
Health insurers just published close to a trillion hospital prices#
On July 1, insurance companies started dumping an absurd amount of data onto the internet. No one appreciates the scale of it.
I scraped the headers for hundreds of thousands of files from Humana, UnitedHealthcare, Aetna, and others. Compressed, the the sum total of the data they’re offering up weighs in at around 100TB. That data, uncompressed, the data runs into the petabyte range, dwarfing the Library of Congress, the LibGen catalog, the full uncompressed English Wikipedia, and the entire HD Netflix Catalog — combined.
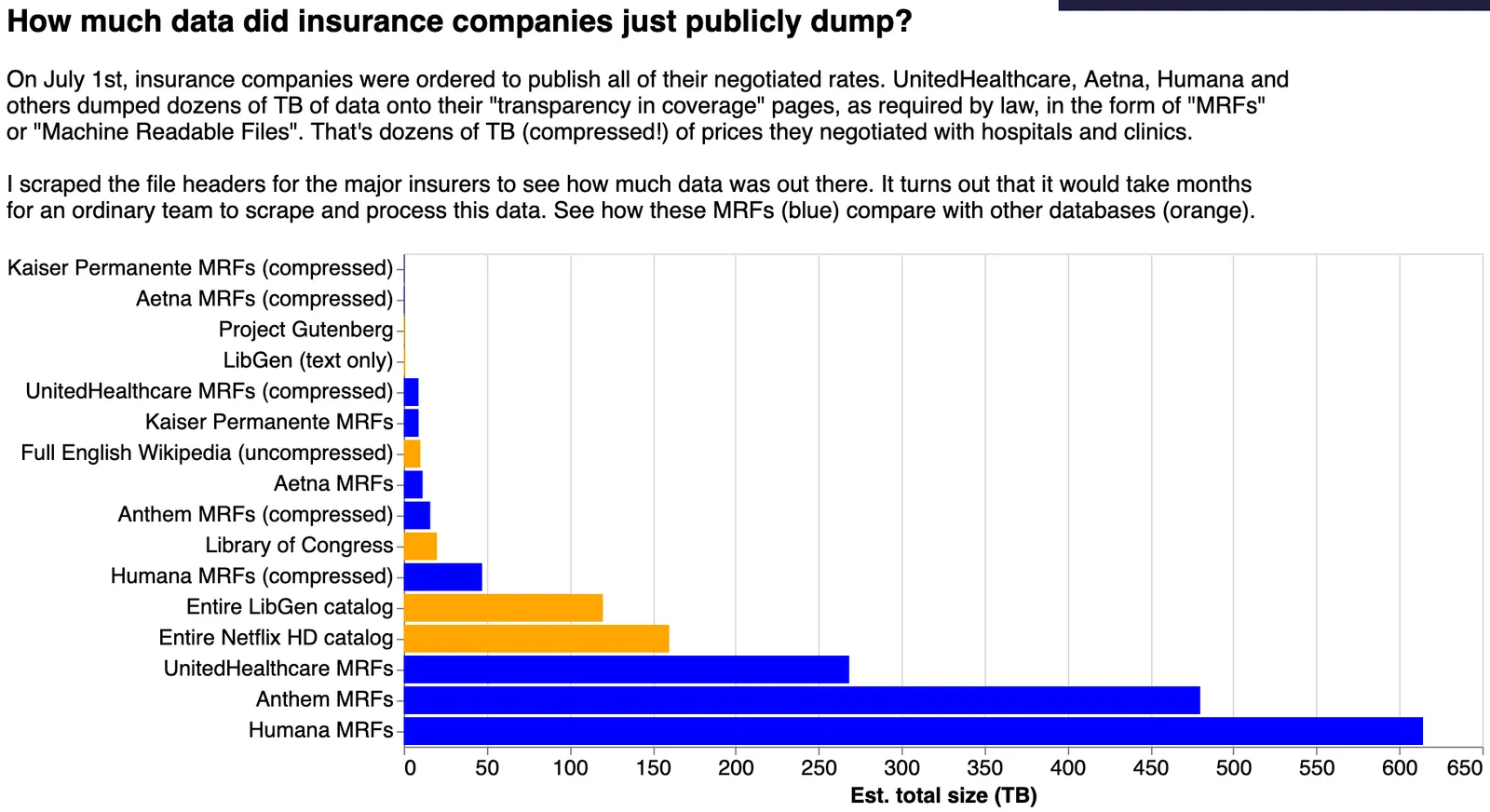
Note: if you’re inclined to reproduce this chart, you can do it yourself by running the scrapers I provided in this GitHub repo. You can use it to get the file sizes you see above, as well as get URLs of all the files if you want to try to download some of them.
Everything has a price#
In the newly-released data, each “negotiated rate” (or simply “price”) is associated with a lot of metadata, but it boils down to: who’s paying, who’s getting paid, what they’re getting paid for, plus some extra fluff to keep track of versioning. The hundreds of billions of prices in the dataset (probably over a trillion) result from all the possible combinations of these things. Codes can have different types, or versions. Prices can have service codes. And so on.
And because prices change, the insurers release new versions of these 100TB files monthly.
Fermi math#
I naively thought that insurers would be publishing the prices they negotiated with the 6,000 hospitals in the US. I was wrong.
A back-of-the-envelope calculation gets me a rough estimate of over 500B different prices, simply from counting how many prices are in each file, multiplying by the number of files. But this is just from the handful of insurers I scraped (and who were in compliance.) All told, the total number of prices could reach over a trillion.
That’s because the data dumps include the negotiated rates with every entity that the insurance companies have contracts with. It’s impossible to say how many there are without going through the “in network” files directly, but a cursory look suggests that there are millions.
Humana dumped nearly half a million compressed CSV files totaling 50TB compressed (~600TB uncompressed.) At around 70k prices per 9MB file, this translates into about 400 billion individual prices negotiated with different providers.
Other payers are similar in their largesse. On UnitedHealthcare’s page they list over 55,000 individual files for download. Together these make up 9TB of compressed JSON, or around 250TB uncompressed. By estimating how many prices there are per GB of compressed JSON, I estimate they’ve alone published around a 100 billion prices.
Too much of a good thing#
The industry opposed releasing the data under the new price-transparency law. In the past, it was nigh impossible for employers to know how much their insurance companies agreed to pay. So in theory, employers can use the new data to get a better deal. But in order to use it, they’ll need to get it. And that’s the problem.
There’s just so much data. To scrape the data you’ll need to be sure to have a business-level fiber-optic connection that can handle 400Mbps, tens of thousands of dollars of disk space, and compute time to wrangle 90GB JSON blobs.
But maybe we can solve a simpler problem first.
A path forward#
Maybe we won’t be able to get all this data into one database. (As an aside, it’s not clear why the CMS, who helped write the law, didn’t build this database themselves directly from the insurance company data.)
But we have options:
- For this database to be useful, we don’t necessarily have to look at every procedure, nor every provider. Foregoing the extra information of them can cut down the space constraints by more than 100x.
- Similarly, as we did in our past data bounties, like gathering prices from nearly 2,000 hospitals, we can spread out the effort and resources by running this as a distributed challenge.
- We can make custom tools like this one for splitting huge JSON blobs into JSONL files.
- We can filter down the NPIs (“national provider identifier”) to those major hospitals that we’re interested in by using the CMS’s own data.
- We can limit ourselves to just those 70 codes required by the CMS.
We think that this data deserves to be in the public hands and we’re working on making it a possibility.
If you have comments, questions, or ideas — or just want to say hello — write me at alec@dolthub.com.