US Businesses Bounty Retrospective

This guest blog post is by Spacelove, a top performer of several of our former bounties and winner of many thousands of dollars in prize money. He agreed to be the coordinator and judge for the US Businesses data bounty.
Our $10,000 bounty of US businesses resulted in (probably) the largest open dataset of US businesses ever, with a final count of over 20 million US businesses. Check it out for yourself.
us-businesses $ dolt sql -q "SELECT COUNT(*) FROM businesses"
+----------+
| COUNT(*) |
+----------+
| 20799488 |
+----------+For those of you that are new, Dolt is a database that supports Git-style versioning. DoltHub is a place on the internet to share and collaborate on Dolt databases. Data Bounties are contests where people are paid to build Dolt databases.
How did we do?
We got lucky with how the data was structured: state governments have most of the business information on their Secretary of State websites. With just under 10 participants, the 50 state websites led to everyone getting a nice chunk of the pie without leaving too much data leftover. We collected data from about half of the US states and most of the US population. If it wasn't behind a paywall or a CAPTCHA, our participants got it.
But the way businesses get registered in the US is confusing, and our database schema didn't make it easier on the participants to import the data. For example, is state_registered any state that a business is registered in, or the unique state that it's incorporated in? Is physical_address the same as a business's mailing address? What the heck is a registered agent?
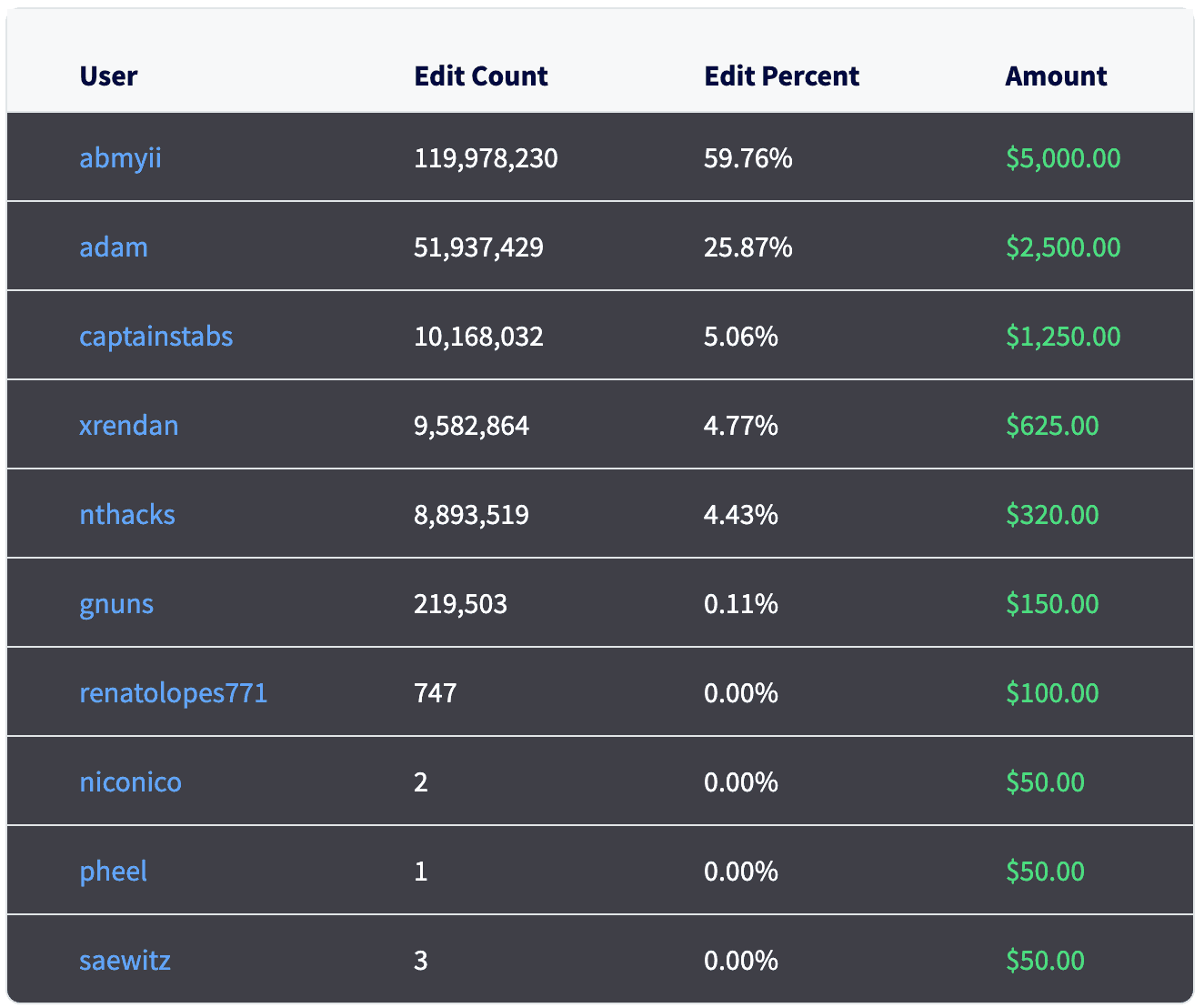
We needed more (and more descriptive) columns for our participants to make the schema self-documenting (and lower the cognitive overhead). But once our participants caught on they really set sail -- they collected 20 million rows of data, with our top-scorer contributing 120 million cells in total.
DoltHub usually awards prizes proportional to the number of edits a participant makes. This time we decided to fix the award for first place, second place, and so on, to keep a single participant from hoovering up the entire dataset. Plus, the minimum prizes for the lower places led to participants continuing to make edits up until the very last day of the bounty. Our top scorer, @abmyii, went home with $5,000, but a last minute dash from @gnuns allowed him or her to take home $150 in easy money.
What could you use this database for?
The dolthub/us-businesses database has one advantage over its competitors. It's free. As such, you can use it to prototype an application using this data and then move to one of the paid databases if your application is successful.
Some example paid sources are:
- https://www.businesslistdatabase.com/
- https://www.uscompanieslist.com/
- https://www.dataaxleusa.com/lists/business-lists/
Conclusion
These bounties are a fun, easy way to learn to scrape the web, to get comfortable with git, and to manage a database with SQL. Anyone can learn something from joining one of our bounties, from the talented high schooler, to the stay-at-home parent, to the software engineer. And everyone who joins earns a little spare cash. Join us for the next one.
Inspired? We started another $10,000 bounty a couple days ago. This time we're building a worldwide basketball database called SHAQ. Stop by our Discord if you have any questions.