Cozy Data

Today, I want to talk about a new term that I just invented but feel certain is destined for fame or even infamy: cozy data.

To introduce what I mean by this groundbreaking concept, I think it's easiest to come at it sideways by describing an opposite concept, big data.
Big data
By now everyone has heard of big data: those unending reams of facts and figures generated by business processes. It's usually represented by an abstract figure of glowing futuristic figures floating in space, futuristically, like this one.

Sometimes you mine big data from rich veins of data deep inside a data mine. Once you have it, you stack it into data warehouses, or maybe slough it into data lakes. Eventually an analyst comes along and writes a 3-page SQL query against it to use in a presentation or a dashboard. There are even data lake houses now, but your guess is as good as mine what they do.

So what characterizes big data?
Big data is big. Obviously. There are petabytes or even exabytes of data in a big data store. Sometimes mere terabytes makes the cut, but that's the limit: any less and we'd be forced to call it medium data or at least not-very-big data.
Big data is impersonal. It's cold. Because big data is so big, because there's so much of it, it's impossible to care about any individual piece of it. It doesn't even make sense to examine individual data points in a big data set, only to address them in the aggregate. The data in big data are cattle, not pets.
Consumption of big data is intermediated by software. A human examining big data can only make sense of it via layers of abstraction in software, typically SQL or some other query language, or increasingly via a machine learning pipeline. But a human would never scroll through pages of big data, reading it with their weak human eyeballs. There would be no point, nothing to be gained.
Cozy data
I want to propose a new term diametrically opposed to big data: cozy data. If big data is best illustrated by glowing numbers floating in space, cozy data is best illustrated by a well-loved collection of collectible trading cards.

Cozy data is at least as much a vibe as a firm definition, but let's talk about some of its characteristics.
Cozy data is small. In particular, cozy data is small enough that a single person can say they understand all of it. They might not be able to recall every point in the data set, but they know the basic layout of the data and how to locate any particular element quickly. There's no upper limit in terms of storage size, but in terms of entries call it hundreds of thousands at most, and usually no more than thousands.
Cozy data is personal. You have a relationship to all the entries in a cozy data set: they mean something to you or anyone else you would choose to share the data with. You would notice if any entry had a typo and consider it worth fixing. When you look at any entry you're flooded with associations and memories of what it means to you.
Cozy data is for direct human consumption. You can query a cozy data sets if you want, but it's also pleasant to leisurely pore over it item by item or page by page. The entries often make sense and are interesting to examine in isolation, or can be arranged into narrative subsets that you read like a book.

The coziness of a data set isn't just about size: it's about your relationship to the data. If you care about each entry, it's cozy, regardless of how big or small it is.
Let's look at some examples of cozy data.
Photo albums

One of the coziest forms of cozy data, a photo album is a curated selection of special memories that are deeply meaningful to the people who assemble it. These days photo collections tend to be digital rather than physical, and in many cases have ceased to be cozy -- think of scrolling through endless photos on your phone looking for a particular one you took. This is a great example of how the scale of data can push it out of cozy territory. The inflection point is where you have so many photos that you need software (with features like face recognition) to find anything you're looking for. But it also comes from lack of curation: if your photo collection never goes through a process of culling to leave just the ones you care about, it's probably not cozy.
Contact lists

One of the most personally meaningful data sets anyone has is their list of friends and acquaintances, usually including information like their full name, their contact info, and sometimes tidbits like their birthday, favorite colors, etc. These days everyone in Western countries delegates this list to software at some stage in their lives, but not that long ago it was usually stored on paper and guarded as the precious treasure it is. The relatively small size and personal nature makes this data extremely cozy.
Collections

People collect almost anything you can think of, and almost all of these collections are examples of cozy data. Some of them, like Pokemon cards or other collectible card games, lend themselves especially well to expression as pure data, where the physical objects being collected are almost superfluous. For others, like the rock collection above, the data is more like metadata describing each element in the collection. And it's often collected only in the coziest data store of all: one person's mind.
Fandoms

Fandoms are communities of avid devotees to some hobby or cultural product, and they usually pour a lot of collective energy into cataloging every aspect of their interest into some digital form like a wiki. Each of these compilations are cozy data, and can be truly staggering in their attention to detail.
Sports statistics
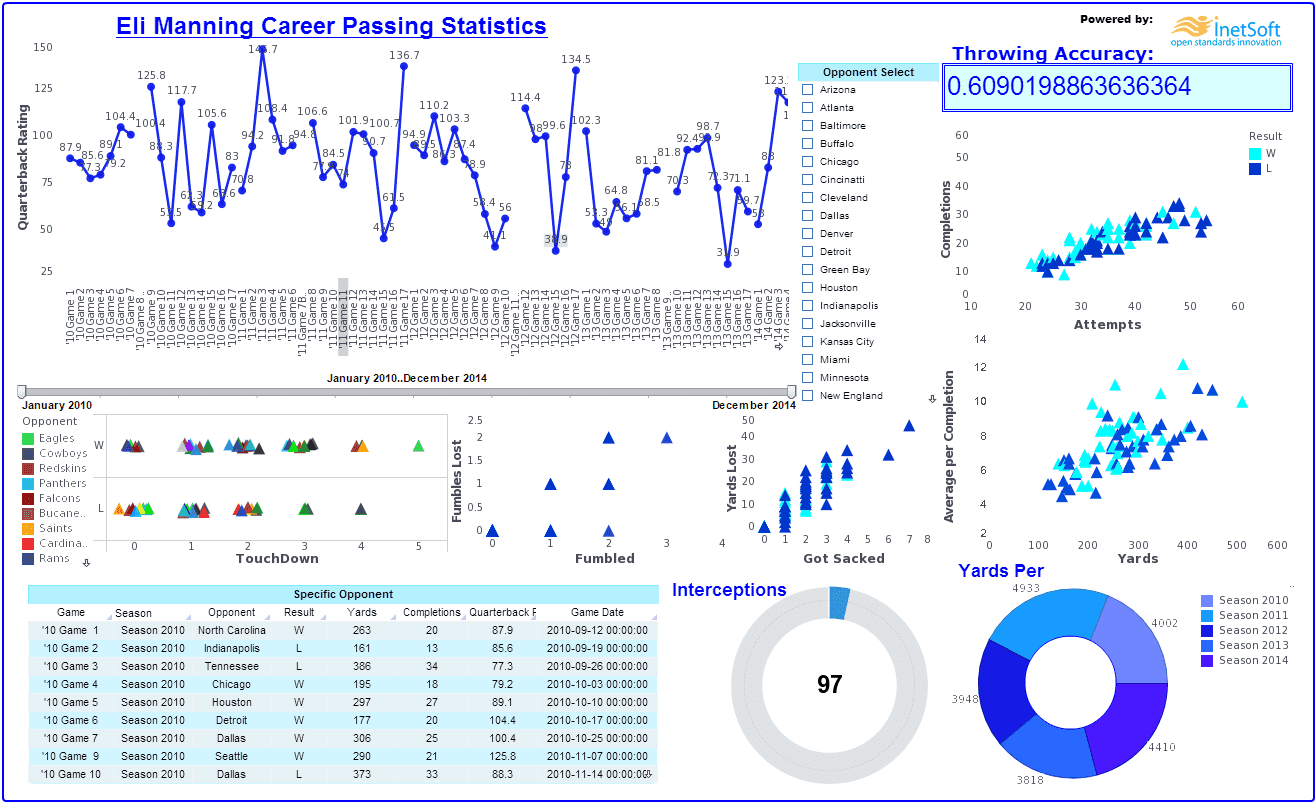
Sports fans are a form of fandom, although many would object to that classification. Unlike most fandoms, most sports lend themselves really well to objective, quantifiable data that we call statistics. The curation and study of these statistics broken out by player, team, game, etc. is a full-time pursuit just as enjoyable as watching the games for many fans. It's not uncommon for hardcore baseball fans to be familiar with the stats for every player on their favorite team going back decades. Therefore sports statistics qualify as cozy data.
Working with cozy data
Cozy data is important because it's meaningful, by definition. This means that the stakes are high when thinking about losing or destroying it. Ideally, when dealing with cozy data, you want the tools that store and modify it to have the following properties:
- Durability. You want your data to survive your computer dying in a literal fire, so it needs to be backed up somewhere else that isn't your house. That place has the same problem: it needs to be able to survive a meteor strike on a data center. But most cloud backup providers make these guarantees.
- Version control. More common than house fires are what we can broadly call human error. You or your child or cat could accidentally delete a crucial bit of data, whether it's an important photo or a contact you don't have saved elsewhere. When you mess up, you need to be able to undo the change.
- Sharing. Some of the best, coziest data is meant to be shared with other people. For a lot of categories of cozy data, especially fandoms, you really want to be able to collaborate with other people on it. Ideally, the collaboration tools will gracefully deal with social dynamics that affect groups over time, things like power struggles, schisms, etc.
For most domains of cozy data, there are platforms to host it that have all these features, and you should find and use one tailored to that use case.
But if you've been meticulously curating your cozy data by hand on your PC, we have some good news for you: there's a free, general-purpose tool that's probably better than what you've been doing.
DoltHub: the world's best platform for cozy data
We're building Dolt, the world's first SQL database with Git-like version control. It's the perfect tool for storing and sharing human-scale cozy data, and it's free and open source. You can host your Dolt databases on DoltHub for free to get a web GUI to view the data and keep it up to date, plus a bunch of useful collaboration features like pull requests and forks. If you have cozy data you're maintaining by hand, you should really give DoltHub a try!

Some of our favorite use cases for DoltHub involve people storing and sharing their cozy data. Here are some samples:
- Steve Waldman was hosting a SQL database of FRED financial data on his own computer, a personal project from data he'd scraped. He revived the decade-old project to put it on DoltHub to share.
- Our CEO is a sports fan, and has several sports statistics databases he curates and shares. This one is about shot data from the NBA.
- User
belliaspanhas forked a github project collecting baseball statistics to make it queryable online. - User
cmooghas a hobby of collecting crash and crime statistics from Chicago and putting it in queryable format on DoltHub. - User
redstallionhas assembled an impressive list of board games and all sorts of metadata associated with them.
There are lots of other examples -- these are just ones that I pulled by skimming recent updates to databases. And of course, lots of people are hosting non-cozy data on DoltHub, things like financial data and the price of various medical procedures.
Do you have cozy data that needs a home? Why not try DoltHub?

Conclusion
Intrigued by cozy data? Think the whole concept is stupid? Want to learn more about Dolt? Come talk to our engineering team on Discord. We're always excited to meet and learn about new users.