Your config file should be a database

In my pre-startup life I worked at Google, a company that has some pretty incredible, internal-only technology that you won't find anywhere else. An entire engineering culture has developed around the availability of these technologies, and it's pretty firmly rooted at this point. At Google, things are "just done" in a certain way that you don't get points for questioning. Some of the ones that surprised me when I was there:
- To get data from another team's product, it's very common to receive direct read access to their prod database
- Databases don't often have schemas that you would recognize from the outside world. Rather, most tables have effectively two columns: an ID and a protobuffer payload.
- Every problem that can possibly be implemented in massively parallel fashion via a map-reduce must be. No exceptions if your data is so small a for loop would be much faster.
But one cultural practice struck me as so utterly bizarre and backwards that it has stuck with me all these years later, and I find myself thinking about it often. I'm talking about using giant textual config files as a system's data store. At Google these usually took the form of text-serialized protobuffers, but in the wider world they tend to be YAML. In meme form:

What am I talking about, and why is this practice so bad? Let me illustrate with a story.
Deploying a new secret key pair at Google
Another cultural practice at Google is what I would call technical solution convergence, or maybe technical conformity. For some domains, like databases or web servers, there are several available choices of internal technology. For others, like user ID or secret management, there is exactly one solution, and you have to use it. No exceptions.
At Google, if you want your product to be able to do any encryption or decryption, the relevant secrets must be managed by a monolithic key server. Your software is registered with it and is allowed to retrieve the necessary keys via RPC at runtime. This isn't terrible in itself, it makes sense. The terrible part is how you manage the secrets.
GitHub has a similar issue for clients, but exists in the real world, not in Google's internal walled garden. Here's how you manage secrets in GitHub:
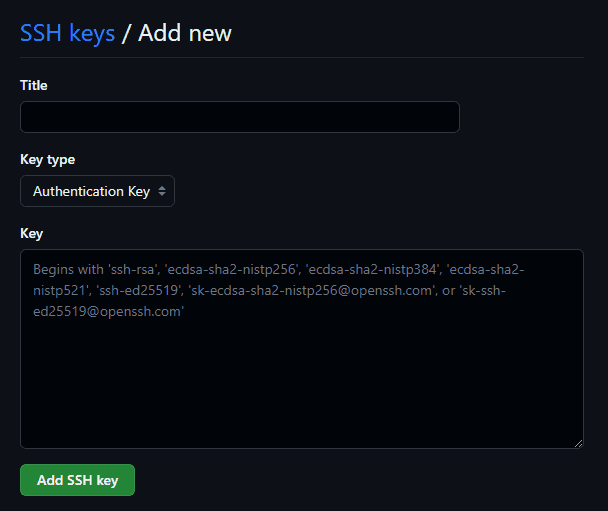
When we built DoltHub, we copied this flow pretty exactly. Here's what our version looks like:
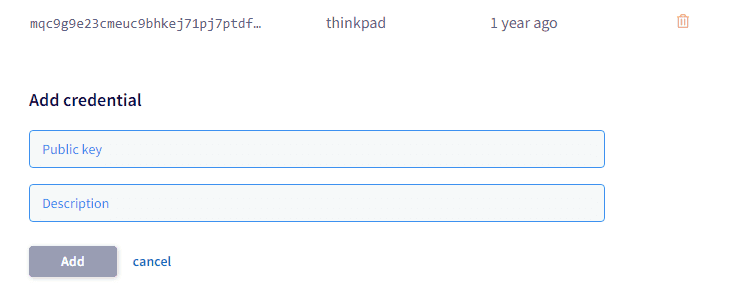
I know what you're thinking: is Google's key management web form worse or something?

To deploy a new secret at Google, you do the following:
- Generate the secret with a command line tool (no problems so far)
- Edit a source-controlled text file called
secrets.cfg. When I was at Google this file was about 300k lines, but it's surely much larger by now. - Send a PR to the team that owns the secret server, asking for approval for your new secret.
- They review and accept your PR within their 24 hour SLA (press X to doubt)
- Your secret gets compiled into a new binary of the secret server in the next nightly build.
- Your secret is live and can be accessed via RPC by approved caller identities.
Now, you might well ask: what happens if you fat-finger the key? Do you have to wait another 24+ hours to fix it? Yes, yes you do.
On my team at Google we worked with a brilliant but hot-tempered guy who shared my frustration with this sort of thing at Google. We both had cut our teeth at Amazon, where any process as inefficient as this one would have resulted in serial terminations until fixed. One time he was the unlucky guy who fat-fingered the secret, and the team was mad they had to wait another day to test the changes. Jokingly, I told him, "You fucked up man." I'll never forget his response:
Did I fuck up?
Or did the person who failed to make this a web form fuck up?
All my biases tell me that it was, in fact, the person who chose to not make creating a key as easy as clicking a button, who fucked up. This is maybe a matter of personal philosophy, but I really subscribe to the tenet that most software errors are the fault of the programmer, not the user. "My users keep messing up" is just a way to shift the blame off yourself for not making your interface better.
So the question is: why did they choose to make their software work that way? What's the appeal of the giant text config file?
The steel man case for giant config files
We have to begin by acknowledging the appeal of a pattern that causes so much pain and frustration in the world. And there's a lot to like!
- Human readable. This is a nice property for data to have. Being human readable also means you can edit it with a standard text editor.
- Self-contained. A giant text config file has no dependencies other than a parser library.
- Easy to implement. The easiest to build UX is no UX at all.
- Version controlled. Text can be put in source control, with all the benefits that entails: history, branches, rollbacks, etc.
Whenever I would argue with people at Google about why the interface to a critical system was a text file with 300,000 lines stored in source control, rather than, you know, a web page, these were the reasons given. And there are a lot of such critical files at Google, including things like the pager rotations. They're all in source control. That's how it's always been done and it's always worked, right?
The final strength, being able to version control config, was always a sticking point in these conversations: you really do want the power of version control in your system configuration store, for all the same reasons source control for code is a good idea.
So it's actually pretty easy to understand why there are so many examples of this pattern in the world. We have one particularly egregious one in our own internal codebase.
% find k8s -type f -name "*.yaml" -exec cat {} + | wc -l
42009This controls our kubernetes deployment of a half dozen or so services on two cloud providers, so it could be much worse. But 42,000 lines of YAML is still not great!
The case against giant text files
Text files are nice. Text files are easy. Text is the universal interface.
But as nice as giant text files are, they have very major drawbacks.
- Hard to read and understand. Sure, they're technically human readable, we even listed that as a strength above. But have you ever needed to answer a non-trivial question about the data in one of these giant files? Grep only goes so far. You often have to write a custom program to get answers.
- Difficult to edit safely. Text files are just text, which means it's possible for a stray character to make them fail to parse. Some formats, like YAML, are whitespace sensitive, so small, hard-to-notice changes can completely change or invalidate the data. And as they get really large, they strain most text editors.
- Difficult to build UX on. This follows directly from the previous point. Is it possible to build a web GUI that displays information stored in a giant text file, as well as allows you to edit it concurrently with other users safely and correctly? Sure, but it's so hard almost nobody does. (There were several mostly-failed projects to build GUIs on top of giant text files at Google.) Instead, the text format ossifies and editing it directly becomes the only possible interface to it.
As easy as it is to get started with data stored as text, as your system grows and matures the downsides start to pile up. It's a classic engineering trade-off: between expedient and easy to start, versus possible to scale up.
But what's the alternative? Can you avoid the problems of text data storage without abandoning what made it attractive in the first place? I say yes, you can.
Databases: 1970's technology for solving today's problems
We're a database company, so of course we think the solution is using a database. But there's a reason that database technologies continue to proliferate and flourish: they're incredibly useful pieces of software.
Let's revisit the list of advantages of text data storage and see how modern databases compare.
- Human readable. You lose this property when moving to databases. You need a tool to query the binary format. Score one point for text.
- Self-contained. In the past databases were giant memory hogs run only on dedicated hardware, but this is no longer true. Several newer databases, most notably SQLite and Dolt, have local file storage that you can query via a library with no separate process, exactly as if the data were stored via JSON or YAML.
- Easy to implement. It's very slightly harder to think of and execute a few
CREATE TABLEandINSERTstatements, rather than writing YAML. But not harder enough to matter. And SQL workbench tools can make the process of data entry as easy as editing a spreadsheet. - Version controlled. Contrary to popular belief, database storage is no real barrier to version control. SCD2 has been around for decades, the big three database vendors have supported versioned tables for about as long, and now there are even a few databases with git-style version control built in, like Dolt.
So databases actually compare pretty favorably to text-based data storage. You lose human readability, but that's about it. Meanwhile, databases directly address all the drawbacks of text storage head-on:
- Easy to get answers from. A SQL query engine makes it possible to get almost any conceivable answer from your data.
- Possible to edit safely. Unlike text files, databases let you put constraints on your data to help ensure its accuracy. It's impossible to forget to enter a required field, or to improperly format a string.
- Possible to build UX on. Databases are the only reliable way to build a multi-user GUI that edits shared data reliably. There are 50 years of research and design patterns to draw on to solve your domain problems.
Put in these terms, it's pretty obvious that database solutions start to really dominate text the moment a config file leaves the context of a single computer and needs to be managed by multiple users. If you try to push your text-based prototype past that point, your users are the ones who will pay for it.
Conclusion
So to revisit our original question: who fucked up, really?
Did I fuck up?
Or did the person who failed to make this a web form fuck up?
Like all things in software, there's no single right answer. But it's incumbent on every engineer to think about how the solutions we build today will impact how the system is used when it has a thousand times as many users. Don't accept the de facto standard of text storage just because it's popular and easy. Think about what it means for your system, and remember your users will blame you for their errors. And they will have a point.
If the topic of technical culture at Google interests you, this recent essay by a start-up founder acquired by Google on its culture and its problems echoes my own thoughts almost exactly. I may write more on this topic at some point, but for now you should read his take.
Have questions about Dolt, or want to argue about text data storage? Join us on Discord to talk to our engineering team and meet other Dolt users.