
For the past few months at DoltHub, we’ve been really excited about the release of Dolt 1.0. If you missed it, it dropped last Friday May 5th.
Dolt 1.0 is the first stable release of Dolt and guarantees forward storage compatibility, production grade performance, MySQL compatibility, and a stable version-control interface.
Leading up to the release, we’ve also been working behind the scenes to migrate DoltHub.com from using PostgreSQL as its database, to using Dolt—a really cool project that further demonstrates to the world that we’re all in on Dolt, and we want you to be too.
In this blog I’ll share DoltHub’s migration journey from using AWS RDS Aurora PostgreSQL to using a Hosted Dolt Deployment and I’ll cover some clever strategies we employed to overcome some hurdles we faced along the way.
Before we jump in, those newer to the Dolt community might be wondering why DoltHub.com was backed by PostgreSQL to begin with.
Well, as Tim mentioned in the Dolt 1.0 announcement blog, we’ve spent the last two years turning Dolt into a production grade, versioned, application database. But prior to that, our vision for Dolt and DoltHub was centered around distributed data sharing and collaboration—we didn’t think to make Dolt a fully fledged application database until some early customers started requesting Dolt for this use case.
Originally, we imagined Dolt as the quintessential new data format; like the standard CSV, only better. We also envisioned DoltHub.com to be the place on the internet for collaborating on data in a versioned, type-safe, and ergonomic way. As a result, when we launched DoltHub.com, we did so by backing it with a standard relational database, opting for Aurora PostgreSQL through AWS RDS. But, crucially, at that time (this was 2019), we didn’t even know that we’d be setting out to build a versioned application SQL database.
It wasn’t until early 2021 that we took up the mantle and committed ourselves to building Dolt from the ground up with the OLTP use case in mind. From that point forward, we were counting the days until we’d be able to start backing all of our production applications with Dolt.
Now, almost two years later, we’ve been able to do so.
In early 2023 we launched Hosted Dolt, our managed Dolt service, running with Dolt as its database. And now, with the release of Dolt 1.0, we’ve also moved DoltHub.com fully onto Dolt as well—specifically, onto its own Hosted Dolt instance!
Below I’ll share how we pulled this migration off with minimal downtime and interruptions for DoltHub’s end users, and I’ll also discuss some bugs we found along the way. Discovering these bugs through the process of “dog-fooding” with Hosted Dolt was an invaluable experience. It has certainly made our products better and given us more insights into what our customers may come across. Please enjoy.
Simple plan, simple migration#
We started with a fairly straightforward plan. We decided that migrating DoltHub from PostgreSQL to a Hosted Dolt instance would be a two-stage process.
Stage one we called “double-writes”. During this stage, we would stand up a Hosted Dolt instance next to our existing PostgreSQL instance, making PostgreSQL the “primary” database and Hosted Dolt the “secondary” database.
Then, we’d asynchronously duplicate all writes against the primary database, in the secondary. This would allow us to compare write performance between the primary and secondary, and debug any unexpected errors as necessary. Our hope was to catch bugs in the secondary without impacting writes or reads against the primary. During this stage all read traffic would continue to run solely against the primary.
Stage two we called “double-reads”. In this stage we planned to perform both writes and reads against both databases. Importantly, this mode would allow us to compare the performance of reads on the secondary, and if they seemed reasonable, flip the databases, making the primary the secondary and the secondary the primary.
Once flipped, reads and writes would occur against the primary Hosted Dolt instance, and the transition from PostgreSQL to Hosted Dolt would, essentially, be complete. After a period of time for cautious observation, we could simply disconnect our PostgreSQL instance and roll forward with only Hosted Dolt.
With our plan outlined, we began laying the groundwork for stage one by instrumenting some custom Prometheus metrics in DoltHub’s API. These metrics would allow us to compare query latency for the primary and secondary databases, as well as alarm on unexpected database errors.
Measuring Dolt’s success#
DoltHub’s golang API server connects to PostgreSQL using an ORM—our fork of gocraft/dbr called dolthub/dbr. As a prerequisite to stage one of our migration work, we added Prometheus metrics that measure the latencies of queries (both write and read) that run against each database. We did this so that we’d be able to compare differences in latencies by query.
Conveniently, the ORM provides the following interface for event tracing that we use to record latencies by database_type and query_id:
// TracingEventReceiver is an optional interface an EventReceiver type can implement
// to allow tracing instrumentation
type TracingEventReceiver interface {
SpanStart(ctx context.Context, eventName, query string) context.Context
SpanError(ctx context.Context, err error)
SpanFinish(ctx context.Context)
}The dbr package calls the SpanStart method at the start of a database query and it calls SpanFinish once the query completes. SpanError, it calls if an error is encountered. To measure query latency, we gave each query in DoltHub’s API a unique query_id and used the context object to start a clock and measure the elapsed time. To do this, we used the following functions to store and retrieve metadata on the incoming context:
type dbrLatencyMetadataKey struct{}
type dbrQueryMetadataKey struct{}
// DbrLatencyMetadata stores metadata used for determining the latency of a dbr event.
type DbrLatencyMetadata struct {
EventName string
StartTime time.Time
}
// WithDbrLatencyMetadata stores DbrLatencyMetadata in the provided context.
func WithDbrLatencyMetadata(ctx context.Context, dbrm DbrLatencyMetadata) context.Context {
return context.WithValue(ctx, dbrLatencyMetadataKey{}, dbrm)
}
// GetDbrLatencyMetadata returns the DbrLatencyMetadata and a boolean indicating if it was found.
func GetDbrLatencyMetadata(ctx context.Context) (dbrm DbrLatencyMetadata, ok bool) {
dbrm, ok = ctx.Value(dbrLatencyMetadataKey{}).(DbrLatencyMetadata)
return
}
// DbrQueryMetadata stores metadata used for tracking a query identifier.
type DbrQueryMetadata struct {
QueryId string
}
// WithDbrQueryMetadata stores DbrQueryMetadata in the provided context.
func WithDbrQueryMetadata(ctx context.Context, dbrm DbrQueryMetadata) context.Context {
return context.WithValue(ctx, dbrQueryMetadataKey{}, dbrm)
}
// GetDbrQueryMetadata returns the DbrQueryMetadata and a boolean indicating if it was found.
func GetDbrQueryMetadata(ctx context.Context) (dbrm DbrQueryMetadata, ok bool) {
dbrm, ok = ctx.Value(dbrQueryMetadataKey{}).(DbrQueryMetadata)
return
}DbrLatencyMetadata is used to measure query latency and DbrQueryMetadata stores a unique query_id. Then, in the API code, before the ORM code runs, we register the query_id. For example, here’s the code for getting a DoltHub.com User by their id:
func (r *sqlUserRepository) GetByID(ctx context.Context, id domain.UserID) (*User, error) {
qCtx := dbr.WithDbrQueryMetadata(ctx, dbr.DbrQueryMetadata{QueryId: "user_repo_get_by_id"})
u := &domain.User{}
stmt := r.Select("*").From("users").Where("id = ?", id)
if err := stmt.LoadOneContext(qCtx, u); err != nil {
if err == dbr.ErrNotFound {
return nil, nil
}
return nil, err
}
return u, nil
}Above, the context is updated with the query_id, and then supplied to the ORM layer during stmt.LoadOneContext(qCtx, u). During this execution, the ORM calls SpanStart and then SpanFinish on our custom TracingEventReceiver implementation, which looks like this:
var latencies = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "dbr_query_latency",
Help: "Latencies of dbr Queries",
},
[]string{"database_type", "database", "event_name", "query_id"},
)
...
func (r receiver) SpanStart(ctx context.Context, eventName, query string) context.Context {
return dbr.WithDbrLatencyMetadata(ctx, dbr.DbrLatencyMetadata{StartTime: time.Now(), EventName: eventName})
}
func (r receiver) SpanFinish(ctx context.Context) {
if q, ok := dbr.GetDbrQueryMetadata(ctx); ok {
if l, ok := dbr.GetDbrLatencyMetadata(ctx); ok {
nanos := time.Since(l.StartTime).Nanoseconds()
latencies.WithLabelValues(string(r.dbType), r.dbName, l.EventName, q.QueryId).Observe(float64(nanos) / nanosecondsInSecond)
}
}
}The above snippet shows that during SpanStart we capture the start time of the query. During SpanFinish, we get both the DbrQueryMetadata and the DbrLatencyMetadata from the incoming context and write the measurements to Prometheus. latencies is a Prometheus Histogram with labels added to make graphing easier.
The result of our new latency metrics look something like this (once we both the primary and secondary database are up and running):
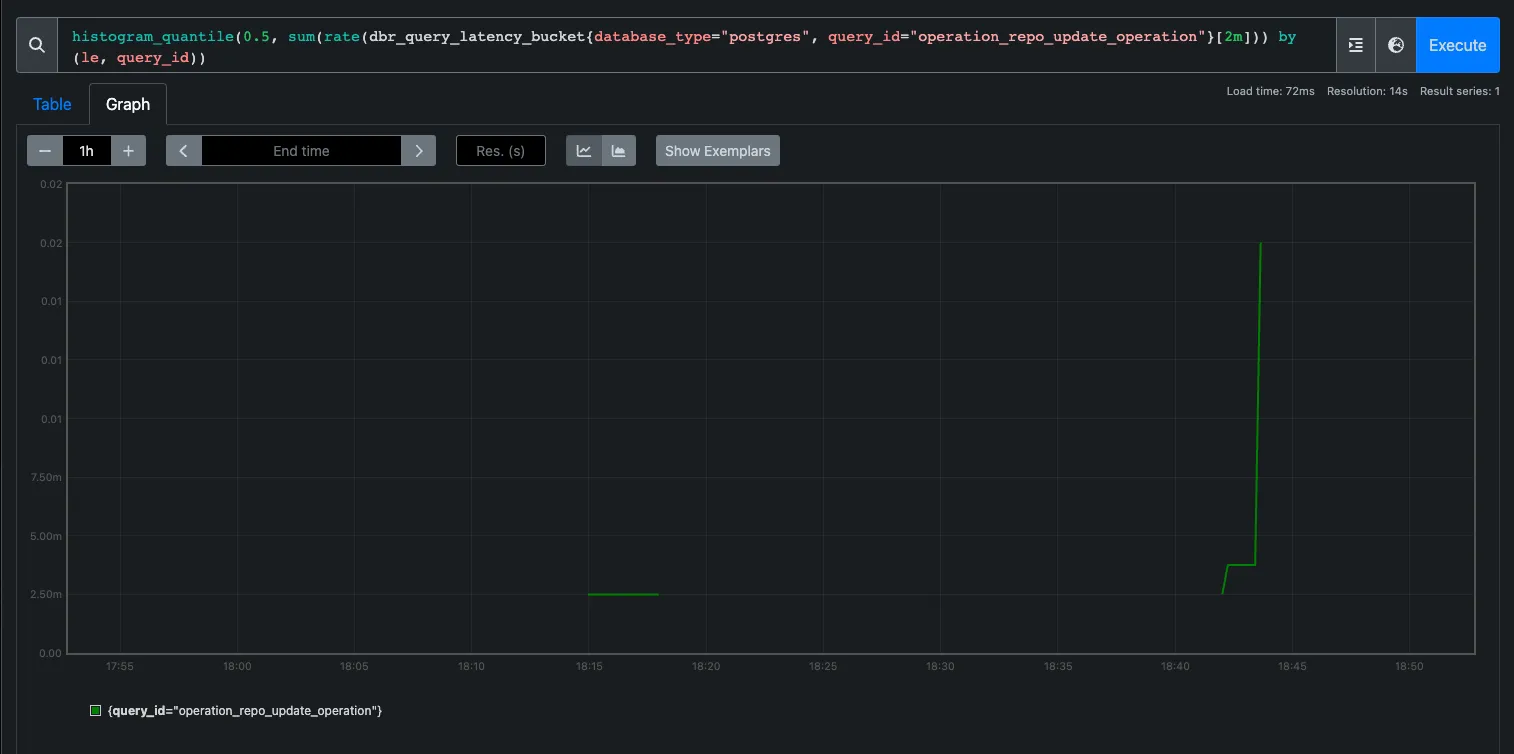
In the above graph we can see that updates to one particular table in PostgreSQL are very fast, at the 50th percentile, taking only 20 milliseconds (.02 seconds) over a 2 minute period.
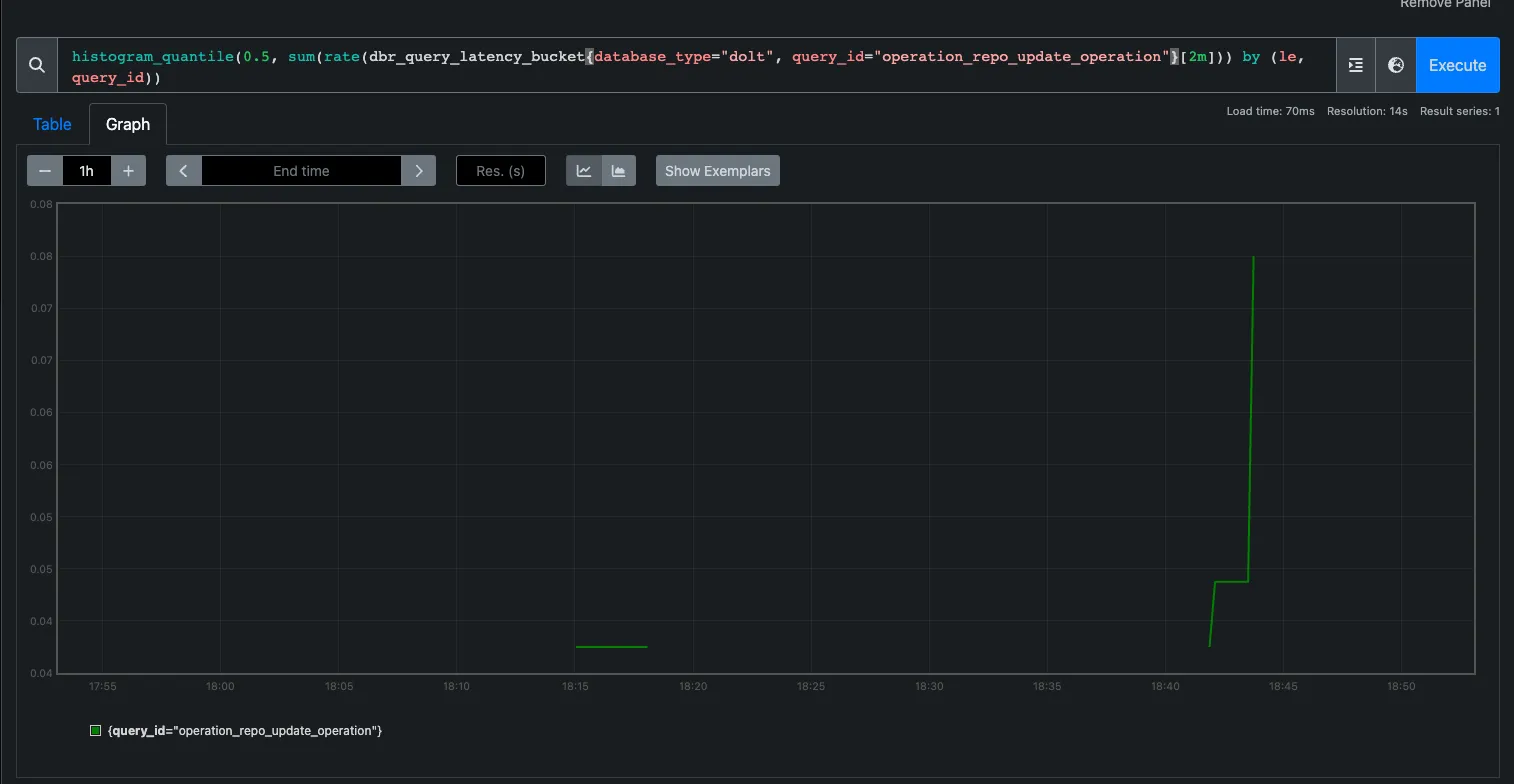
In this graph, which looks at our Hosted Dolt secondary database, we can see these same writes took 80 milliseconds over 2 minutes. In this example we’re observing a 4x slow down on writes for Hosted Dolt compared to the same write in PostgreSQL, but this is certainly not the case for all queries.
As a part of this initial metrics work we also added database error metrics to Prometheus too. Just like with latency measurements, we can logically group and compare errors returned by our databases and monitor any unexpected failures. We were even able to set up alarms on errors coming from either database.
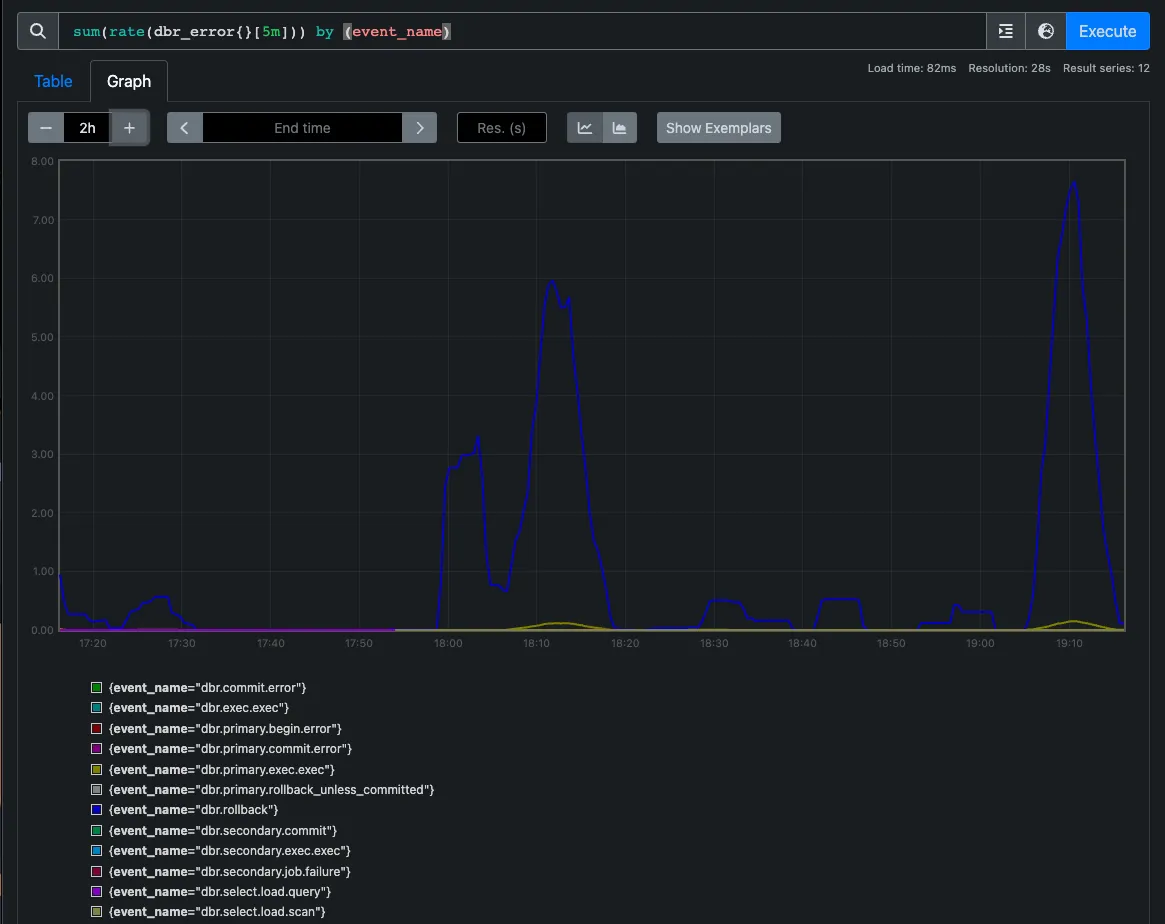
The graph above shows the database errors over a 5 minute period and the event_name label indicates whether the error comes from. Event names containing secondary come from the secondary instance and those containing primary come from the primary. With this in place, we were able to begin stage one of the DoltHub.com migration—double-writing to two database instances.
Enabling double-writes#
To enable DoltHub’s API to write to two databases simultaneously, we decided to fork gocraft/dbr as dolthub/dbr and change some of its interfaces and implementations to support a secondary database.
Originally, the dbr package defines Connection, Session, and Transaction abstractions that are aware of a single sql.DB, or database connection. To add a secondary database, we created multiplexed versions of each of these abstractions, “multiplexed”, here, meaning that these abstractions contain two instances of sql.DB. Each instance of a sql.DB in these structures is a connection to a database where one is the primary and one is the secondary.
In the original dbr implementation, when a query runs against a non-multiplexed abstraction, it executes once against a single database connection. With our new abstractions, when running a query, it executes against the primary database first, as it would normally, but then gets enqueued to run asynchronously against the secondary database.
As a quick example, here’s one of the methods we defined on a multiplexed Transaction:
func (txMpx *TxMpx) ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error) {
primaryRes, err := txMpx.PrimaryTx.ExecContext(ctx, query, args...)
if err != nil {
return nil, err
}
j := NewJob("dbr.secondary.exec_context", map[string]string{"sql": query}, func() error {
if txMpx.SecondaryTx.Tx == nil {
return ErrSecondaryTxNotFound
}
_, err := txMpx.SecondaryTx.ExecContext(NewContextWithMetricValues(ctx), query, args...)
return err
})
err = txMpx.AddJob(j)
if err != nil {
return nil, err
}
return primaryRes, nil
}During the call to ExecContext on the multiplexed Transaction, we see that first, the query is executed against the PrimaryTx, or primary transaction. Then, a new Job is created which, when run, will execute the same query against the SecondaryTx, or secondary transaction. This job is then enqueued with txMpx.AddJob(j) and the result from the primary transaction is returned as it normally would be.
This asynchronicity is crucial because it allowed us to prevent DoltHub.com users from experiencing any potential performance degradation during the migration process. We wanted to be very cautious about routing traffic to the secondary database too quickly. By queuing up queries to run against the secondary, DoltHub.com could continue serving customers quickly from the primary database while, in the background, providing our team with valuable insights about how DoltHub.com would be affected by running against Hosted Dolt.
After these changes to the ORM were in place, we wanted to be able to automatically and repeatably spin up a Hosted Dolt instance that mirrored our PostgreSQL instance. To do this, we created a tool to create a point-in-time copy of our PostgreSQL instance as a Hosted Dolt instance.
Translating PostgreSQL to MySQL#
The tool we came up with needed to perform the following steps:
- Connect to the PostgreSQL database and dump it.
- Translate the PostgreSQL dump into a MySQL dump.
- Connect to a Hosted Dolt instance and import the MySQL dump.
The first and last step are fairly obvious ones, but the second step may not be obvious for those less familiar with Dolt.
Dolt is 99.8% compatible with MySQL, meaning it can be used as a drop-in replacement for a MySQL database. Unfortunately, at the time of this blog, Dolt is not compatible with PostgreSQL, although, increasingly, customers are requesting this. This means that a PostgreSQL dump can’t be imported directly into Dolt. First, the dump needs to be transformed into the MySQL SQL syntax Dolt understands.
Fortunately, Tim and Zach provided a tool for performing such a transformation. The tool is called pg2mysql and rewrites PostgreSQL dumps as MySQL dumps. This makes migrating from PostgreSQL to Dolt much easier and so we integrated pg2mysql into the tool that copies our PostgreSQL instance.
We did encounter one interesting challenge when performing this transformation of the PostgreSQL dump, though. PostgreSQL doesn’t require lengths to be defined for its data types. So a table schema for a DoltHub.com table looks like this in PostgreSQL:
CREATE TABLE users (
id varchar primary key,
name varchar not null unique,
display_name varchar,
bio varchar,
url varchar,
company varchar,
location varchar,
updated_at timestamp,
created_at timestamp
);MySQL, on the other hand, does require lengths to be defined on data types, so this same table in MySQL and Dolt looks like this:
CREATE TABLE users (
id varchar(36) primary key,
name varchar(32) collate utf8mb4_0900_ai_ci not null unique,
display_name varchar(255) collate utf8mb4_0900_ai_ci,
bio varchar(5000) collate utf8mb4_0900_ai_ci,
url varchar(2048),
company varchar(255) collate utf8mb4_0900_ai_ci,
location varchar(255),
updated_at timestamp,
created_at timestamp
);However, the pg2mysql tool won’t automatically determine the proper length needed for each varchar or other data type that requires an explicit length when performing the transformation. I believe the tool defaults to using the maximum length for each data type in the resulting transformed dump. The tool also won’t add specific collations to columns if those are required, like they are in the above schema. So, unfortunately, we couldn’t use pg2mysql for transforming a PostgreSQL dump containing the PostgreSQL database schema. But we did use it successfully for transforming the dump containing just the data.
In order to translate the PostgreSQL schema into the MySQL/Dolt schema we needed, we manually defined DoltHub.com’s schema in a series of SQL files. We then embedded a copy of these files into the container that runs the PostgreSQL copy tool, and executed those files against the Hosted Dolt instance in order to set up the schema there. Once the schema existed in the Hosted Dolt instance, we simply imported the transformed data dump from PostgreSQL into the Hosted Dolt instance and committed our changes.
This copy tool was an invaluable resource for us during this process as it lowered our iteration cycles and helped us get relevant changes onto our secondary instance quickly.
Overcoming Dolt’s transaction isolation limitations#
Once we had a Hosted Dolt instance live and DoltHub’s API running in double-write mode against it, our next task was to rewrite portions of the API that relied on the SQL transaction isolation level serializable, which is supported by PostgreSQL, but not yet by Dolt.
The PostgreSQL docs summarize this SQL standard as stating that “any concurrent execution of a set of Serializable transactions is guaranteed to produce the same effect as running them one at a time in some order.” When originally written, DoltHub.com’s API code took this transactional guarantee for granted in a number of contexts.
One common pattern we relied on in DoltHub’s code was querying one set of data in order to update a different set of data.
For example, when DoltHub ran on PostgreSQL, its API allocated organization and user names out of the same namespace. Because transaction isolation level serializable was set in every DoltHub.com transaction, the API did not need to explicitly model these allocated names. This meant that if you were to create an organization named foobar, let’s say, the application would query the users table and assert that no user with the name foobar existed. If it did not exist, you could have successfully created the organization foobar.
This transaction isolation does not yet work in Dolt and the assumptions we made in DoltHub.com’s API, needed to to change to accommodate this. Without serializable transactions, the following two concurrent transactions would actually not conflict with each other in Dolt, where they’d normally conflict in PostgreSQL:
BEGIN;
SELECT * FROM users WHERE name = "foobar";
INSERT INTO organizations (name) VALUES ("foobar");
COMMIT;BEGIN;
SELECT * FROM organizations WHERE name = "foobar";
INSERT INTO users (name) VALUES ("foobar");
COMMIT;Because these two transactions don’t throw a conflict, if run concurrently, both user foobar and organization foobar would be successfully created, which is not what we want.
As a workaround in lieu of Dolt’s outstanding transaction isolation work, we modified DoltHub’s API code and table schema to artificially create conflicts at the appropriate times.
To fix the users and organizations shared namespace problem, we explicitly created a new table, users_organizations_normalized_names, which stores all user and organization names, lowercased, so that any attempts to insert a name that exists in this table fails, as expected.
Additionally, we updated a number of tables to include a row_lock bigint column. This column, which stores a randomly generated big integer, ensures that concurrent transactions cannot write to the same row without creating a conflict on this column.
At the time of this post, Dolt does not have row-level locking either, where row-level locking would prevent concurrent writes to the same row. The simple addition of our row_lock column provided us with much more confidence that DoltHub.com would be able to successfully process concurrent requests without winding up in a bad state.
Viewing history and making history#
Once we refactored DoltHub’s application code to work more responsibly with Dolt, we stood up our two database instances and began double-writing. What we experienced next was one of the coolest moments in our company’s history, and dare I say, in the history of database technology; for the first time ever, we logged into our Hosted Dolt Workbench and saw the diffs for live changes running against our database!
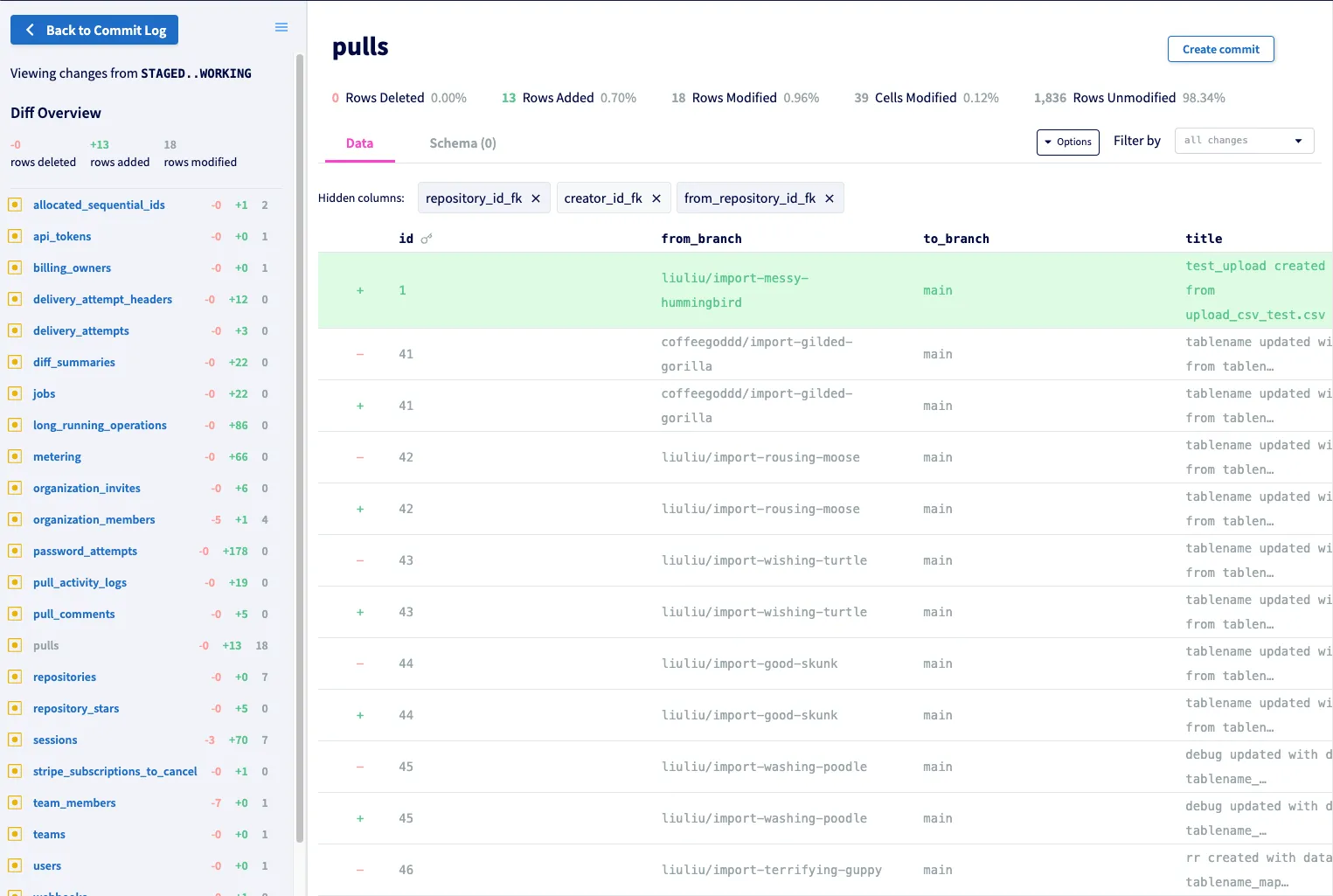
This was such a cool thing to see, and even more monumental for our team to see, considering just two years prior Dolt was primarily a data format. Now, it was clear, the future of database technology had arrived.
We decided to run in double-writes mode for a couple weeks in order to make sure we didn’t observe any issues with our secondary Hosted Dolt instance. Interestingly, at a certain point we found a bug by inspecting our live database diffs.
What we observed in the diff was that at some point, the foreign keys we’d defined for our tables had been dropped and we weren’t sure what caused it.
Resolving foreign keys#
To investigate the bug that caused our database to drop foreign key definitions without explanation, we spun up a fresh, Hosted Dolt secondary instance and turned dolt_transaction_commits on. Running a Dolt server in this mode will make every SQL transaction a Dolt commit. This allows us to see the diff of every SQL transaction in real time.
In this mode, we were able to view the Hosted Dolt Commit Log and isolate the SQL transactions that caused the foreign keys to be dropped. From there, we were able to come up with a simple reproduction so we could triage and fix the problem.
As it turns out, in Dolt, foreign keys are resolved after the first write occurs. In a new database created from an import, if foreign key checks are disabled and some tables are created that contain foreign keys, it’s possible for the resolution of the foreign keys during the first write to mistakenly drop the foreign keys during a merge of two branches. A super interesting edge case we encountered in our deployment, but totally possible to track down thanks to Dolt’s live diffing feature.
As a workaround to make sure foreign keys were no longer dropped, from then on, whenever we stood up a Hosted Dolt secondary, after importing the dump we’d run a no-op write query against all tables with foreign keys: delete from table where id != id;. This resolves all foreign key references and prevents them from being accidentally dropped in future merges.
Additionally, after enabling dolt_transaction_commit on our Hosted Dolt instance and seeing how cool the diffs were, we decided to leave the server in that mode indefinitely. But as we moved into the next stage of our database migration, enabling “double-reads”, we started seeing some unexpected behavior.
Persisting dolt transaction commits#
The first problem we encountered when running the server with dolt_transaction_commit on was that previously successful DDL statements began failing. We discovered this while attempting to import the PostgreSQL schema which had always previously succeeded. Now, when running a CREATE TABLE, the server was producing this error:
[mysql] 2023/03/20 17:56:11 packets.go:427: busy buffer
Error 1105 (HY000): foreign key `6pcso7ja` requires the referenced table `repositories`We also began observing that seemingly innocuous queries running against the server had large, unexpected latencies. In the server logs of the Hosted Dolt instance we saw that, at times, running START TRANSACTION alone could take up to 11 seconds to complete!
But, wouldn’t you know it, as soon as we disabled dolt_transaction_commit, these strange behaviors went away.
It was pretty cool to catch these bugs related to this server setting, especially before customers try running their production servers in this mode. We are currently in the process of prioritizing investigations and solutions around this server setting, so if this is a priority for you, definitely let us know!
Enabling double-reads#
To begin stage two of our plan, we made a few more alterations to our custom ORM so that reads would start running against both the primary and secondary instances. Before running in this mode, though, we also stopped performing writes to the secondary asynchronously. Instead, we created a way to “sync-at-commit-time”.
Recall that in double-writes mode, queries were executed against the secondary as background work and did not block the execution of primary queries. Before enabling double-reads, we continued to enqueue all secondary work asynchronously, but blocked all primary queries until all outstanding secondary queries completed. In other words, whenever a SQL COMMIT statement was run, the COMMIT against the primary would block until the COMMIT against the secondary completed, guaranteeing that all transactions would eventually be in sync.
We did this to make it clear to us whether a query we observed to be fast against the primary happened to be slow against the secondary. It also gave us more confidence that our secondary database wasn’t falling egregiously behind the primary, although we did expect some drift in data during the asynchronous double-writes stage.
The sync-at-commit-time changes landed in our ORM along with the changes to enable double-reads against both databases, and for the most part, everything worked really well. We did observe some performance issues on reads that made us rewrite some of our queries in DoltHub’s API, but those were easy to fix, and might be a better blog post for another day.
Keeping your data off the public internet#
Finally, we had all the pieces in place to fully shift DoltHub.com over to a Hosted Dolt instance in production. The double-writes stage went really well and uncovered some great bugs for us to squash, and the double-reads stage gave us confidence that the performance of DoltHub would remain as good as it has been on PostgreSQL. The last piece of the puzzle we wanted to place before flipping the Hosted Dolt instance from being the secondary database to the primary database was making sure the instance was not accessible on the public internet.
For context, Hosted Dolt is a managed Dolt service that allows users to run Dolt databases that we manage for them. Currently, connections to these databases occur over the public internet, and although extremely secure, we felt it prudent to take DoltHub.com’s Hosted Dolt instance off the public internet, just in case. An added benefit of doing this for DoltHub.com, though, was that it illuminated a credible path forward to make this an option for Hosted Dolt customers in the near future!
Today, when a user deploys a new Hosted Dolt instance, an AWS EC2 instance comes up with a public IP address that’s used for database connections. To make DoltHub.com’s Hosted Dolt instance private, we removed its public IP and set up AWS PrivateLink to allow only DoltHub API access to the instance.
We first created an Endpoint Service in the VPC of our Hosted Dolt instance. An Endpoint Service allows authorized Endpoints to communicate with specific targets within a VPC. So, we created an Endpoint Service and Network Load Balancer whose target is the Hosted Dolt instance for DoltHub.com.
Then, we created an Endpoint in the VPC that runs DoltHub.com’s services, including DoltHub’s API. After the Endpoint was created we linked it with the Endpoint Service and authorized their communication. AWS then provided us with a DNS hostname we could use from within DoltHub.com’s VPC that resolves to the Hosted Dolt instance, via PrivateLink. This was the first time any of us had used AWS PrivateLink, so it was pretty fun to get working.
Conclusion#
With the Hosted Dolt instance safely out of reach of the public we were finally able to go live with DoltHub.com running against Hosted Dolt as the primary, a historic day for this scrappy database startup.
One of the best parts of completing this project has been experiencing, first hand, how novel Dolt is, and how powerful it has become as an application database. It’s still hard to believe that it’s come so far in only two years, not to mention it’s only 5 years old, total!
I hope you enjoyed reading about our database migration and try migrating onto Dolt yourself. Database migrations are notoriously difficult to do and prone to errors and frustrations. Dolt makes migration much, much simpler. And, because it’s a versioned SQL database that’s a drop-in replacement for MySQL, it’s the last database you’ll ever need.
We love getting feedback, questions, and feature requests from our community so if there’s anything you’d like to see added in DoltHub, DoltLab or one of our other products, please don’t hesitate to reach out.
You can check out each of our different product offerings below, to find which ones are right for you:
- Dolt—it’s Git for data.
- DoltHub—it’s GitHub for data.
- DoltLab—it’s GitLab for data.
- Hosted Dolt—it’s RDS for Dolt databases.