A single database for every museum: a retrospective

About DoltHub data bounties
Anyone can build a database given enough time.
But at DoltHub we build databases in a distributed way, using a unique database, Dolt, that works like Git. Dolt is cool because you can create branches, make pull requests, and revert changes, but on a database instead of a codebase.
For our data bounty program we set a prize payout, then allow anyone with an account to make pull requests to our database. If the PR gets accepted, they get a part of the prize (usually $10-15k).
The bounty program has helped us build databases that would have been a lot of work for a single specialist, since we have access to all the skills of our participants combined: search capability, fluency in multiple languages, or insider knowledge, to give a few examples.
Even though bounties are still in beta, we've built some interesting databases so far: hospital prices, businesses, and housing prices(which is ongoing.)
Recently we tried to build a database that tracked objects in every museum in the world. We wanted a unified museums database where anyone could search for artifacts, paintings, historical objects -- or whatever they could dream of -- and find it in our table.

White underwear, "C. 20th Century CE", object_number AM-NPC-874-1 from the Allahabad Museum. Found with select * from objects where title like "%underwear%".
While it's impossible to truly get every object from every museum, let's see how we did.
Stats
We made heavy use of webscraping museum pages and hoovering up the data from museum APIs.
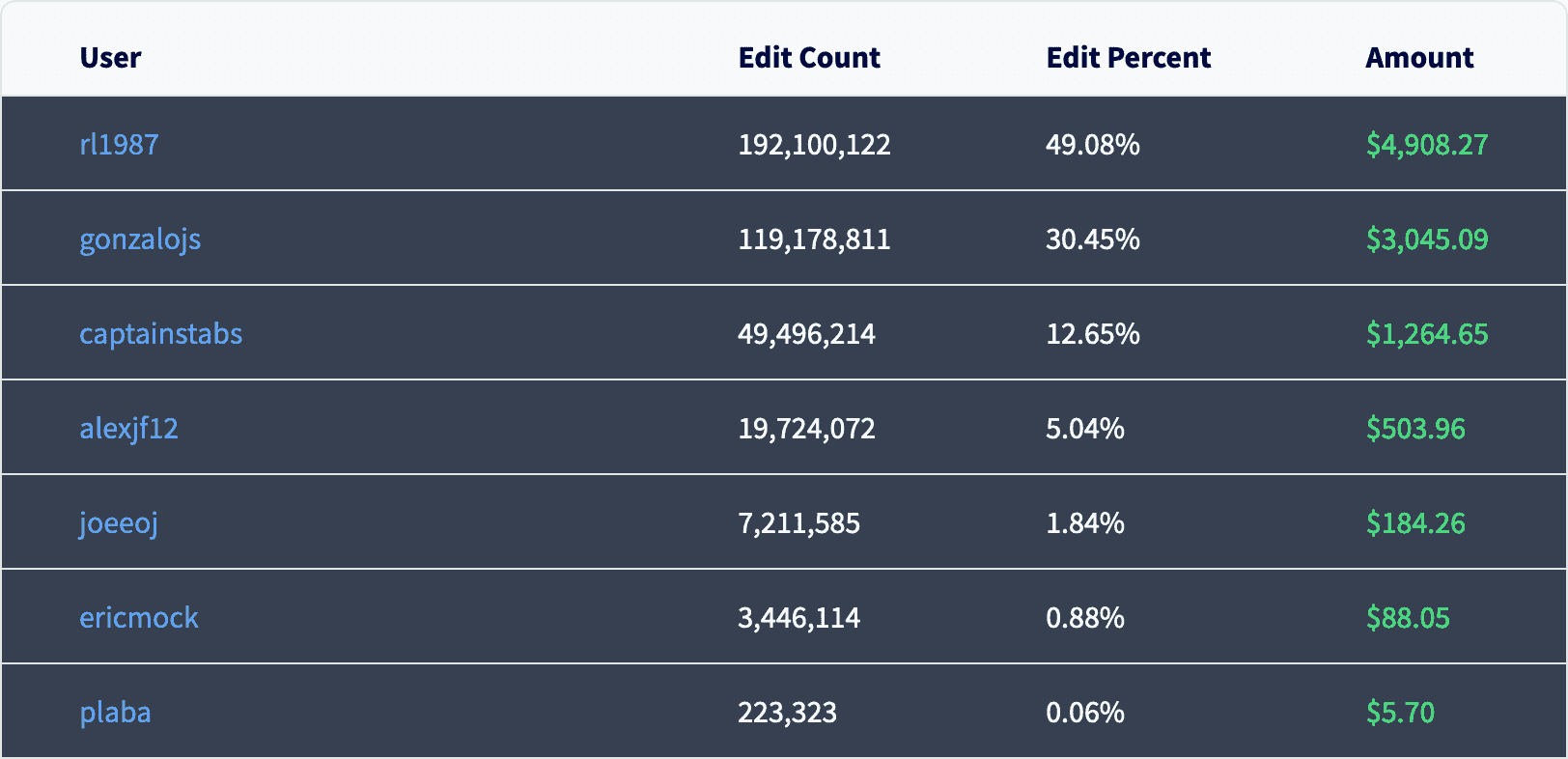
In total we had about 200 pull requests totaling 25.8 million objects from over 1262 museums globally. A surprising number of our museums are located in Norway, New Zealand, and Canada.

7 contestants competed, with @rl1987 taking home the top prize of almost $5,000.
Next time: divide and conquer
Museum records don't easily fit into a flat-table format. Plus, they come in lots of forms: paintings, boxing gloves, fossils, and even live plants and butterflies.
Our schema couldn't accommodate everything, and we even ended up paying out two contestants $500 each for contributions we couldn't accept.
There are technical reasons why it's easier to add rows than it is to add columns, or to modify the schema, while the bounty is ongoing. But what's the point of having a data bounty if we can't pull in all the data possible?
We went back to the drawing board to think a little on how we could make bounties better.
A new bounty system
In the end, we decided to keep bounties the same length (6 weeks), but divide them into one-week-long chunks, with fixed payouts each week.
This will allow us to keep the schema up-to-date with the latest data (we can change it weekly if needed) as well as keep the payouts consistent over time.
We'll be trying out this system with our latest bounty, which started last week.
What next?
Our latest bounty is set to run 6 weeks, until Friday Sep. 21, 2022, with a payout of $2k starting each week. If you want to participate, fork the database and make your first pull request.
We'll be waiting for you on Discord if you have any questions on how to get started. Our #data-bounties channel would love to meet you.