
Today we’re going to discuss a series of schema bugs discovered in our version-controlled database, Dolt. It manifested in three related ways, from the display layer, into the storage layer, and finally the execution engine. We will unravel the puzzle, and discuss how the solutions contribute to a more usable and performant Dolt.
1st Act: Schema Vision#
Dolt follows Git standards for versioning data. Before a bounty contributor can pull request a feature branch, they must resolve merge conflicts against the main branch. But there are differences between resolving lines of code in a VCS and rows in a database. In addition to overlapping row-level changes, Dolt validates foreign key constraints and schema compatibility between two branches.
A few weeks ago, a bounty participant got tangled on a curious merge
conflict in the
hospitals
bounty. The prices table cited a merge conflict, but the
diff
indicated no conflicting rows, and dolt schema show <table>, a common way to visualize the
schema of a table, was identical between the two branches:
~/D/d/d/hospital-price-transparency-v3 > dolt schema show prices;
prices @ working
CREATE TABLE `prices` (
`cms_certification_num` char(6) NOT NULL,
`payer` varchar(256) NOT NULL,
`code` varchar(128) NOT NULL DEFAULT "NONE",
`internal_revenue_code` varchar(128) NOT NULL DEFAULT "NONE",
`units` varchar(128),
`description` varchar(2048),
`inpatient_outpatient` enum('inpatient','outpatient','both','unspecified') NOT NULL DEFAULT "UNSPECIFIED",
`price` decimal(10,2) NOT NULL,
`code_disambiguator` varchar(2048) NOT NULL DEFAULT "NONE",
PRIMARY KEY (`cms_certification_num`,`payer`, `code`, `internal_revenue_code`,`inpatient_outpatient`,`code_disambiguator`),
KEY `cms_certification_num` (`cms_certification_num`),
CONSTRAINT `g9j30676` FOREIGN KEY (`cms_certification_num`) REFERENCES `hospitals` (`cms_certification_num`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;This suggests we shipped a feature that enforces schema compatibility
but fails to display in SHOW CREATE <table> statements. Frustrating!
But fixable. Improving table schema display revealed the difference,
pointing to a change of primary key order.
- PRIMARY KEY (`cms_certification_num`,`payer`, `code`, `internal_revenue_code`,`inpatient_outpatient`,`code_disambiguator`),
+ PRIMARY KEY (`cms_certification_num`,`code`,`inpatient_outpatient`,`internal_revenue_code`,`code_disambiguator`,`payer`),Two primary keys with a different column orders produce two different
rows, and so these schemas are incompatible. To illustrate this, note
this example table a with two different primary keys: (x,y), and
(y,x):
tmp> create table a (x int, y int, z int, primary key (...));
tmp> insert into a values (1,2,3),(4,5,6);
Map<Union<>,Union<>> - map {
(x, 1, y, 2): (z, 3),
(x, 4, y, 5): (z, 6),
}
Map<Union<>,Union<>> - map {
(y, 2, x, 1): (z, 3),
(y, 5, x, 4): (z, 6),
}Rows from one are incompatible with the other, therefore Dolt raises a merge conflict.
So, how do we resolve this conflict? Alec (Spacelove) chose to change the main branch to accommodate the contributors schema, rewriting the primary key.
hospital_price_transparency_v3> alter table prices drop primary key;
hospital_price_transparency_v3> alter table prices add primary key (`cms_certification_num`,`code`,`inpatient_outpatient`,`internal_revenue_code`,`code_disambiguator`,`payer`)Now the two schemas are compatible, and SHOW CREATE is better equipped
to identify schema difference in the future. That wasn’t so bad! The
bounty continues!
2nd Act: Passing The Baton#
Shortly after updating main, another bounty participant found a bug in point mutations:
hospital_price_transparency_v3> delete from prices where cms_certification_num = '210027';
Query OK, 12585 rows affected
hospital_price_transparency_v3> select * from prices where cms_certification_num = '210027' limit 1;
unable to find field with index 0 in row of 0 columnsThis error is bad! Deleting rows using a filter created an inconsistent storage state. We have thousands of tests for selects, deletes, and indexes, so this was surprising for us. Something about our changes to the hospitals dataset must have triggered this.
We can use the explain command to reveal how our optimizer
rewrites the query to execute the lookup:
hospital_price_transparency_v3> explain select code from prices where cms_certification_num = '210027' limit 1;
+------------------------------------------------------------------------------------------------------------+
| plan |
+------------------------------------------------------------------------------------------------------------+
| Limit(1) |
| └─ Project(prices.code) |
| └─ Projected table access on [code] |
| └─ IndexedTableAccess(prices on [prices.cms_certification_num] with ranges: [{[210027, 210027]}]) |
+------------------------------------------------------------------------------------------------------------+A secondary index named cms_certification_num on the same column is
chosen as the most efficient way to read the table. The index can absorb the
filter
and reduce a table scan to a targeted point lookup.
In the previous section, we resolved a merge conflict by rewriting the
primary key. But this query is using a secondary index, so how are the
related? We use secondary index mappings to lookup rows matching
cms_certification_num = '210027', followed up a lookup into primary
key storage (a clustered
index) to get
the rest of row. Could the secondary->primary lookup be broken?
After attempting to reproduce the error on a fresh repo, we discovered the bug was indeed related to the first. Reordering a primary key should rebuild every index. And we were! Or at least we were trying to. But the old primary key ordering persisted. The secondary index pointed to non-existent rows after the rewrite.
To give another toy example, consider the same table a from before,
but now with a secondary index:
tmp> create table a(x int, y int, z int, primary key (x,y));
tmp> insert into a values (1,2,3), (4,5,6);
tmp> alter table a add index z_idx (z);At the moment, our index z_idx looks like this:
Map<Union<>,Union<>> - map {
(z, 3, x, 1, y, 2): (),
(z, 6, x, 4, y, 5): (),
}The secondary index begins with the prefix, z, and is
followed by column closure required for a primary key lookup,
in this case x,y.
Now we follow in the steps of Spacelove, rewriting our primary index:
tmp> alter table a drop primary key;
tmp> alter table a add primary key (y,x);This is what z_idx should look like afterwards:
Map<Union<>,Union<>> - map {
(z, 3, y, 2, x, 1): (),
(z, 6, y, 5, x, 4): (),
}But it didn’t change! We were still trying to lookup rows on
(x,y).
Back to Dolt, indexCollectionImpl maintains ordered pks that
needs to be updated. A list of column identifiers (tags)
that correspond to the primary key order replaces the previous order,
fixing our index
incompatibility:
type indexCollectionImpl struct {
colColl *ColCollection
indexes map[string]*indexImpl
colTagToIndex map[uint64][]*indexImpl
pks []uint64
}
func (ixc *indexCollectionImpl) SetPks(tags []uint64) error {
if len(tags) != len(ixc.pks) {
return ErrInvalidPkOrdinals
}
ixc.pks = tags
return nil
}3rd Act: A Little Faster Now#
The second bug was more serious than the first, but it looked like we were now in the clear. We asked the bounty participants to recreate their indexes as a final step:
hospital_price_transparency_v3> alter table prices drop index cms_certification_num;
hospital_price_transparency_v3> alter table prices add index cms_certification_num (cms_certification_num);All seemed to be going well, until reports of out of memory errors (OOM) started trickling in. The alter statement was now correct, but fell over before completing.
A memory profile gave us some insight into the new problem:
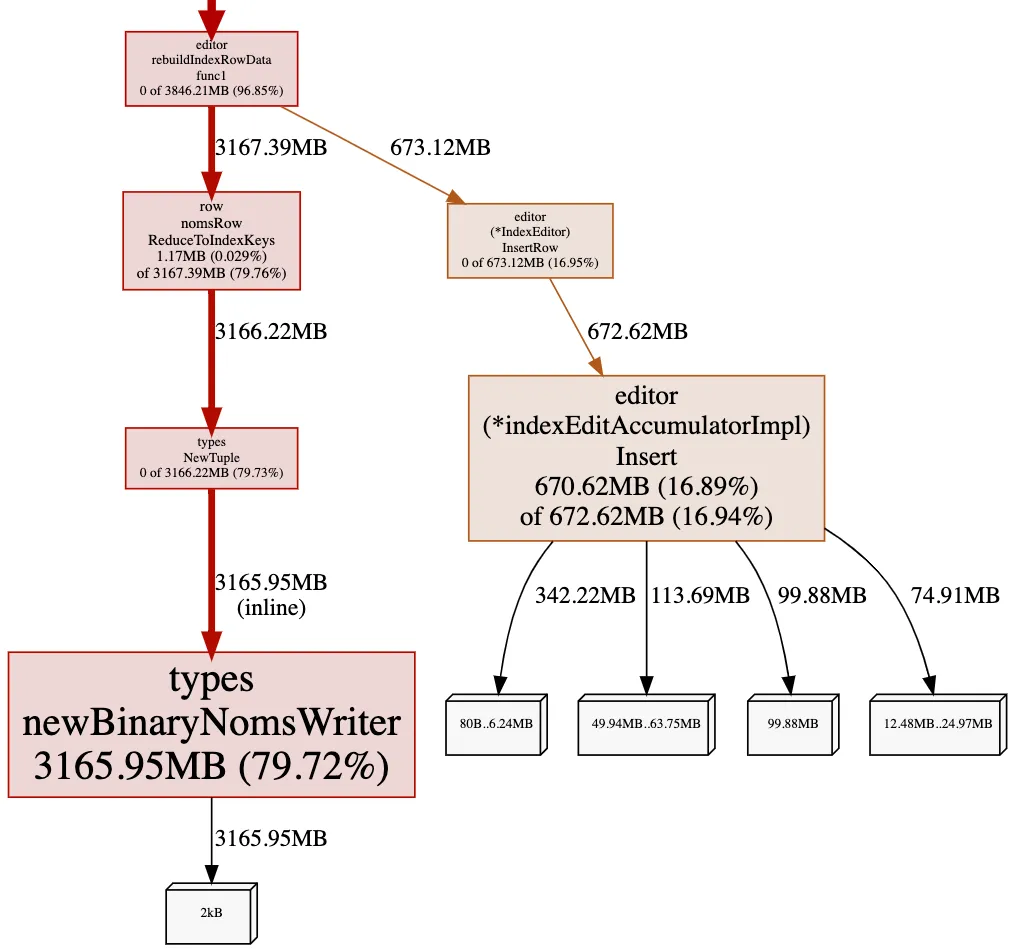
The heap trace shows we construct a new
nomsBinaryTypeWriter, a builder class, for each row. Building a tuple
requires converting data from a generic Go format, like
[]interface{1,"one",1.0}, into a Dolt format more suitable for
versioning and serializing on disk. This step consumes 80% of allocated
heap space and is a prime candidate for easing memory pressure.
Fortunately, Brian already solved
this problem last year with a TupleFactory! Formatting Go values is
necessary, but we do not need to create a new builder for every row.
The factory encourages memory reuse by preallocating a buffer for
consecutive tuple formats, shifting resource allocation back to more
productive paths:
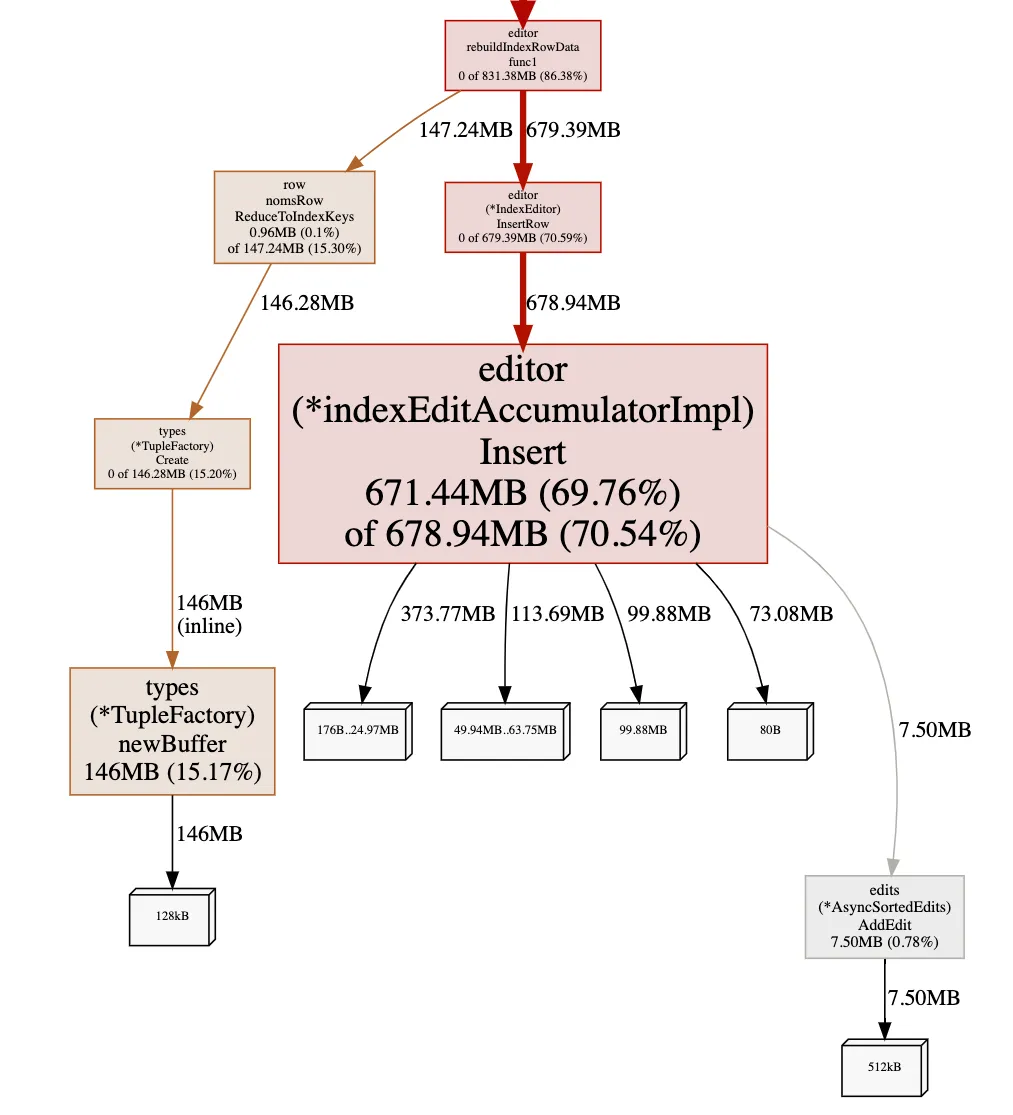
Memory is now spent writing rows rather than creating redundant builder classes!
TupleFactory on its own should fix our OOM. But before I pushed the
fix, I checked the CPU profile:
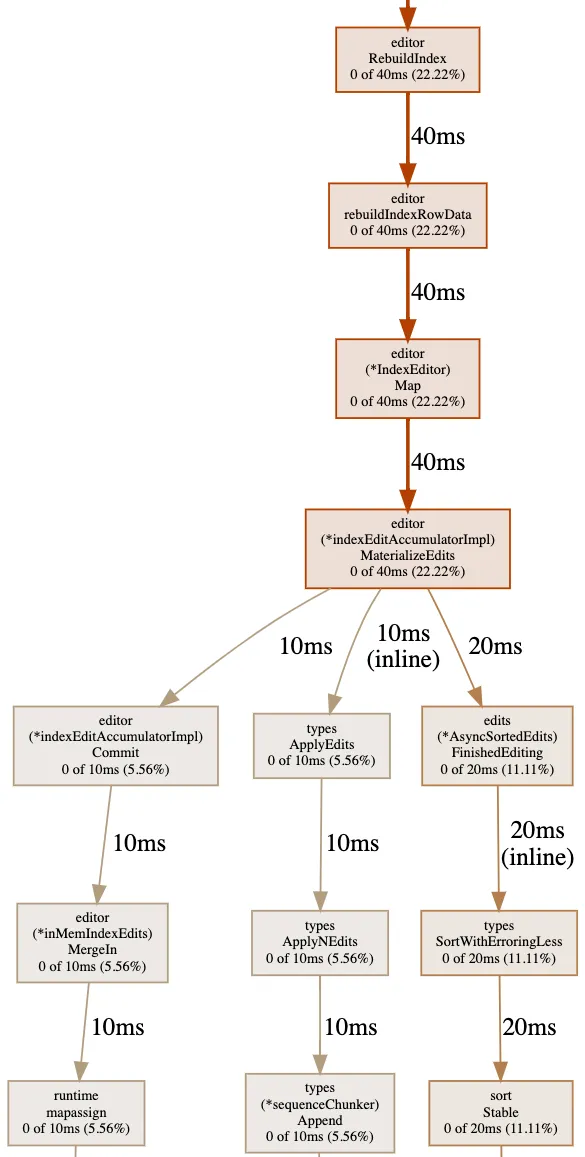
About half of the CPU cycles (time now, not memory) of RebuildIndex is
spent sorting data inside an editor class intended for in-memory
buffering. Fortunately, Brain also fixed this problem (at the same time
as TupleFactory) to improve batch write performance. A naive edit
accumulator materializes a versioned Merkle tree, the ultimate output
format, as a sorting intermediate. This is sort of like how there is a
“Dolt Tuple” storage layer equivalent to a list of builtin values. The
Merkle-tree here is the Dolt equivalent of a table array. But we don’t
really care if there is a Dolt specific format intermediate format for
index rewriting, regular Go lists and arrays work fine! So for batch
index rewrites, we will spill a more lightweight intermediate to disk to
get the job done quicker:

This last graph might not look like much, and that’s exactly the point! The supportive steps do not consume enough runtime to register in the profile. All killer no filler.
All in all, we managed to shave 90% off the runtime of the alter statement (80ms -> 10ms in this test), not to mention avoiding the OOM error originally plaguing bounty contributors!
Summary#
The scale and coordination required to administer data bounties has been a forge for stress testing Dolt (and Spacelove). Testing versioning is hard! Especially in a SQL context with different considerations than a traditional source code VCS’s. Today we talked about how a schema merge conflict snowballed first from a transparency problem into data storage layer bug, and finally into a DDL performance bottleneck. From UX to storage to perf in one bug! If data versioning and database performance excites you, stay tuned for more!
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!