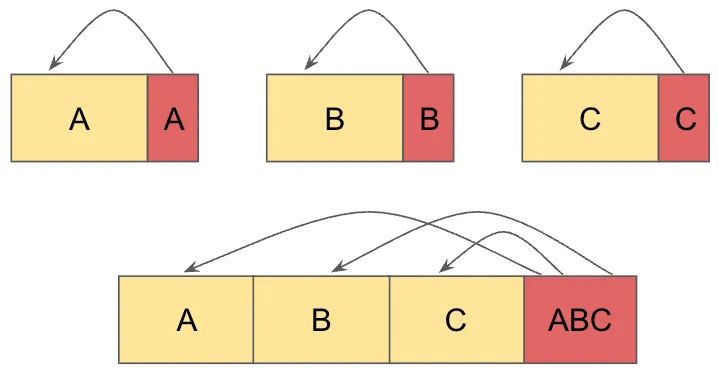
In principle, a conjoin is a simple process. We need to concatenate the data blocks of the storage files together, then generate a new index for the combined data. The generation of the new index is conceptually simple—each index entry states the offset into the data section, so as you add in new data you simply record the new offset. There is the matter of re-sorting the entries in the index so that the binary search continues to work, but all in all not a big deal.
However, when I first looked at how conjoin works to add support for Archives, Tim shook his head and said “Conjoin means bugs.” Apparently we’ve been burned by this area of code enough times to permanently scar him.
There are a few factors that make conjoin a bit more complex than it seems at first glance. First, this is one of the few places in Dolt where we swap out storage files, which effectively means the storage system is mutable. Most regular writes to Dolt go into a journal, and only after we’ve garbage collected do we perform an atomic update to the entire storage system. Furthermore, we need to garbage collect 256 times before we even get to the point where conjoin is executed, so it’s a critical code path which gets executed much less frequently.
There is also the matter of cloud. Concatenating bytes on a local disk is pretty easy, but when your target is S3 or Google Cloud Storage, you are much more limited in what you can do. Both S3 and GCS have APIs that allow you to append to an object in storage, but they are both different from each other and don’t look anything like a local file system. Our internal interfaces do a pretty good job of abstracting this away, but every abstraction is a potential source of bugs. What seems like a simple concept blossoms into an implementation for every backend we support, so it becomes a large fan-out of cases to test and validate.
Finally, Tim may have been traumatized by Conjoin because it’s potentially so dangerous. Bugs in the past which rendered a database corrupt leave a strong impression because one of the most important things for a database to do is store your data without corrupting it. Table stakes! I wouldn’t blame a user for throwing their Dolt instance out the window if we corrupt their data, and neither should you. So while we haven’t had any instances of lost data, we’d like to keep it that way.
Why Are We Talking About This?#
Conjoin, as it exists today, has had a lot of time for us to “bake” it and we are confident that it works. Why would I stir the pot and generate all of this concern over issues we’ve already worked through in the distant past? Heck, I’ve worked on this product for two years, and there hasn’t been a single conjoin bug!
The reason is I’m currently working on the next generation of our storage format, called Archives. The format has existed for more than a year, and the conjoin process is the last big item to finish before we start making it the default format. Looking at our history has motivated me to avoid the mistakes of the past and ensure that Tim gets over his trauma of “Conjoin means bugs.”
As an engineer, it’s important to respect what came before and to avoid the trap of new shiny things. I’m doing my legwork to understand the scope of the space so I ensure that Archives are correct and we never corrupt a database.
The first pass of Conjoin for Archives is to perform conjoins in memory. For each line of code in the implementation, there are about five lines of testing performed. That’s an unusually high ratio, and is a pretty good indicator of how concerned I am about getting this right. Looking at our history and the guardrails we’ve put in place for the legacy format is how I ensure that we are doing this well on this new format. No one can promise zero bugs, but I will do my best to ensure that we honor what we’ve learned up to this point.
Archives will become the default storage format when we are confident that they are better in every way than the existing format. It’s not possible to assess if they are better without fully understanding what we are replacing. Ultimately all of our code (and bugs) are available for all of the world to see — so I’m not trying to pull one over on you. There really aren’t that many issues in our past which mention Conjoin, to be honest, which means that we got this pretty well nailed in the existing format. I’d like to continue that trend!
Come pick our brains about SQL version control on our Discord server!