
On its face, it’s hundreds of terabytes, millions of files, and trillions of negotiated rates between insurers and providers. But the health insurance data dump is probably smaller than it seems.
Back in July, health insurers published all their negotiated rates in a massive data dump. Coordinating the release of these prices took years of planning. Since then, think tanks, academics, and private companies have begun looking into this data, writing their own data pipelines and — with America being America — have also started to sell curated versions of this data for boatloads of money.
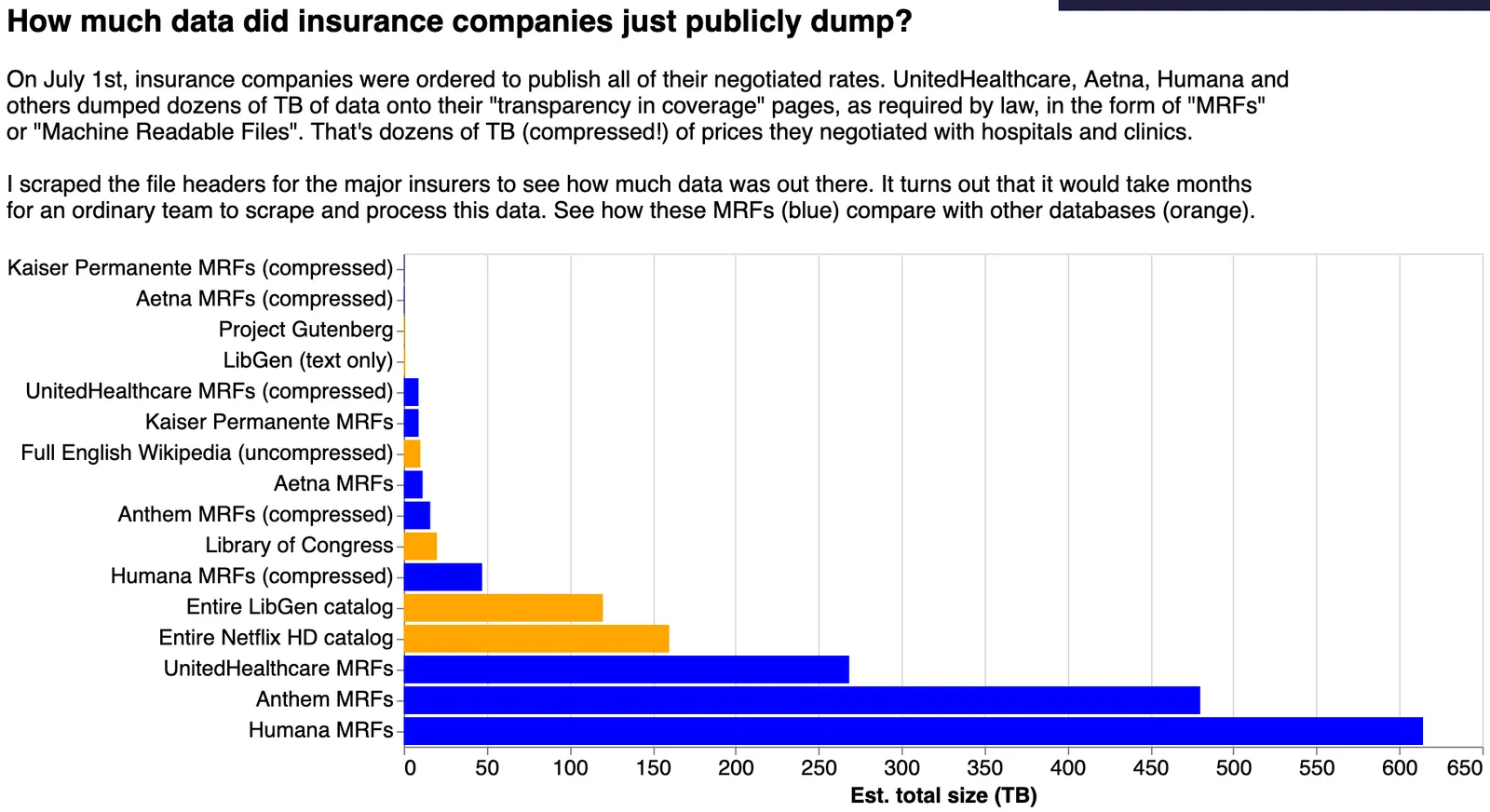 The original chart I made summing up the sizes of all the files
The original chart I made summing up the sizes of all the files
Businesses can charge that much because few people can make sense of a dataset this large. Taken at face value, it’s made of JSON files that can be up to a terabyte in size, full of URLs that themselves link to other URLs containing more JSON files. The dataset takes up dozens or even hundreds of terabytes.
Now, some questions:
- how much of this data is actually meaningful?
- how is it possible that there’s this much data in the first place?
We’ve started to be able to answer question (1) and the short of it is: only a fraction of the data applies to real life.
In our investigation of C-sections, we learned that because healthcare providers negotiate in groups. Every provider in a group technically can have a price for a service even if they don’t actually offer it.
That means in this dataset, OBGYNs have a rate for C-sections, but so do neurologists, ophthalmologists, and even physical therapists, probably because they are all part of the same contract. This means a lot of the data is probably junk.
Beyond the issues with junk, question (2) is answered by another point: redundancy. Here’s how we figured that out, and what we did about it.
A quest, for Quest#
Quest Diagnostics called me to ask if I had any special insight into the data, and whether we could somehow get it to them affordably. They didn’t need the entire dataset, just the subset of prices of lab tests from a specific set of hospitals.
We ended up with an experimental project model — we’d write the data pipeline and crowdsource the collection, and they’d fund the crowdsourced effort and the pipelining work.
Once we started collecting the data some patterns emerged.
The reason there’s so many prices in this dataset is because the vast majority are duplicated. And that makes sense: for there to be a trillion unique prices, every person on planet earth would need to be negotiating full time for US health-insurance companies (prices are not negotiated algorithmically, as far as I can tell.)
The duplicate prices show up in at least two ways.
Over duplication example: Anthem Blue Cross#
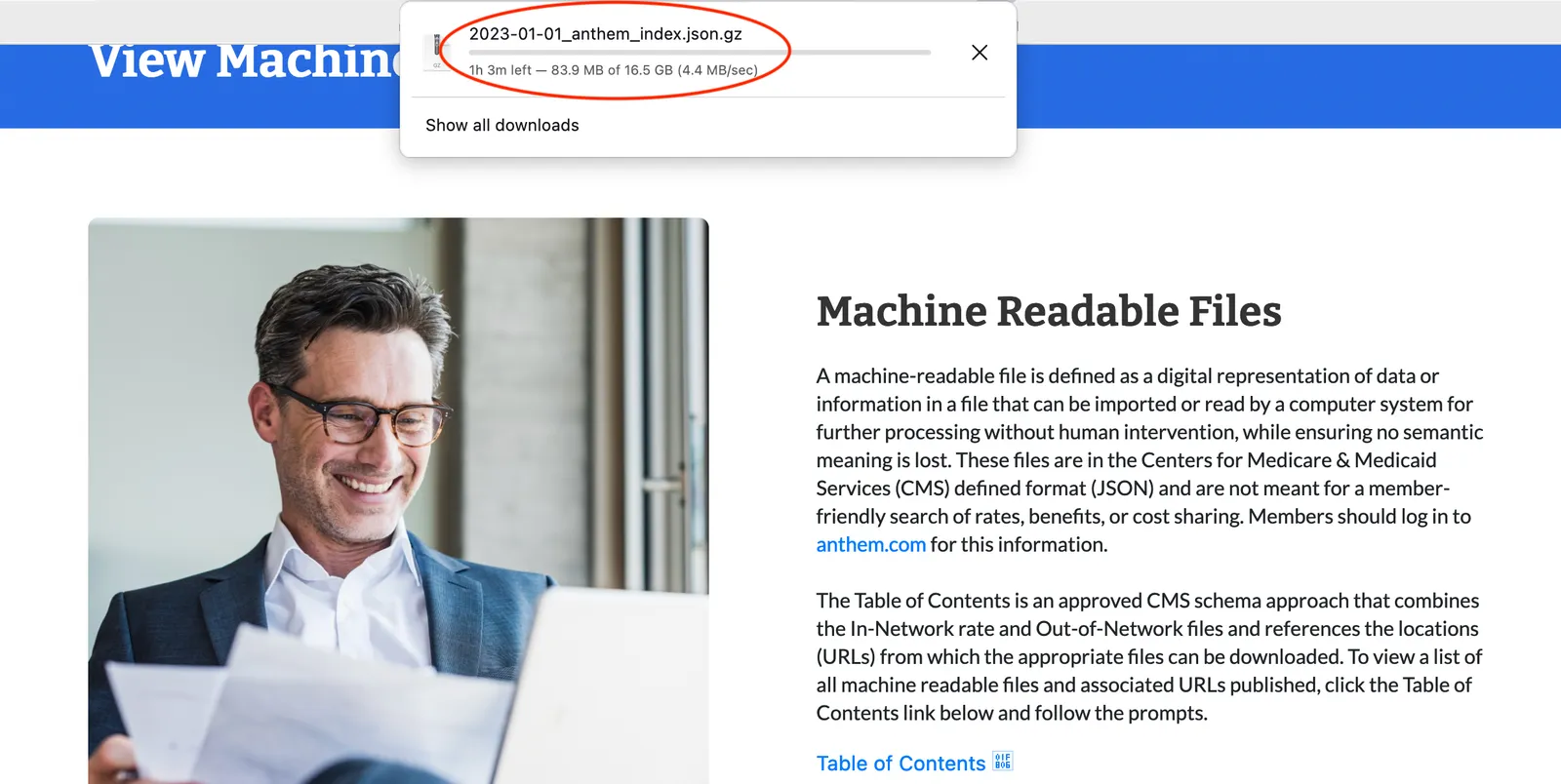
Anthem’s index file contains 66M URLs, each pointing to a fraction of the data that belongs to a specific insurance plan. When I originally wrote about this, I looped through the URLs and added up the amount of data stored in each one. But it was a mistake to assume that the URLs pointed to unique files. Our crowdsourcers, or bounty hunters, helped me notice something.
Not only are the URLs not unique — many URLs are duplicated in the list — here’s a sample of they look like:
| url |
|---|
https://anthembcbsct.mrf.bcbs.com/2023-01_400_59C0_in-network-rates.json.gz |
https://anthembcbsva.mrf.bcbs.com/2023-01_400_59C0_in-network-rates.json.gz |
| … |
https://anthembcbsga.mrf.bcbs.com/2023-01_400_59C0_in-network-rates.json.gz |
Example of the URLs. These are not clickable — they require a token (querystring) for the download to initiate.
Each state shares plans with every other state. The total number of unique files is only around 1500 or so, just a tiny fraction of the 66M I originally estimated.
The Anthem files themselves contain some junk.
The fields in the JSON give plenty of latitude for price variation: the location of the service, the provider group, etc. But many times, we find prices which vary (same hospital, same procedure, but many different prices) and no way to disambiguate them.
How does this happen? Does Anthem itself not know what its prices are?
Hidden duplication example: United HealthCare#
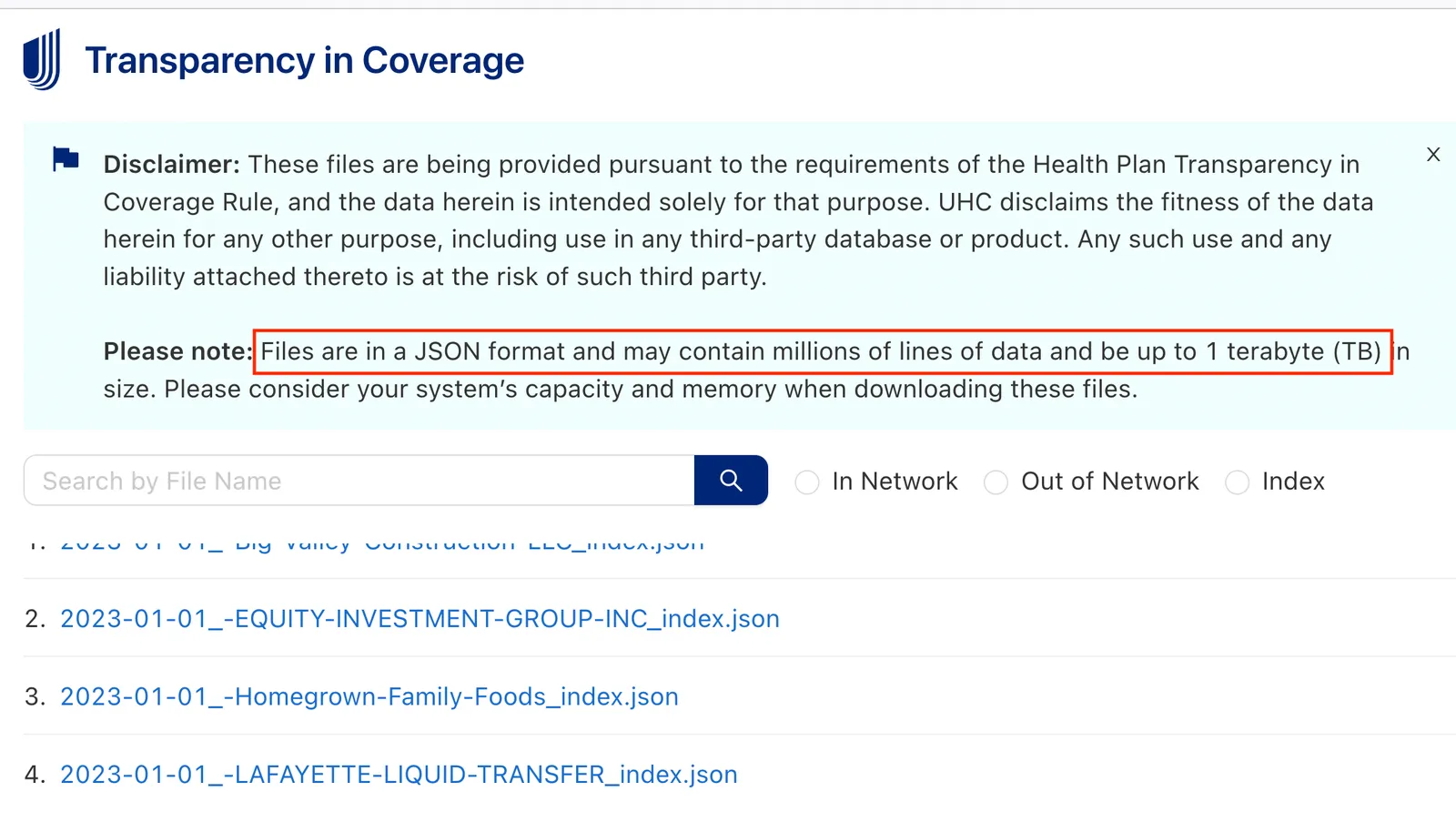
United HealthCare lists around 55,000 files for download, but the data is mainly in the in-network-rates files. There are only about 4,200 of those — the rest are just pointers to those files, or do not contain rates.
Of these, 2,700 of them are plans that are just administered by United (United processes the claims, but the insurer is actually some other entity, usually an employer.) In these cases United is said to be a TPA — a Third Party Administrator.
Being a TPA, United sets the rates and handles claims, but doesn’t do the actual insuring. Instead, the employer gets the premiums and pays out the claims. We expect to find that UHC sets the rates once, then applies these rates to the various plans that they TPA for.
We find evidence for this in the data, that code-price combinations for TPA’d plans do indeed repeat. In fact, tons of the insurer prices repeat. This gives us some leeway for designing an even better schema.
Strategies for deduplication#
Now that we know that lots of plans can have the same prices, we can make prices the first-class citizens of our schema, rather than plans. That requires a rethinking of our old schema.
On our second try, trying to be as efficient as possible with the tables, we came up with this:
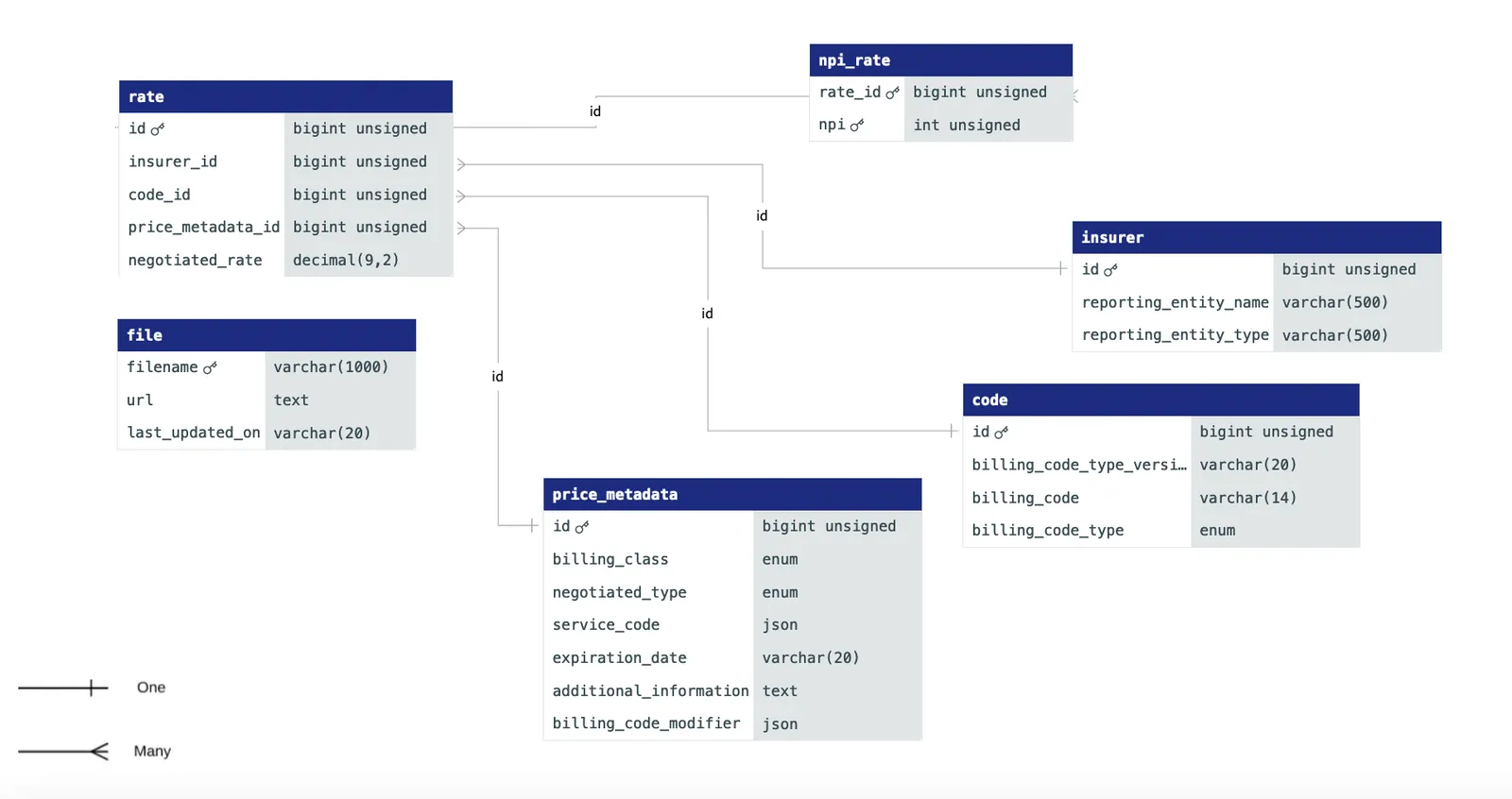 The ER diagram for our latest schema. See more here
The ER diagram for our latest schema. See more here
forgetting about plan information altogether, and lumping all insurer data together in a single table indexed by just the name (United of Colorado, Anthem, etc.)
The future#
Our story in trying to make this data not just open, but understandable, continues.
We’ve launched a data bounty to build a smaller version of this dataset (expected to be around 10GB, instead of > 1TB as before) as we fine tune our schema and data-collection pipeline.
It’s a shame this is as tricky as it is to do, because this data affects you, and the fact that this data takes so much time and energy to wrangle is definitely stalling marketplace action.
Before, you could call your insurance company and ask them what you might pay for some future doctor’s visit, but they didn’t have to tell you and usually didn’t.
Now, thanks to the new transparency laws you could (at least in theory) get the rate your insurance company negotiated with your provider, and do something with that information, like find a better plan, or switch companies.
The easier you can use this data, the more pressure there will be on insurance companies to converge on, or even lower, prices. With healthcare making up 20% of GDP, every bit counts.
If you’re interested in talking to us, come find us on Discord.
Comments, questions, suggestions? Reach me at alec@dolthub.com.