
In early October we released DoltHub Jobs, our latest backend change to DoltHub that lets DoltHub handle large, long-running write operations like file import and pull-request merge. We also recently released DoltLab v0.7.0 which includes support for Jobs, albeit just the file import Job for now. This blog will cover how we designed Jobs for both DoltHub and DoltLab and will provide you insight into how DoltLab Jobs will affect your DoltLab instances moving forward.
For those unaware, DoltHub and DoltLab are two versions of the same product. In fact, they share the same source code. The two main differences between the pair are that, first, DoltHub is the web interface we host for you, whereas DoltLab is the web interface you host yourself. And second, DoltHub runs on multiple hosts in Kubernetes, where DoltLab runs in Docker on a single host. Otherwise, with some slight differences, they’re fundamentally the same.
For this reason, until the introduction of Jobs, the differences between the single host configuration of DoltLab and multi-host configuration of DoltHub, weren’t large enough to be felt by DoltLab users who expect to get the full power of DoltHub when they boot up DoltLab. However, as you’ll see below, we’ve boosted the power of DoltHub quite substantially by adding Jobs. Jobs leverage DoltHub’s multi-host environment to perform intensive write operations across the platform.
DoltLab v0.7.0 also uses Jobs, but because DoltLab runs on a single host (for now 🤠), harnessing the full power of DoltLab requires vertically scaling the host with additional memory and disk so it can successfully perform long-running, intensive write operations. To get a better idea of what’s going on behind the scenes, let’s look at how Jobs work for DoltHub and DoltLab.

DoltHub Jobs#
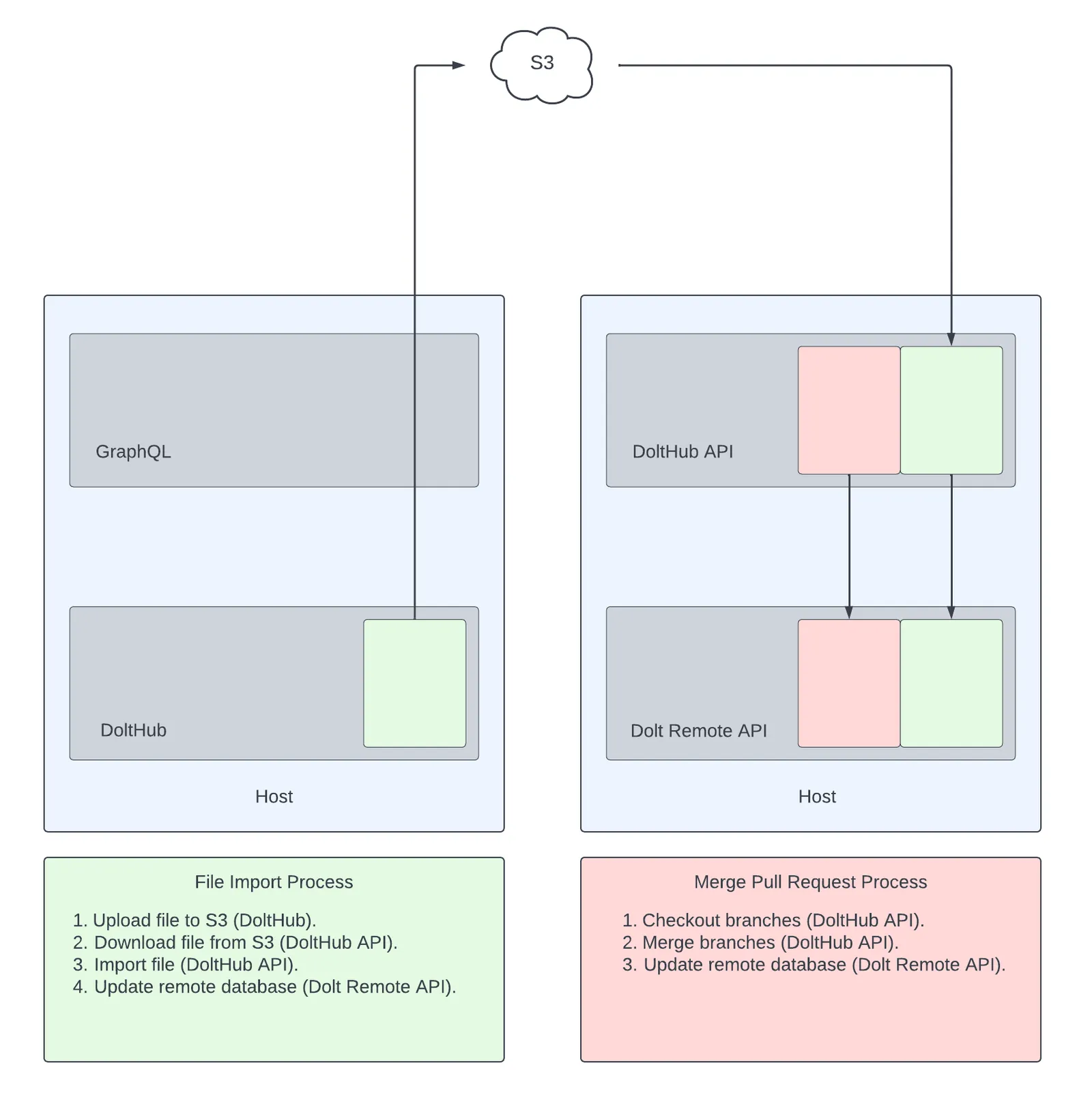
This illustration above shows DoltHub’s services before the Jobs implementation. In this architecture, multiple DoltHub services run across multiple hosts and interact with cloud services like AWS S3. Before Jobs were added, uploading a file on DoltHub followed the steps written in “File Import Process”, and most of the resource intensive steps in the process occurred in DoltHub API. This was also true for DoltHub’s “Merge Pull Request Process”, and for this reason, we capped the size of file uploads on DoltHub to around 270 MBs and large pull request merges would often time out; there’s just wasn’t enough shared memory in DoltHub API to go around.
This next illustration shows how these processes have changed with Jobs.
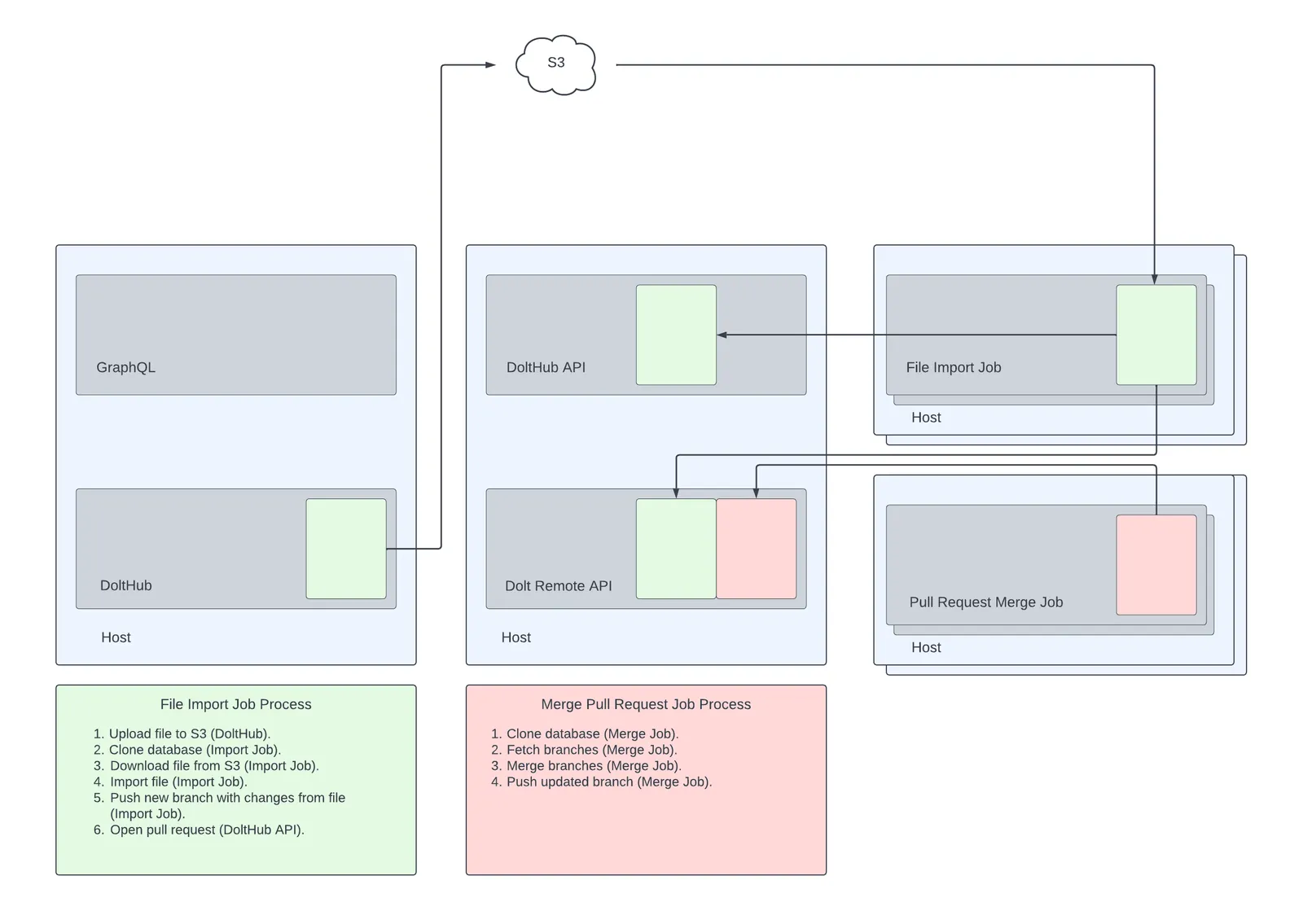
As you can see, now when a file upload occurs, or when a pull-request merge is triggered, new hosts are spun up that run Kubernetes Jobs responsible for doing the file import work or pull request merging work independent of DoltHub API. This means that there is far less resource contention in DoltHub’s API, and each Job can use as much memory and disk as it needs to, without starving a different service.
We implemented this by adding a Kubernetes client inside DoltHub API that deploys these Kubernetes Jobs and heartbeats them until they complete. Once they’re complete, any resources used during the run of the job are freed and the hosts that were spun up are automatically deprovisioned.
DoltLab Jobs#
As I mentioned before, DoltLab runs the same basic suite of services as DoltHub, but does so on a single host using Docker. Each DoltLab service runs in a Docker container on the same Docker network. To implement Jobs on DoltLab, we performed some Dockerception™ by using a Docker client, within DoltLab API’s Docker container, to launch… more Docker containers! Specifically, the containers that run DoltLab Jobs.

As you can see below, the setup looks very similar to DoltHub Jobs.
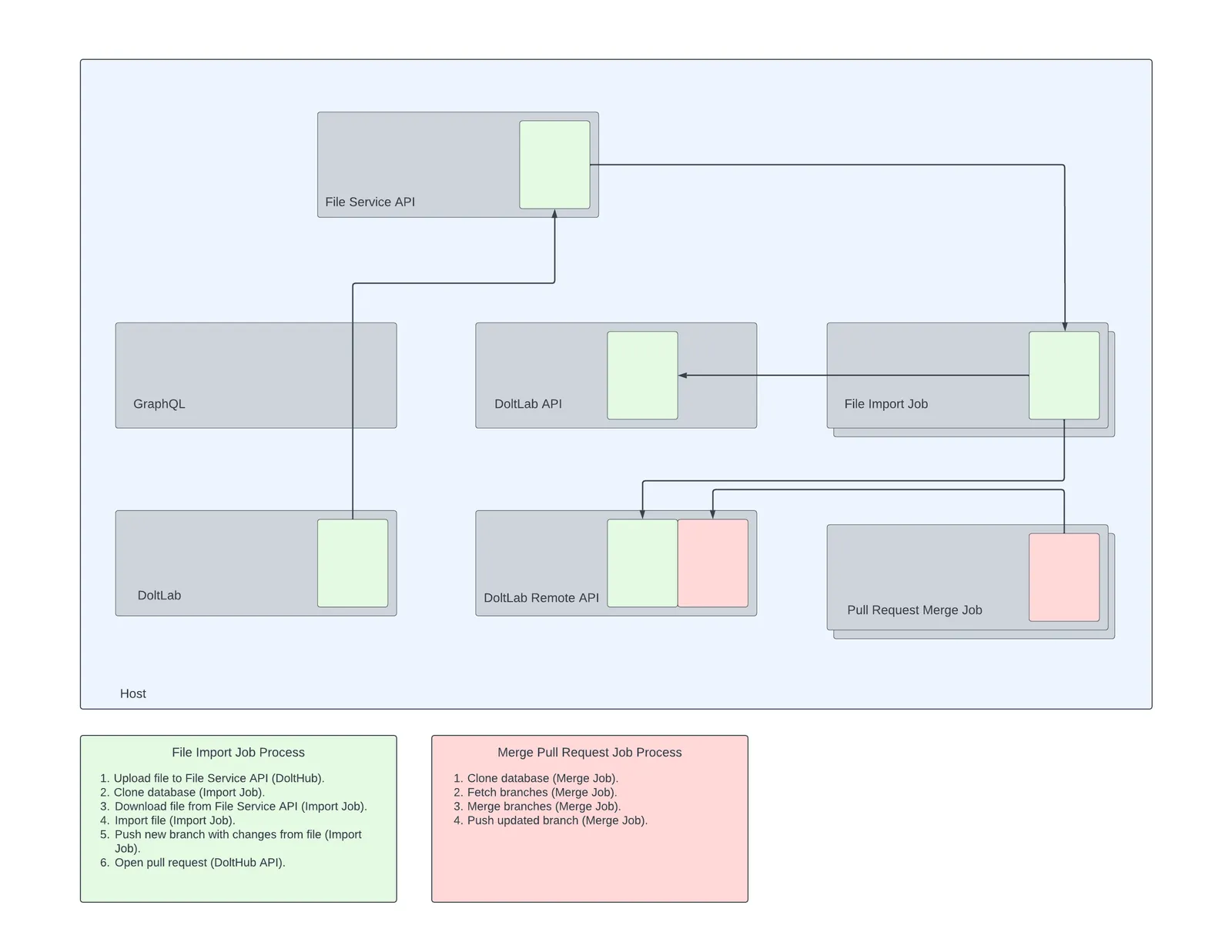
For DoltLab, S3 is replaced with DoltLab’s File Service API, but otherwise, the “File Import Job Process” and “Merge Pull Request Job Process” are the same. The important thing to note, though, is that because DoltLab runs all of it’s services on one host, even though the Jobs aren’t competing for resources in the API process anymore, they’re still competing for host resources generally. For this reason, we recommend (depending on your use case) increasing the amount of disk and memory you provision on the host machine you use for DoltLab. Doing this will enable you to leverage DoltLab’s new Jobs processes to a greater extent.

Jobs and Beyond#
Despite Jobs being fairly resource intensive at the moment, we’re extremely excited for the positive impact Jobs will have on the future of DoltHub and DoltLab.
Firstly, Jobs are helping us make our products better, faster, and less resource intensive, in that they incentivize our team to work toward improving Dolt performance. By this I mean that Jobs act as another way for us to “dog food” Dolt. Under the hood, each Job is actually a dolt binary running a series of commands to perform its assigned task.
File import Jobs run dolt clone, dolt table import <file> or dolt sql < <file> (depending on the file type), and dolt push. Pull request merge Jobs run dolt clone, dolt fetch <remote> <branch>, dolt merge <branch>, and dolt push. So when these Jobs use large amounts of memory and disk, it’s really because Dolt is using that memory and disk and we now have a front row seat to see how Dolt is performing in this Jobs context. By building Dolt into such an integral piece of DoltHub and DoltLab’s infrastructure we are enabling our team to spot problems quickly and get them fixed quickly. To this point, we just launched Jobs and are already underway with improvements to Dolt to make import performance much better.
Secondly, Jobs are a foundational piece of infrastructure required for supporting “Dolt your snapshots,” an automated process for backing up your current database’s snapshots with Dolt. In 2023, we’ll be launching an automated process on DoltHub that let’s you keep your legacy database, but version and diff its snapshots on DoltHub! We’re hard at work to make this a reality so stay tuned for updates.
Conclusion#
We love getting feedback, questions, and feature requests from our community so if there’s anything you’d like to see added in DoltHub, DoltLab or in one of our other products, please don’t hesitate to reach out.
You can checkout each of our different product offerings below, to find which ones are right for you:
- Dolt—it’s Git for data.
- DoltHub—it’s GitHub for data.
- DoltLab—it’s GitLab for data.
- Hosted Dolt—it’s RDS for Dolt databases.