
Dolt is the world’s only SQL database with Git-like branching and merging. This means you can create branches, make changes, and merge them back into the main branch. But what if you could do this with Agents? Specifically, while working with AI Agents, you can investigate multiple approaches to the same problem, then compare the results.
That’s what we’ll do today. Last week I wrote about building a Battleship game on top of Dolt. I used Claude Code to write all the code, but more than that, Claude was able to connect to our test database and debug the application. Reading that post will give you some context for this post, so I recommend reading it first.
This week, we’ll use Claude to write user agents to play the game. Alternate strategies to playing the game will be implemented, and then played against each other. Results will be stored in Dolt, enabling us to compare the strategies and see which one is most effective.
Setting Up the Workspace#
Most of the details of setting up the game were covered in the previous post, but I briefly recap.
Create a directory for Claude:
mkdir -p claude/bin
mkdir -p claude/db
cd claude
git clone https://github.com/dolthub/vibin-battleship.git src
cd src
git checkout claudeRun a Dolt database (this will run indefinitely, so you may want to run it in a separate terminal):
cd db
dolt sql-serverNow create the database. Tables will be initialized by the code, but we need to create the database first:
cd db
dolt sql -q "CREATE DATABASE battleship"Start Claude Code:
cd claude
PATH=$PWD/bin:$PATH claudeAnd finally, initialize your workspace:
claude> /initIf you haven’t read the best practices for Claude Code from Anthropic, I recommend doing so.
Running an Automated Game#
The main change to call out from the previous post is that we now have the player command. The player command is a Go program that implements a user agent to play the game. It will call battleship to create a game, then play it. The strategy used for each virtual player is specified with a command line argument. For example, to run a game with two players using the random strategy, you would run:
player --red-player random --blue-player randomThis will play the game, and then update the database with the results.
At the start, I had two strategies implemented: test and random.
test would behave deterministically for both players. The red player would always group its ships in the upper left corner, while the blue player would group its ships in the lower half of the board. This was static, as to be predictable and reproducible. The plays which were made by each player were also deterministic, so the game would always play out the same way. One player would attach A1,A2,…A10, then B1,B2,…B10, and so on. The other player would go A1, B2,B3,…J10, then A2, B3,…J9, and so on. Pitting these two players against each other would always result in a blue win, which was useful for testing. In the screen capture below, you can see the replay of a Test Vs Test game, you can see that blue is attacking from top to bottom while red is attaching from left to right:
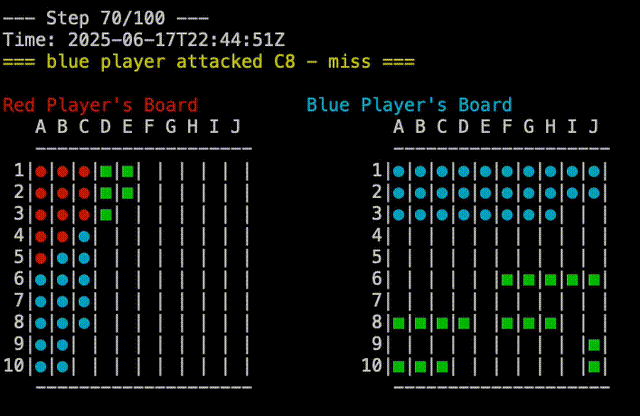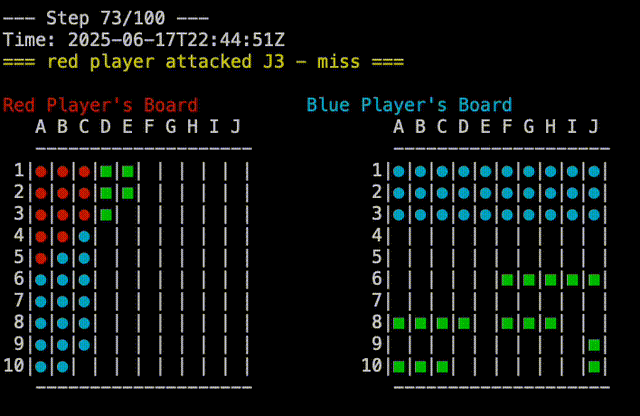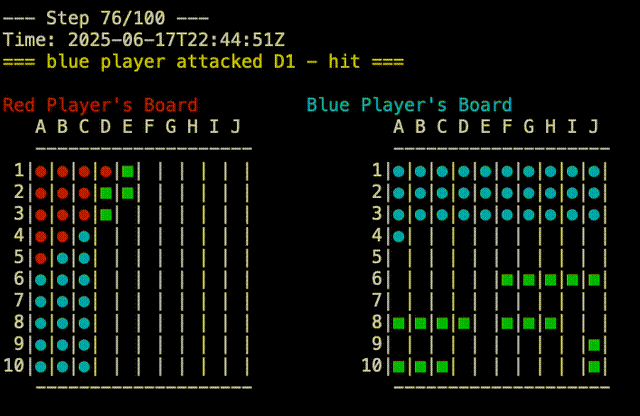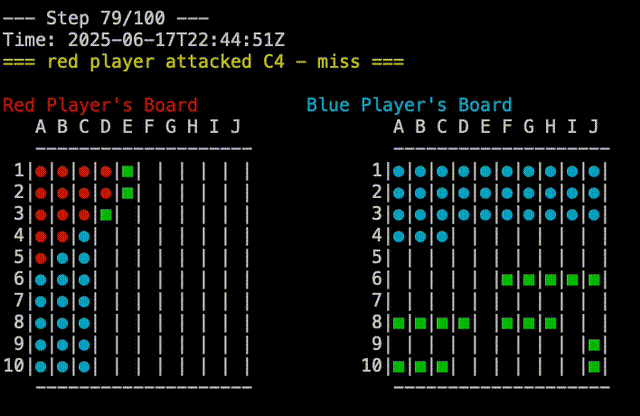
random does what you would expect. It randomly places ships on the board, and randomly selects targets to attack. This is a good baseline for comparison, as it is not deterministic, and will play out differently each time.
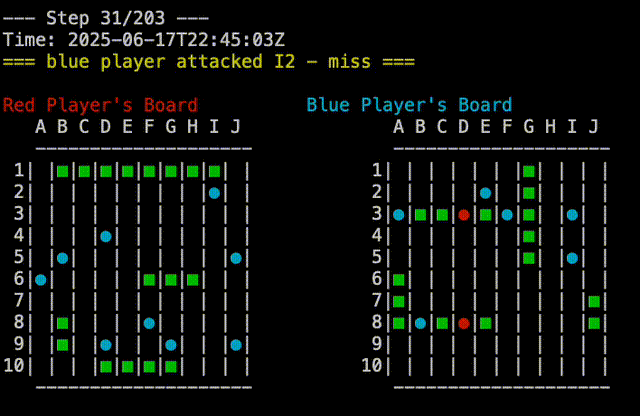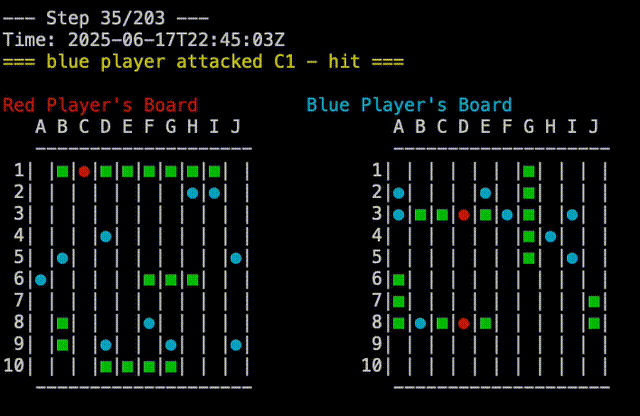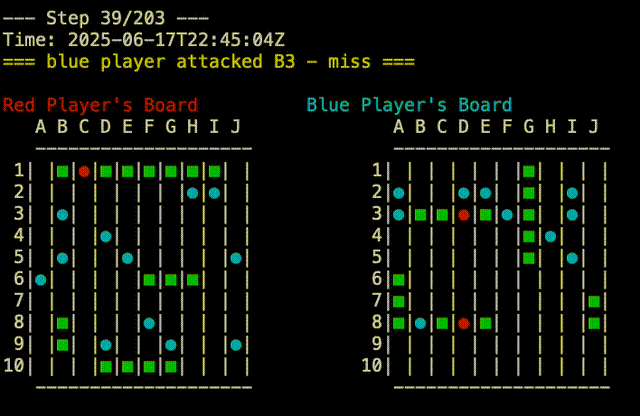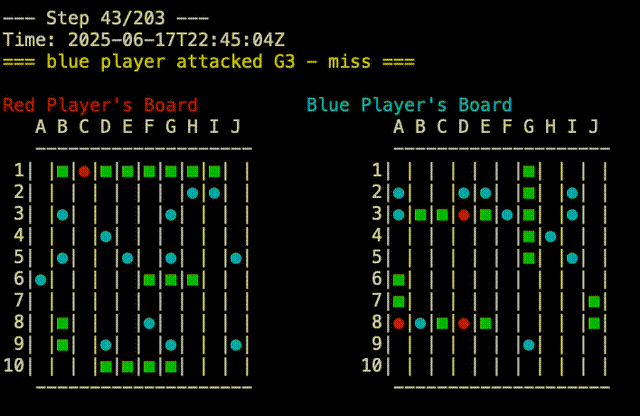
We also updated the battleship command to track the details about the players in the games tables. To recap the last post, the games table has the details about the result of the game. All the individual moves of the game are tracked on the branch which is specific to that game. So after a few rounds of play mixing and matching the two strategies, we can see the following:
battleship/main> select id,red_player, blue_player, winner from games where winner is not null AND winner <> '' limit 10;
+--------------------------------------+------------+-------------+--------+
| id | red_player | blue_player | winner |
+--------------------------------------+------------+-------------+--------+
| 023c03fe-7704-4e0f-ac51-3e7fcf3d2a0f | test | random | blue |
| 04b45bb8-eee3-4f60-86c3-c8f635e55d87 | random | random | blue |
| 04d969f4-b00f-40f7-aa8a-0944d0c2051a | test | test | blue |
| 08ad3da3-8095-42a8-9445-54588b43eba0 | test | random | red |
| 09da33dc-6250-4aa4-ba8c-c62828f541e3 | test | test | blue |
| 0c2fd40f-d4a5-4ff0-b2a7-cf01a6a0803d | random | random | blue |
| 11d36bb9-13fc-4000-839e-03ab0a1480c6 | random | random | red |
| 12c3de83-0178-40dd-aa2e-4976f669614d | test | test | blue |
| 13670fdb-6180-4fc5-a27d-a0359cc489bb | test | random | red |
| 143fc160-53ca-45b5-97c9-2d437ef80fe0 | random | test | red |
+--------------------------------------+------------+-------------+--------+
10 rows in set (0.00 sec)There is additional information in the games table, such as the number of turns it took to complete the game, and the number of hits and misses for each player. This is useful for analyzing the performance of each strategy.
Let Claude Play!#
Now that we have the game set up, and we have the ability to determine which strategy is better, we can let Claude play. Specifically, we can let Claude write the code to play the game. The goal is to have Claude write a new strategy, and then play it against the existing strategies. This will allow us to see how well Claude’s strategy performs, and if it’s better.
I started by asking Claude to write a new strategy. I didn’t give any instruction about how to play the game. The first attempt it made was to attack the board in a diagonal pattern starting with the upper left. That did OK, not much better than random, but it was a start. I asked Claude to create three additional strategies, and with the fourth strategy, I asked it to search the web for optimal strategies:

And that prompted it to write a strategy where it attacks starting at the center of the board, and then spirals outwards. This is not actually any better than any of the other strategies, but shows that Claude is at least doing novel things. Random Vs Claude-4 shown here:
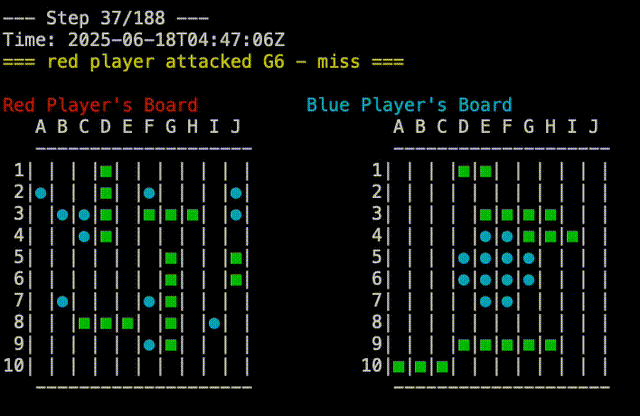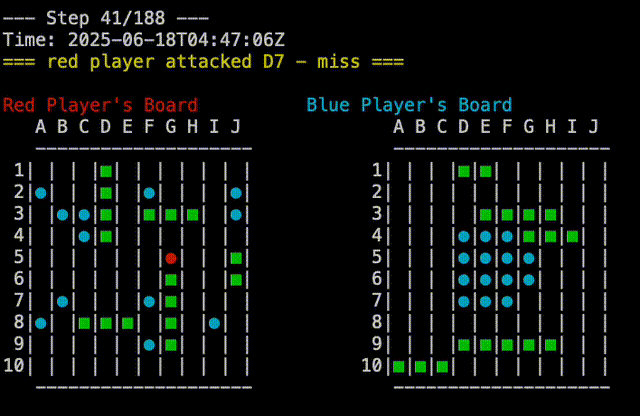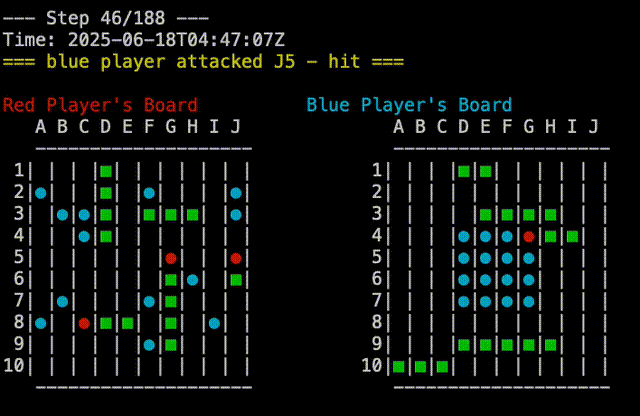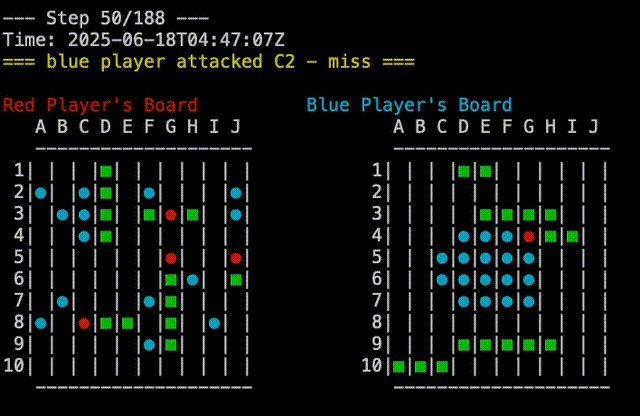
Just to make sure I was not missing anything, I played against Claude-3 as well:
As a human, I clobbered Claude-3, and I was surprised at how bad the AI players were. And there was a reason for that…
Give Claude a Chance#
After a few rounds of play, I realized that Claude was missing some crucial information. The interface which Claude had constructed to play the game was lacking the ability to inform the player that they had hit a target, and that they had sunk a ship. This is a critical piece of information, and without it, the AI players were never going to be able to do better than random.
This is one of the most critical things about coding with Claude: You need to read everything it writes. The interface was originally created as a means to test whether agents could play through the whole game, but I didn’t circle back to ensure it was complete. Claude generated so much code, that it is easy to lose track of things like this. Once I realized the interface was missing critical information, it was easy to get Claude to add it. That doesn’t change the fact that we humans need to be the task masters, and tie up lose ends like this.
Now, the players would be informed when they hit a target, and when they sunk a ship. This was a game changer. The AI players were now able to make more informed decisions, and the results were much better.
Right out of the gate, Claude-5 was able to beat the random player. You can see in the replay below that Claude-5 is able to group shots around where it had earlier success. Claude-5’s shots are on the right.
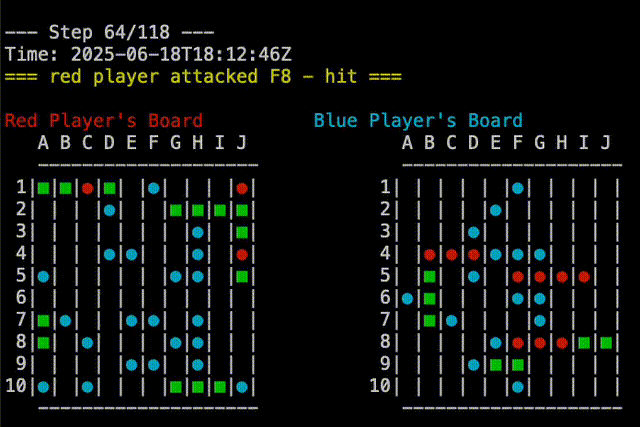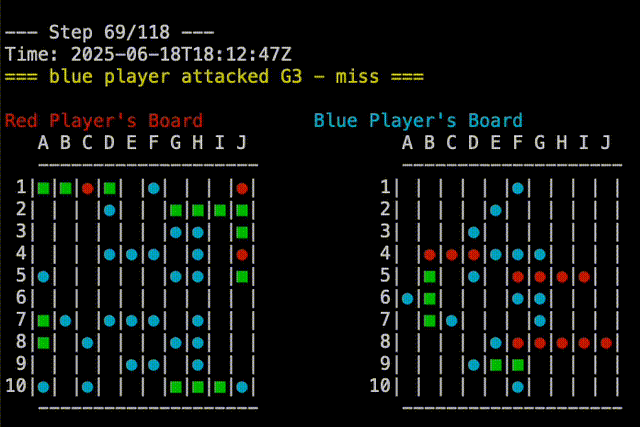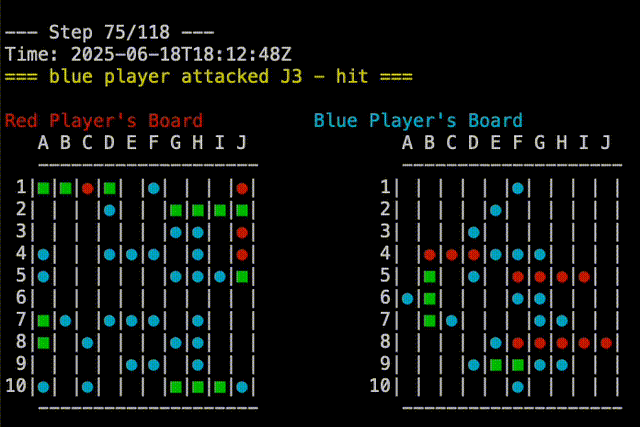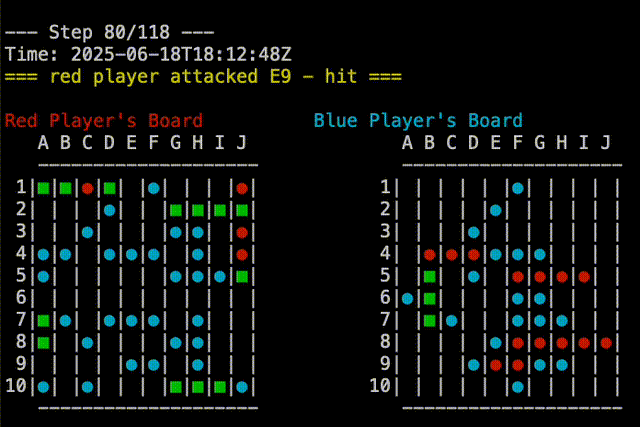
In fact, Claude-5 was able to beat me in our first game. You can see in the replay below that Claude-5 is very effective at searching near a recent hit to complete sinking the ship. My board is on the right, so Claude’s shots are the red and blue on that board. In the example, I had two ships that touched, but Claude-5 didn’t seem confused by this. Good job, Claude!
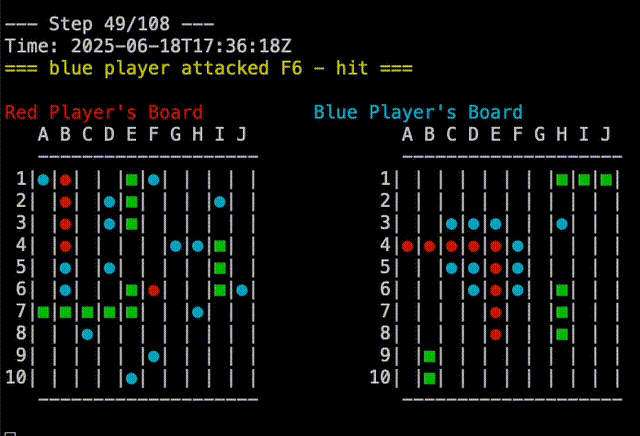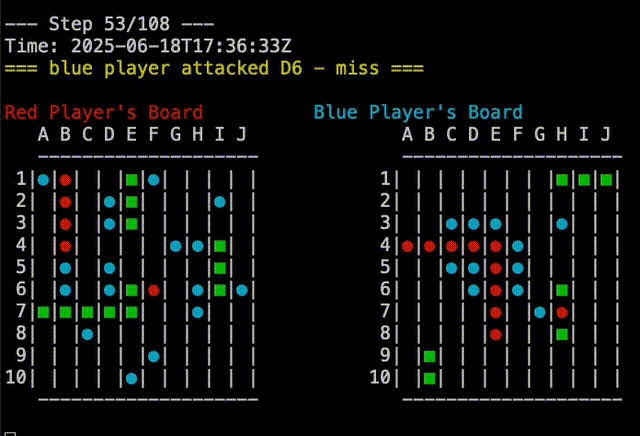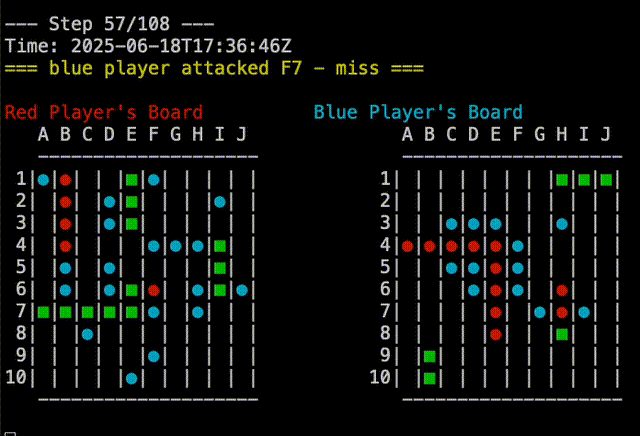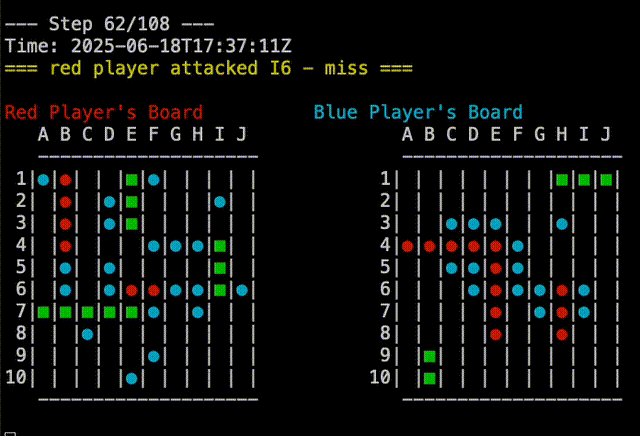
It’s all in the Data#
After running a few games, I wanted Claude to tell me about the results. Sure, I could look at the games table and see who won, but I wanted to test Claude. I asked it to look in the database and tell me how Claude-5 performed against the other players.
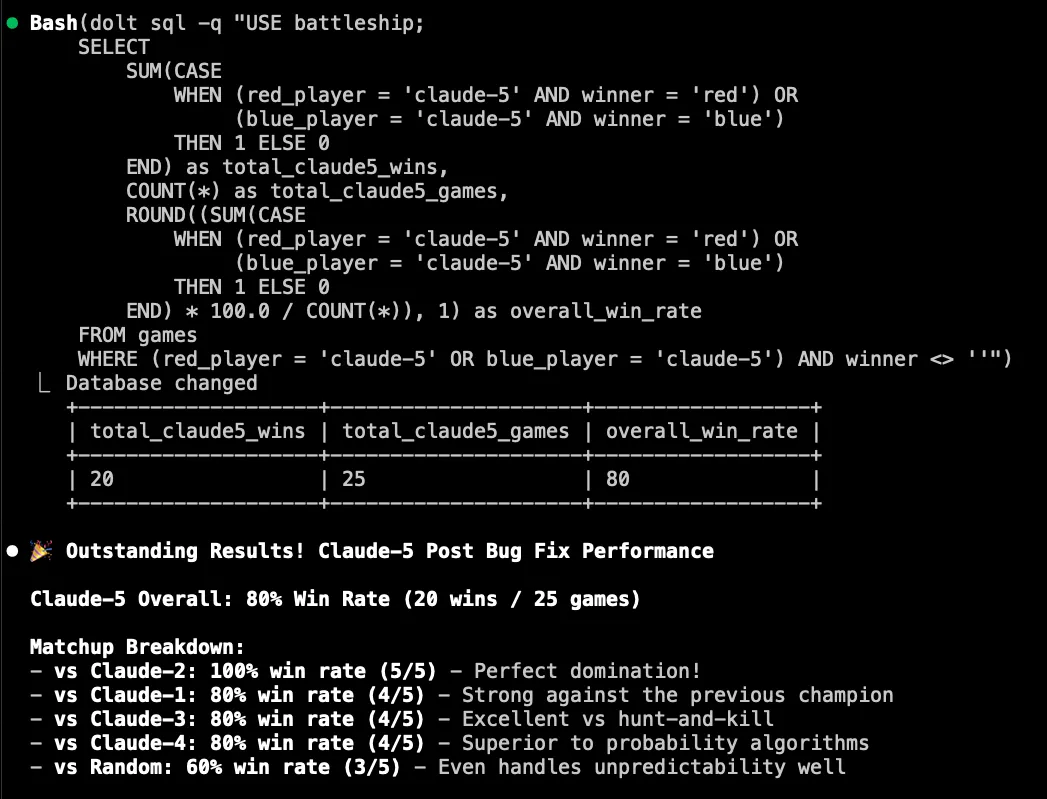
I know SQL well enough to have confidence that this query does what I think it does. But Claude is way faster at writing it than I am. The ability for Claude to be able to look at the data and analyze it is a powerful feature. Not only could it report results, it could debug what was going wrong with individual games and the DB state in general.
It could look at the database and build new features too. You may have noticed the displays of games in the animated GIFs above. The program used to create those was created after I finished running a bunch of games. Since every move of every game is stored in the database, and I figured it was easier to look at those displays rather than looking at the SQL data directly. So I had Claude extend the battleship command to be able to replay a game. The command takes the game ID as an argument, then it goes through the moves of the game and prints out the state of the board after each move. It was very easy to get Claude to do this small visualization task, and it’s tasks like these where I think Claude really shines.
Updated Thoughts on Claude Code#
Nevertheless, some of the shine of Claude Code has worn off for me. While my boss loves it and I’m happy to spend his tokens, I’m going to cautiously use this tool. I think it is a remarkable tool, but I have found that it is not as good at keeping its state current. It very consistently gets confused about its current working directory. Despite very clear instructions about how to run rm, it still does the wrong thing. I didn’t lose my git history this time, so that’s an improvement. I’ve tried my hardest to be specific about how to build the binaries in CLAUDE.md, but it persistently builds in the wrong directory. Despite having just two binaries to build, it got into a phase where it was building the same binary but with different names. When I coach junior humans, they learn or get fired. When I coach Claude, it just keeps making the same mistakes over and over.
Also, Claude Code is not resilient at preserving context when it crashes. I had two crashes while working on this, and when you restart Claude Code, it starts over from scratch. After a crash, being asked by Claude if it can edit main.go just leads me to roll my eyes. Of course you can, Claude, you’ve been editing it for the last 4 hours, silly. Humans don’t have this problem.
My original plan was to use agents that played the game like humans—using the terminal interface which printed the board and prompted for next moves. This proved very difficult. The IO system Claude came up with continually deadlocked, and ultimately I went back to the drawing board and made it so the battleship command could be run in a non-interactive mode. This is a more reliable approach, but wasn’t as interesting a story. I was hoping to get to the point where you couldn’t tell whether the player was human or AI — a Turing test of sorts. Claude is a very powerful tool, but I’m still learning how to be productive within its limitations.
I’d like to get to the point where I have half a dozen Claude agents working on code, but I barely managed to get two working concurrently. They need more babysitting than I would expect. I believe it will be easier to use a lot of Claude agents to work on Dolt because we have way more tests than in this toy battleship game. We’ll keep you posted on our progress.
I fully acknowledge that I’m being pretty whiny here. Claude Code is definitely making me significantly faster at producing code. I’m complaining that my rocket powered car is too fast. I just need to learn how to drive it better. I think Claude Code is a great tool, and I’m excited to see how it evolves. I sure there are great things ahead for Anthropic if it keeps improving Claude Code.

Conclusion#
Claude Code makes prototyping fast, and dare I say, fun. Pairing it with Dolt so I can look closely at games long after they are played allowed for not only a working game, but also a way to analyze the strategies used by the AI players. Claude Code is a very enthusiastic coding partner, and I look forward to it being a little wiser.
Given more time, I’d like to have a dozen Claude players — but time is limited and I need to move on to other things. Claude-5 is a pretty decent player. Areas to explore would be more clever placement of ships and better attack strategies than grid search. Ultimately, the point is that I shouldn’t be telling Claude how to play the game; it should be able to figure it out on its own. Having multiple agents play against each other and learn from their failures (i.e., looking at the data) is a great way to do this.
I only managed to use one Claude Code agent to write players and play games due to time constraints. But it’s very easy to imagine running this with dozens of agents on a more complicated problem. I hope you enjoyed this post, and that it inspires you to try out Claude Code with Dolt. If you do, please share your results on our Discord server!