
Introduction#
We’re hard at work building Doltgres, a Postgres-compatible database with git-inspired version control features. Before we built Doltgres we built Dolt, which is MySQL-compatible instead.
One of the biggest differences in Postgres when you’re coming from a MySQL background is how you reference tables and other top-level schema elements (like views, triggers, etc.). This is because Postgres has schemas and MySQL does not. Let’s look at what that means.
MySQL doesn’t have schemas, only databases#
In MySQL, the terms schema and database are synonymous.
mysql> create database mydb1;
Query OK, 1 row affected (0.00 sec)
mysql> create schema mydb2;
Query OK, 1 row affected (0.01 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| mydb1 |
| mydb2 |
| mysql |
| performance_schema |
+--------------------+
15 rows in set (0.00 sec)
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| mydb1 |
| mydb2 |
| mysql |
| performance_schema |
+--------------------+
15 rows in set (0.00 sec)
mysql> use mydb1;
Database changed
mysql> select database();
+------------+
| database() |
+------------+
| mydb1 |
+------------+
1 row in set (0.00 sec)
mysql> select schema();
+----------+
| schema() |
+----------+
| mydb1 |
+----------+
1 row in set (0.00 sec)If I want to reference a table, I can use its fully-qualified name, which means prepending the database name as a qualifier. This works for all kinds of statements.
mysql> create table mydb2.myTable(a int primary key);
Query OK, 0 rows affected (0.03 sec)
mysql> insert into mydb2.myTable values (1);
Query OK, 1 row affected (0.01 sec)
mysql> select * from mydb2.myTable;
+---+
| a |
+---+
| 1 |
+---+If I don’t qualify the name of a table or other top-level element, it gets automatically qualified with the name of the currently connected database. So this statement doesn’t work:
mysql> select * from myTable;
ERROR 1146 (42S02): Table 'mydb1.mytable' doesn't existPostgres has schemas in its databases#
In Postgres, all this works quite differently, because Postgres has an additional namespace element: schemas. If you’re coming from the MySQL world, schemas are roughly the equivalent of what MySQL calls a database. They’re an additional level of hierarchy and namespace underneath what Postgres calls a database. This is easiest to see laid out with an example. Here’s what I see when I connect to my local Postgres server with pgAdmin:
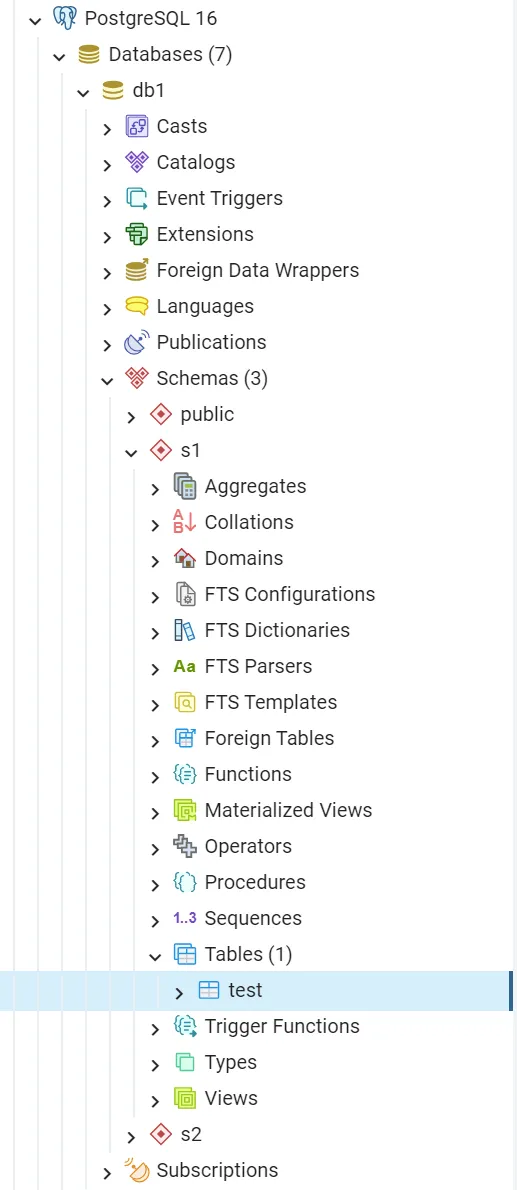
So in my local Postgres 16 server, I have 7 databases. The db1 database has 3 schemas named
public, s1 and s2. The s1 schema has a table called test.
If I want to refer to this table, I can use its schema-qualified name like this:
postgres=# \c db1;
You are now connected to database "db1" as user "postgres".
db1=# select * from s1.test;
a
---
1
(1 row)I can also use the fully-qualified name, which includes the database, like this:
db1=# select * from db1.s1.test;
a
---
1
(1 row)But this is where things get quite different from MySQL. This doesn’t work:
db1=# select * from test;
ERROR: relation "test" does not exist
LINE 1: select * from test;
^And neither does this:
db1=# \c postgres;
You are now connected to database "postgres" as user "postgres".
postgres=# select * from db1.s1.test;
ERROR: cross-database references are not implemented: "db1.s1.test"
LINE 1: select * from db1.s1.test;
^What’s going on here?
Introducing the search_path#
MySQL resolves table names by using the currently connected database, if there is one. If there isn’t one, then all table names must be qualified with a database name.
Postgres went a very different route, implementing a solution that calls to mind the Unix shell
philosophy: search_path.
db1=# SHOW search_path;
search_path
--------------
"$user", publicSo when you use an unqualified table name, Postgres resolves it by looking at the schemas in
search_path, in order, until it finds it. By default, there are two schemas in this list: the one
with the same name as the connected user, and the schema public. The public schema is kind of
special in Postgres, because it gets created automatically in every database, and is the implicit
schema for any CREATE TABLE statement. It’s why you can mostly pretend that schemas don’t exist in
Postgres and things will still work. For example:
db1=# create table test (a int primary key);
CREATE TABLE
db1=# insert into test values (1);
INSERT 0 1
db1=# select * from test;
a
---
1
(1 row)All of the above works because the table names get implicitly qualified with the public
schema. But be careful! Creating a schema with the same name as your connected user will change the
behavior of existing SQL statements. Here we’ll create a second test table in the postgres
schema:
db1=# create schema postgres;
CREATE SCHEMA
db1=# create table postgres.test (a int primary key);
CREATE TABLE
db1=# insert into postgres.test values (2);
INSERT 0 1Now when I run the select statement, I get a completely different result:
db1=# select * from test;
a
---
2
(1 row)This behavior occurs because of search_path: the table postgres.test comes before public.test,
which means that the statement above is equivalent to select * from postgres.test.
To prevent this behavior from being abused by a bad actor, Postgres offers this guidance.
Schemas can be used to organize your data in many ways. A secure schema usage pattern prevents untrusted users from changing the behavior of other users’ queries. When a database does not use a secure schema usage pattern, users wishing to securely query that database would take protective action at the beginning of each session. Specifically, they would begin each session by setting search_path to the empty string or otherwise removing schemas that are writable by non-superusers from search_path.
And what about the error ERROR: cross-database references are not implemented: "db1.s1.test"
above? As it turns out, Postgres does not allow you to reference tables in databases other than the
one you’re currently connected to.
Actually, the even more general syntax
database.schema.tablecan be used too, but at present this is just for pro forma compliance with the SQL standard. If you write a database name, it must be the same as the database you are connected to.
For the most part this isn’t a serious restriction, since schemas in Postgres are basically equivalent (semantically) to databases in MySQL: you get one level of namespacing in any given query. But you should be aware of the limitation.
Schemas in Doltgres#
Doltgres is built on top of Dolt, which emulates MySQL.
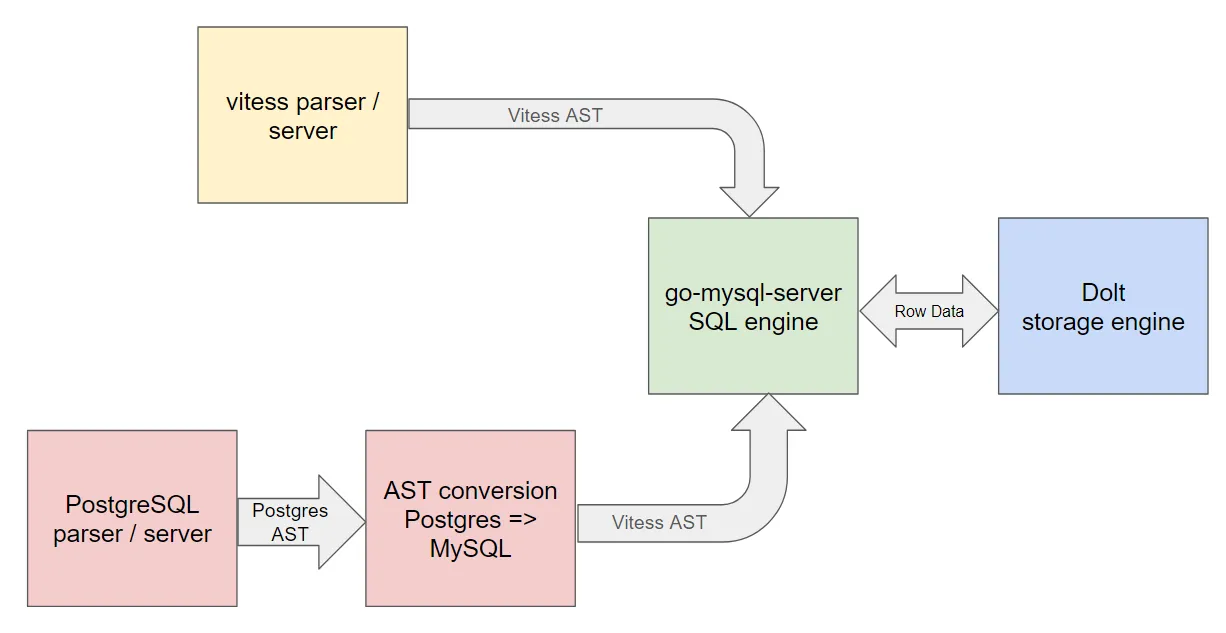
Since MySQL doesn’t have schemas, neither does Dolt. But Doltgres needs them to support existing Postgres applications which use them, and to be a 100% compatible, drop-in replacement for Postgres. So we’re in the process of building them.
What works so far: you can qualify a table with its schema name in statements, e.g.:
create table mydb.schema1.test (a int primary key);Getting there required augmenting how Dolt serializes its table schemas to optionally include a schema name. We put this capability directly in Dolt, rather than in the Doltgres layer, so that in the future, we could stick multiple Dolt databases in the same commit graph, which is a cool feature that a few customers have asked for.
There’s still a lot that doesn’t work though:
- No
search_pathsupport - No
publicschema created by default - No foreign key support
- No schema elements except tables supported yet
And unlike Postgres, Doltgres allows you to reference tables in databases other than the one you’re connected to.
We’re hard at work implementing all of these missing features, so check back here for updates every Tuesday.
Conclusion#
Doltgres is free and open source, so go check it out if you’re curious about a Postgres compatible database with version control features. Doltgres isn’t ready for production use yet, but we’re looking for potential customers to guide our roadmap and let us know what we should be building first.
Have questions about Doltgres or Postgres schemas? Join us on Discord to talk to our engineering team and meet other Dolt users.