DoltHub and DoltLab now support SQL uploads

Today we're excited to announce that DoltHub and DoltLab now support .sql file uploads. Prior to this change, users could only upload a .csv, .psv, .xlsx, or .json file using DoltHub and DoltLab's web UI.
Although these are quite common file formats for uploading data on the web, these formats only allow for single table creation or single table modification on a database branch. This means that if a user wants to upload data for three different tables in her DoltHub or DoltLab database, she'd have to upload three separate files, table1.csv, table2.csv, and table3.csv.
However, with the .sql file format now supported, users are no longer limited by this one-file one-table restriction. Instead, they can make changes to all tables on a branch with just a single file!
Users also gain the ability to execute powerful SQL statements on the web against their DoltHub and DoltLab databases. SQL commands that were formerly reserved for the Dolt command line, like adding table triggers with CREATE TRIGGER or checking column constraints with CONSTRAINT CHECK, can now be performed on the web by including these statements in an uploaded .sql file.
Let's look at a couple examples to see this new feature in action.
Branch-wide Changes
When uploading a .sql file to a DoltHub or DoltLab database, each of the SQL statements in the file is executed against the selected database branch. Any changes made to the branch get committed and pushed to either a pull request branch, or to the main branch of the database.
Uploading a .sql file on DoltHub or DoltLab, then, is essentially analogous to piping a .sql file into a Dolt database on the command line with:
dolt sql < example.sqlTo see this in action, let's create a new database on DoltHub, called sql-example.
Under the "Get Started" section of our new database, let's click "File Upload" so we can add tables and data to our new database using a .sql file.
Since our new database does not yet have a branch, a main branch will be created and our changes will be committed and pushed to it.
Next, we'll select the file we want to upload.
Let's choose example.sql that contains the following:
CREATE TABLE t1 (
pk INT NOT NULL,
c1 VARCHAR(255),
c2 VARCHAR(255),
c3 VARCHAR(255),
PRIMARY KEY (pk)
);
CREATE TABLE t2 (
pk INT NOT NULL,
c1 VARCHAR(255),
c2 VARCHAR(255),
c3 VARCHAR(255),
PRIMARY KEY (pk)
);
CREATE TABLE t3 (
pk INT NOT NULL,
c1 VARCHAR(255),
c2 VARCHAR(255),
c3 VARCHAR(255),
PRIMARY KEY (pk)
);
INSERT INTO t1 (pk, c1, c2, c3) VALUES (1, 'foo', 'bar', 'baz');
INSERT INTO t2 (pk, c1, c2, c3) VALUES (1, 'aaa', 'bbb', 'ccc');
INSERT INTO t3 (pk, c1, c2, c3) VALUES (1, 'homer', 'jay', 'simpson');This file will create three tables in our database and insert a single row into each table.
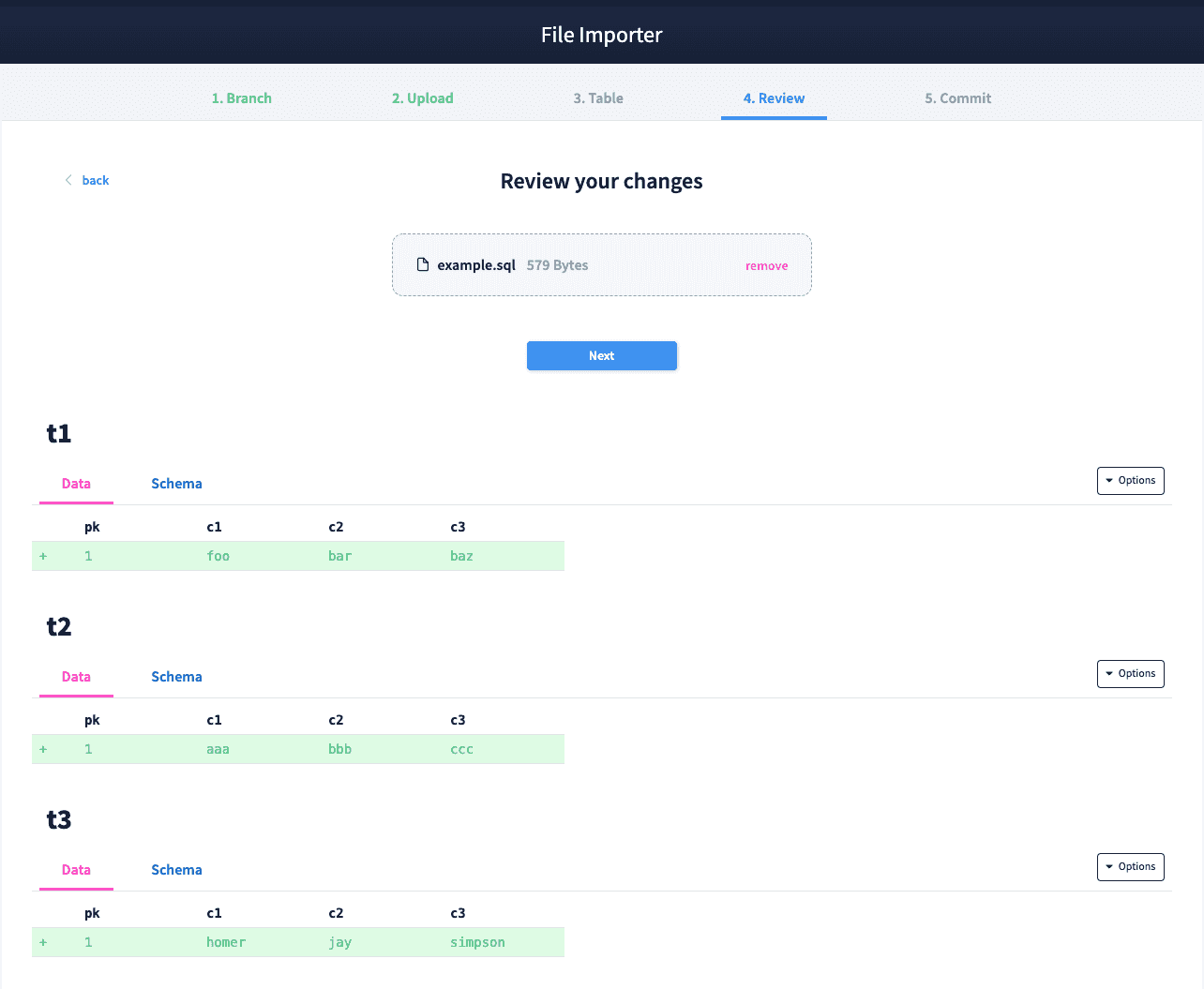
We can see the diff of our .sql upload in the Review step and our changes look good. Finally, we can complete our upload and commit these changes.
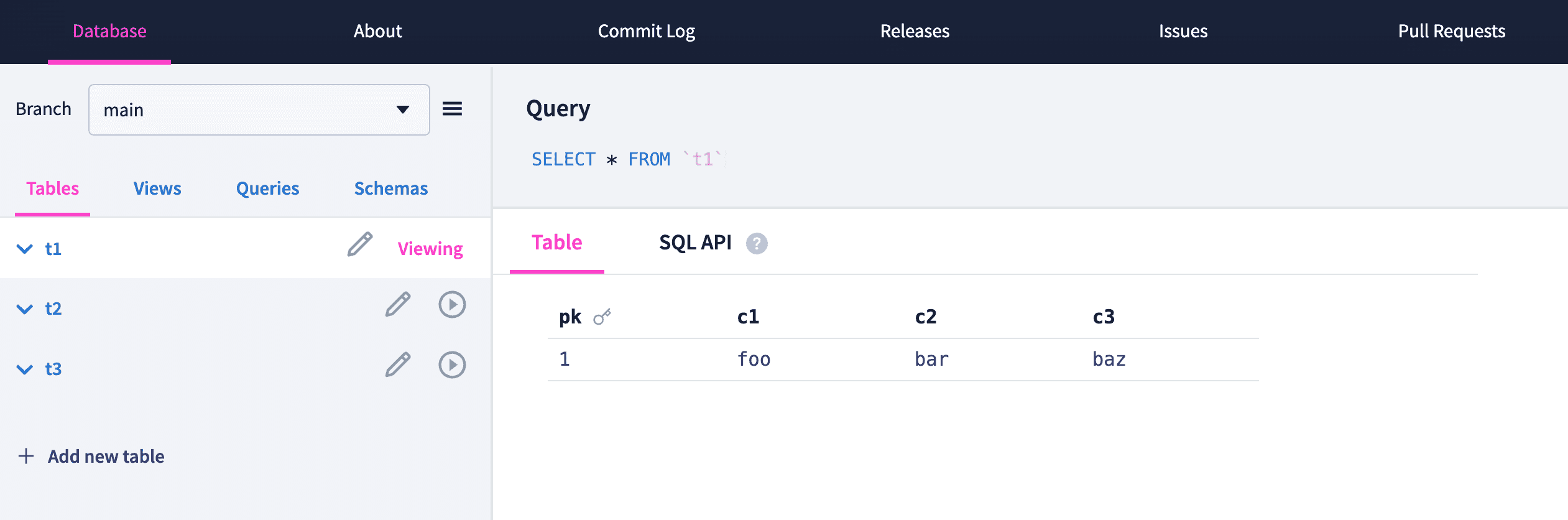
After a successful .sql upload, we see that our database is no longer empty, and we successfully made branch-wide changes to our database with a single .sql file instead of uploading three separate files using a different file format.
Let's trying uploading a different .sql file called update-example.sql that contains:
DROP TABLE t2;
INSERT INTO t1 (pk, c1, c2, c3) VALUES (2, 'hot', 'cross', 'buns');
UPDATE t3 SET c1 = 'marge', c2 = 'kay' WHERE pk = 1;This file should drop table t2, insert a new row into t1, and update a two cells in t3.
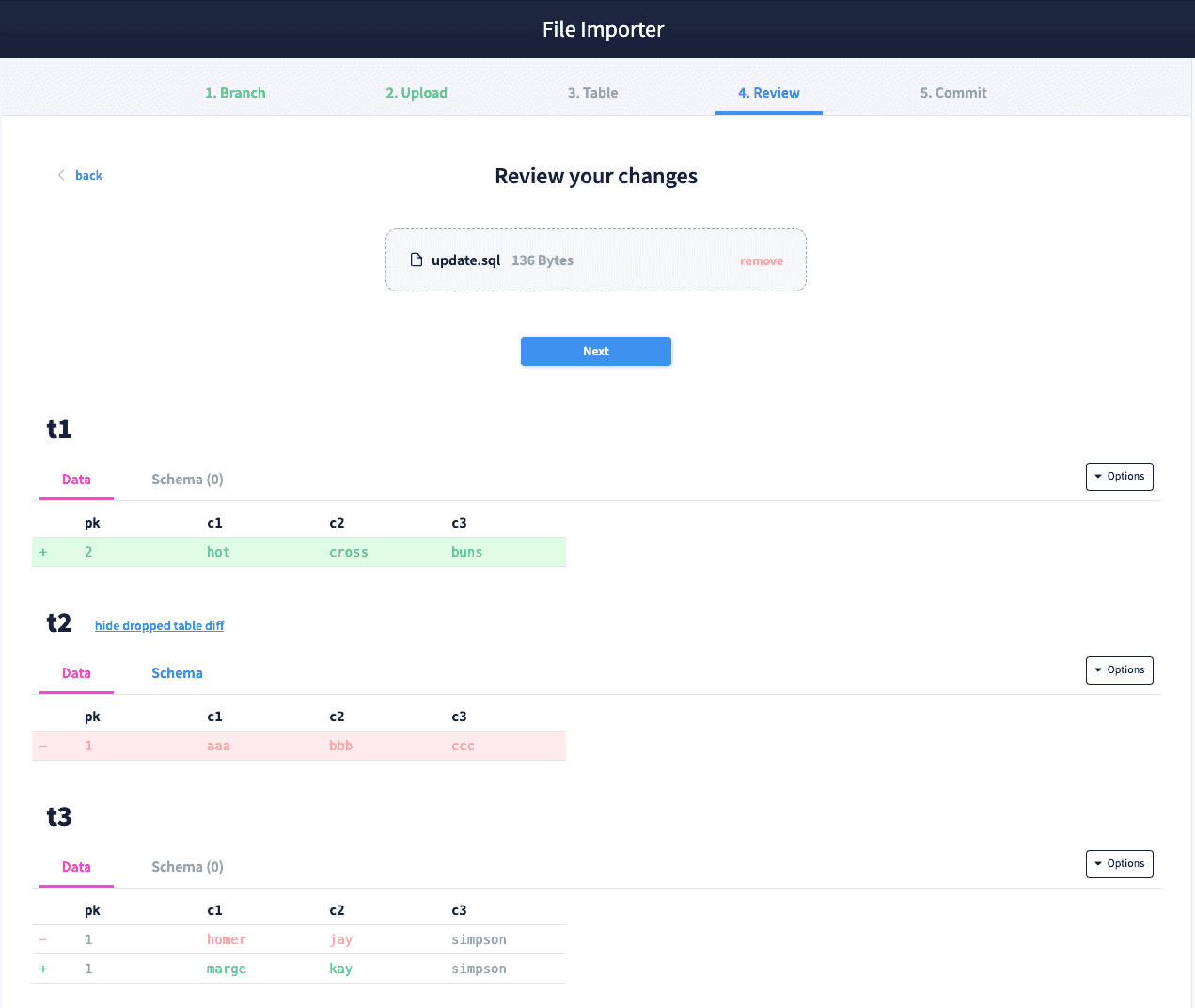
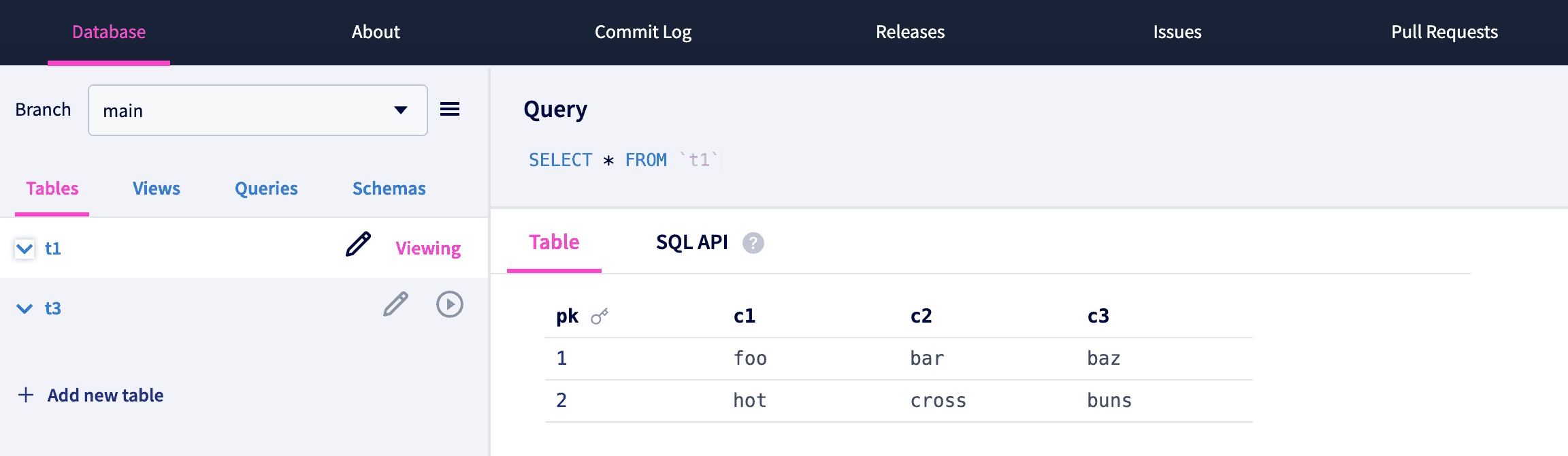
And just like before, the diff shows us that all three tables are changed correctly and a new pull request is created against main with these proposed changes.
After merging the pull request, we can see our main branch is up to date.
Now let's try adding a check constraint to table t3 and an insert trigger to table t1. We can upload a file called constraints_triggers.sql that contains the following SQL statements:
ALTER TABLE t3 ADD CONSTRAINT simpsons_only CHECK (c3 = 'simpson');
CREATE TRIGGER add_foo_c3 BEFORE INSERT ON t1 FOR EACH ROW SET NEW.c3 = CONCAT(NEW.c3, 'foo');After uploading this file and merging the changes into our main branch, we expect table t3 to only allow inserts of "simpson" into column c3. We also expect inserts of any value into c3 on table t1 to get "foo" appended to it.
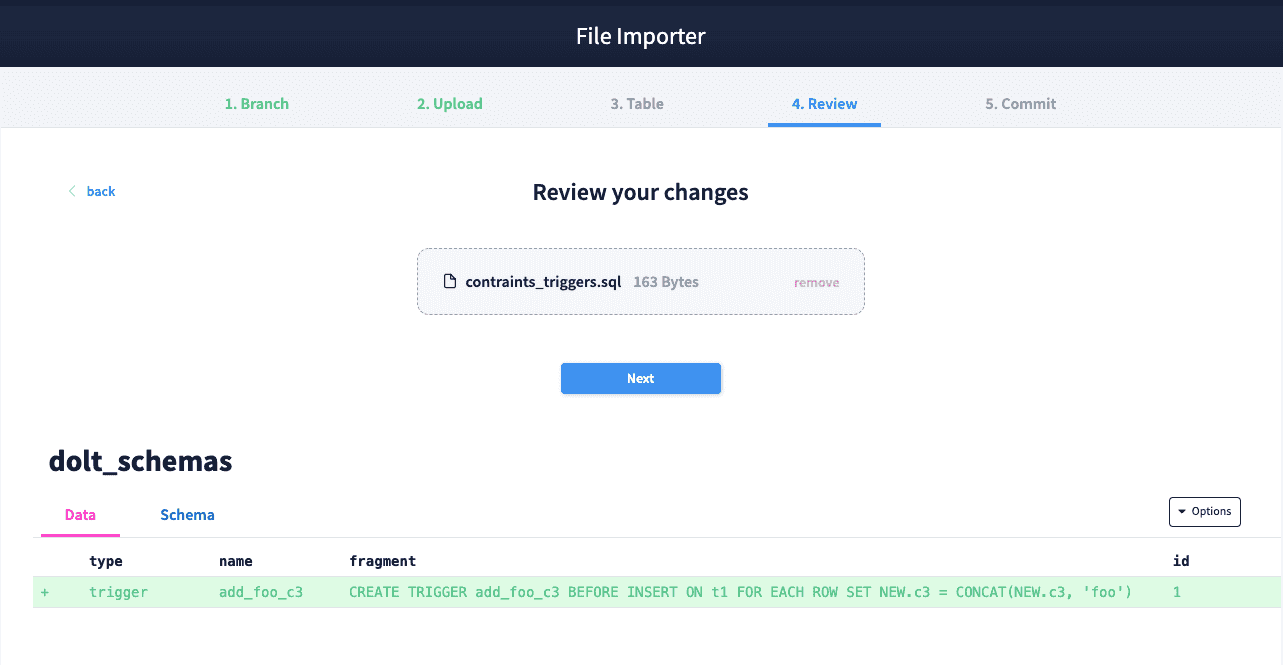
We can see the diff of our changes in the image below which creates a dolt_schemas system table and includes the trigger we created. The check constraint is added as well, but does not produce a diff.
With this change merged, let's try our new insert trigger on table t1. We can run INSERT INTO t1 (pk, c1, c2, c3) VALUES (3, 'alpha', 'beta', 'gamma');, using DoltHub or DoltLab's SQL console.
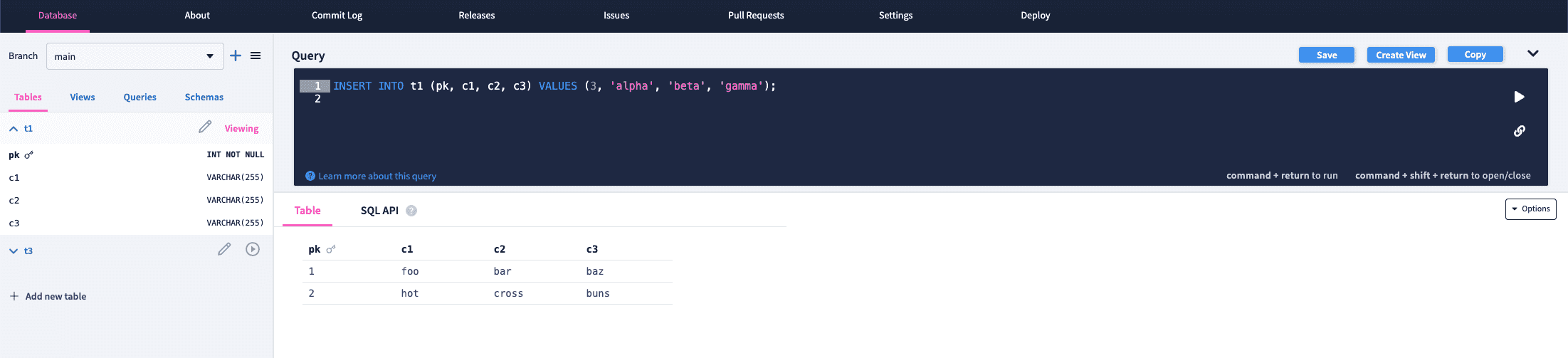
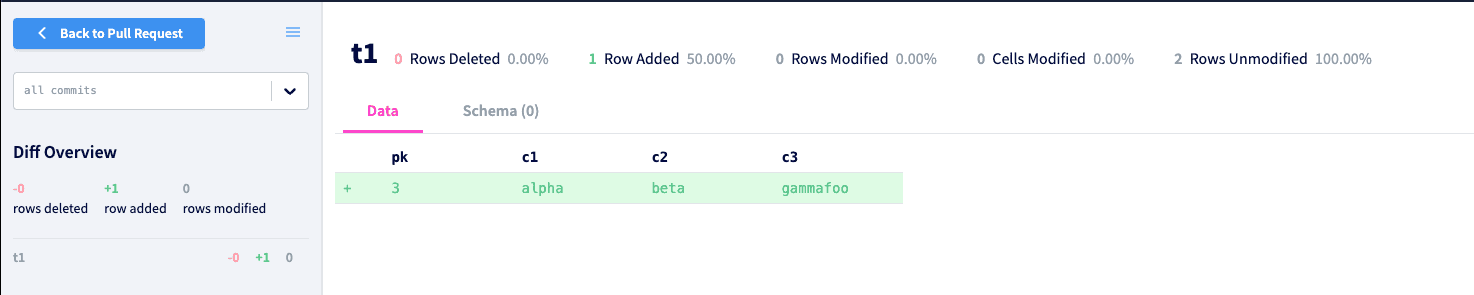
This statement will insert a new row and the add_foo_c3 trigger should append the word "foo" to the word "gamma". After running the query and inspecting the pull request diff, we can see that our trigger worked perfectly.
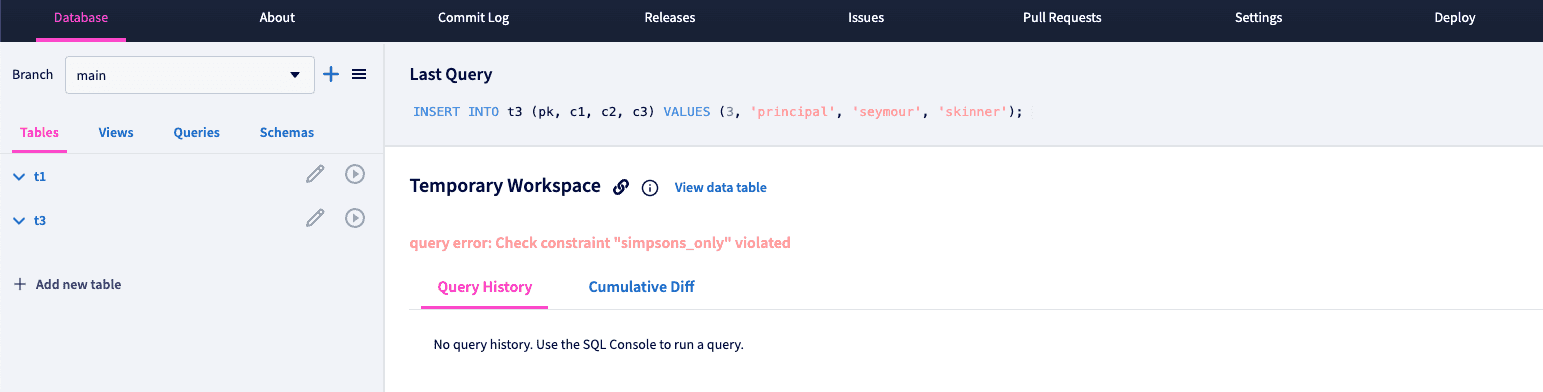
Finally, let's test the check constraint we added on t3. Using the SQL console once again, we are able to successfully insert a new row, adding 'lisa', 'may', 'simpson' to the table.
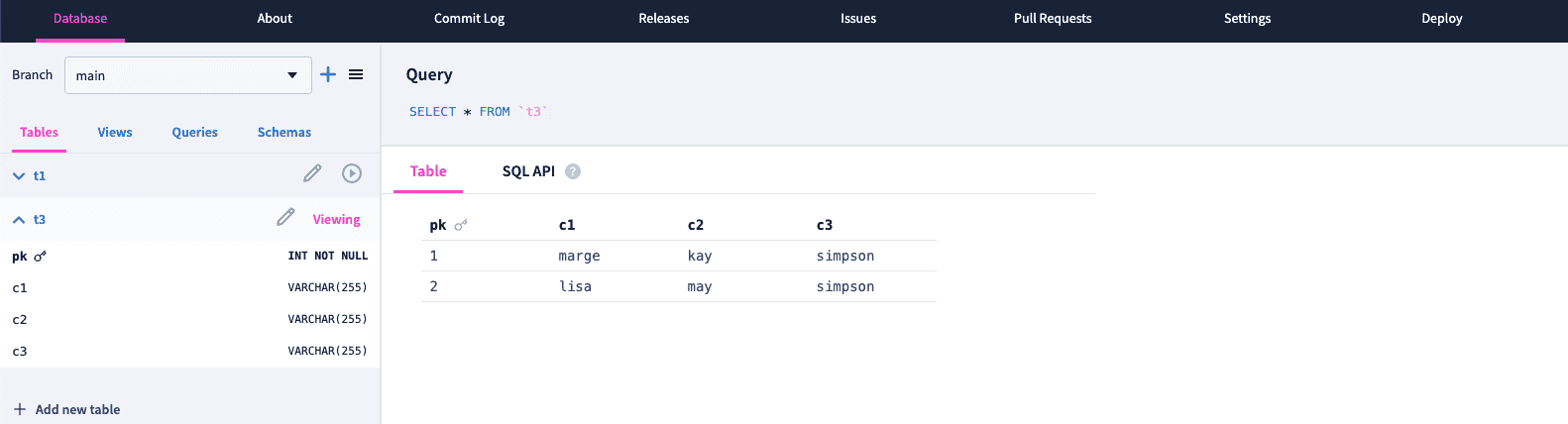
However, when we attempt to insert 'principal', 'seymour', 'skinner', ('skinner' in column c3) we get the constraint violation error, as we expect, demonstrating our check constraint is in place.
Limitations and Future Work
Currently, .sql uploads on DoltHub and DoltLab are limited to .sql files < 10MB, with accumulated writes limited to < 64MB. Although these allowed maximums are pretty small, they're temporary.
We are in the process of scaling our infrastructure to support arbitrarily large .sql file uploads on DoltHub and DoltLab, but for now, we need to prevent memory exhaustion in our API while we continue the scaling work behind the scenes.
We're also really excited about adding support for .sql file uploads because it's the first step in allowing users to easily version their production database snapshots on DoltHub and DoltLab.
For users who want to continue using their legacy databases but also want to harness the versioning power of Dolt, .sql file uploads are the first step in allowing them to do so.
These users can create SQL snapshots of their legacy databases, then upload those snapshots to a DoltHub or DoltLab database. Doing this provides them a simple way to track changes occurring in their legacy database and provides excellent diffs between snapshots.
We're also working to make this process fully automated so that versioned snapshots can simply be scheduled by users. If this interests you, stay tuned for "Dolt your snapshots" updates 🤠.
Got questions, comments, or want more information about our products?
Checkout DoltHub, DoltLab, Hosted Dolt (https://hosted.doltdb.com/), and Dolt.