
About Dolt#
Web services make heavy use of versioning and open source sharing as a daily part of development. Production deployment is increasingly automated by AWS and other cloud services. Sandboxing, testing, and offline debuggability increase the pace and quality of software. Yet the most commonly used databases — MySQL, Postgres, RDS — are stuck in the past. DoltHub is building a new relational database to meet the expectations we demand of modern software. Versioning, sharing, software as a service (SaaS), and offline debugging are features we love for code, computing, and now data with Dolt.
Wisdom of the Crowd#
Doltpy is a Python wrapper that makes it easier to use Dolt
in the language of data science. One of the ways we use Doltpy
is to build integrations with data science workflows and tooling.
We studied a variety of open source Python projects in the process
of building data integrations this year. In this blog, we
will talk about gems we discovered in other codebases, gems too
good not to use ourselves.
If you are a data scientist or engineer who works with Python, you
might be interested in how we upgraded our Python library
doltpy with
designs from Metaflow,
Flyte,
Kedro, and Great
Expectations.
We also discuss how large codebases in Python tend to adopt qualities of compiled languages. Formatting, linting, unit testing, and tooling automation tend to converge on the same principles for big projects in every language. We will use terminology and theory from Golang for this purpose, given our background building Dolt.
Evolution and Convergence#
If there is one thing we appreciate at DoltHub, it’s shipping product. And when you need to quickly write and ship code to thousands of developers with a click of a mouse, there’s nothing else quite like Python. For all its faults, Python greased the wheels of the data science Cambrian explosion. The pace, hierarchy, and quality of devtool evolution is wonderful to study and dizzying in rate of churn.
Much of our codebase at DoltHub is written in Go, an anti-Python designed to limit variability at the language layer. Go comes with a default formatter, a default package manager, and an opinionatedly minimalist testing package. Go prevents you from building code with unused variables or unused imports. Go users claim the language is for “serious projects.”
In the process of analyzing and contributing to several “serious” Python projects, we came to the conclusion that all projects trend towards the same set of tools static compilers provide. Extending the evolution metaphor, libraries that flourish exhibit a convergent evolution. All developers introduce static checks to reduce the frequency of bugs, increase code coverage, and automate error prone tasks as projects succeed and grow.
Enforcing Code Strictness in Python#
When I joined DoltHub our code quality included a handful of tests, and that was it. Now we enforce several degrees of code quality, track test coverage, and automate code quality enforcement.
We separate code strictness into test, fmt, and lint stages. test is
responsible for running unit tests (pytest). fmt normalizes the code
structure, like replacing single quotations with double
quotations, and putting double spaces between top level functions
(black). Finally lint reorders imports (isort), indicates unused
variables (flake8), and enforces type constrains on classes, methods,
and functions (mypy). Separating code quality by scope of concern
allows developers and CI processes to run steps individually.
Static languages like Golang perform these checks at the same level of granularity: files are formatted when saved, code is linted while compiled, and libraries are unit tested once built. Building serious projects without static checks ignores preventable bugs. It is therefore unsurprising that languages like Python and Javascript are catching up for maintaining “serious” projects.
Command Organziation#
Open source projects want to make it easy for new and existing contributors to add formatted, linted, and tested code. One of the ways we help automate this is by executing static checks locally.
When we first shipped doltpy, we used a set of bash scripts to make it easy to run tests:
#!/bin/bash
set -xeou pipefail
DIR=$(cd $(dirname ${BASH_SOURCE[0]}) && pwd)
BASE=$DIR/..
cd $BASE
black . --check --exclude tests/ -t py37
mypy doltpy/
pytest testsLater we moved to using a Makefile:
line_length = 95
package = doltpy
.PHONY: fmt lint test
fmt:
black . --check -t py37 --line-length=${line_length} || ( black . -t py37 --line-length=${line_length} && false )
isort .
lint:
mypy ${package}
flake8 ${package} \
--max-line-length=${line_length} \
--ignore=F401,E501
test:
pytest tests --cov=${package} --cov-report=term --cov-report xmlWe only run a small number of commands, but
both solutions beat memorizing checks. We
prefer the Makefile version, which summarizes commands
in one location and can be copied and reused
with different package variables. The Flyte project deserves credit
for inspiring our Makefile organization. If we choose to nest packages as a
monorepo (like flyte does) or make our build more complicated,
Makefiles grow under the stress.
Automating Commands#
Running code quality commands after every commit is a job best left for machine. Doltpy lacked continuous integration (CI) when I joined, and now we use GitHub Actions to automate daily, Pull Request (PR), and manually triggered workflows.
name: Doltpy Tests
on:
push:
branches:
- main
pull_request:
schedule:
- cron: '0 20 * * *'
jobs:
build:
strategy:
matrix:
python-version: ['3.6', '3.9']
os: [ubuntu-latest]
runs-on: ${{ matrix.os }}
steps:
- uses: actions/checkout@v2
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v1
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
run: ...
- name: Format
run: |
poetry run make fmt
- name: Lint
run: |
poetry run make lint
- name: Execute pytest
run: |
poetry run make test
- uses: codecov/codecov-action@v1
if: ${{ matrix.python-version }} == '3.9'
with:
token: ${{ secrets.CODECOV_TOKEN }}This abbreviated
workflow
runs our fmt, lint, and test steps after
environment and dependency setup. We test using both
py36 and py39 for backwards compatibility. If tests pass,
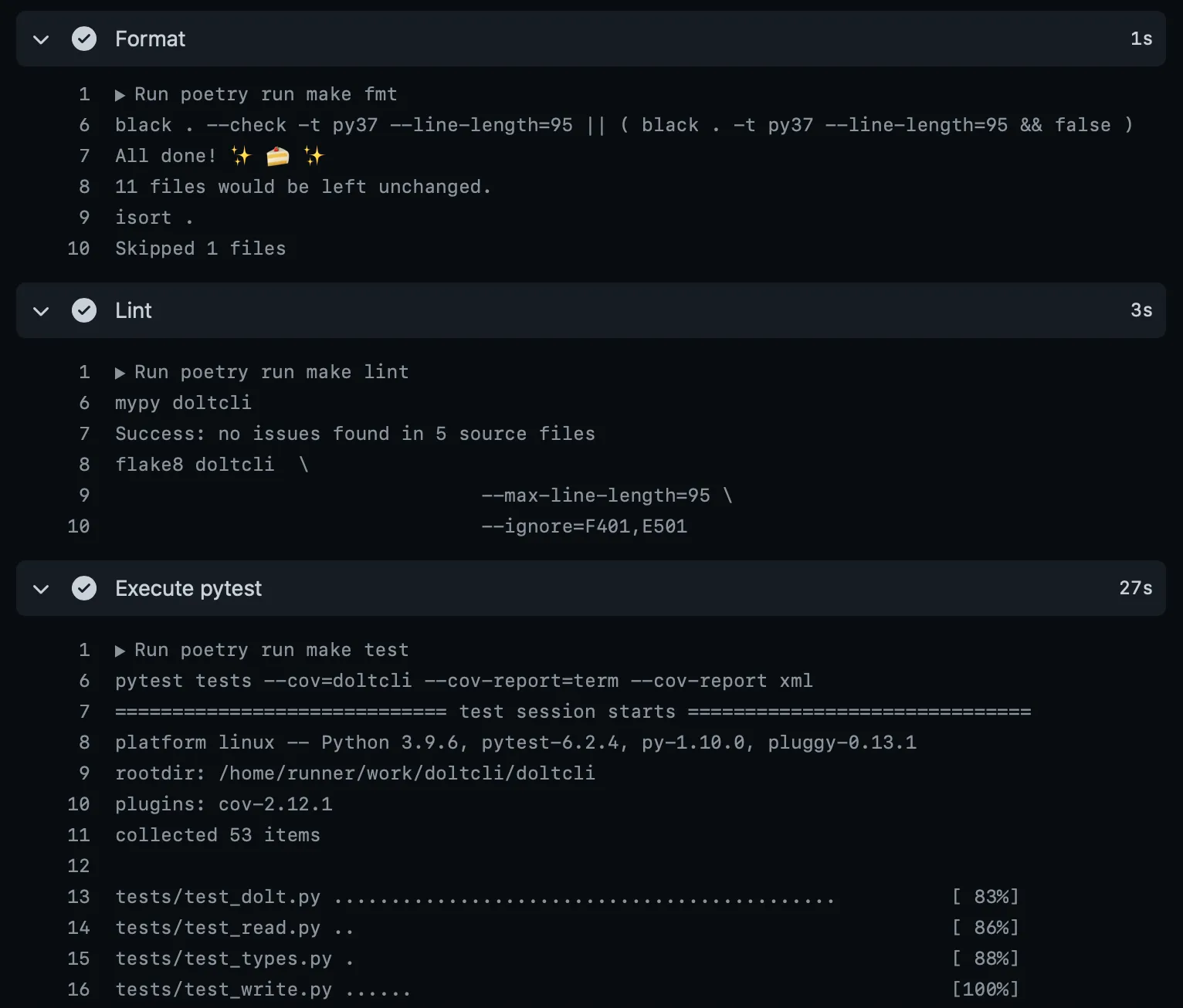
we push coverage statistics to codecov.io. The image in the “Enforcing Code Strictness in Python”
section shows logs for a sample workflow run. Similar to our Makefile in the
previous section, this workflow can be copied to
quickstart new project automation.
GitHub Actions’s workflow language and runner stability is OK, not great. Lacking basic code reusability and other features is inconvenient. Kedro’s CircleCI configuration is a comparison setup that I prefer syntactically. But vertically integrating source control and build automation in a single UI is powerful.
And it is free. As Uncle Ben used to say, with great freedom comes great network effects. Most projects have similar automation goals. If you are already familiar with commonly used plugins, variable substitution patterns, and other oddities of GitHub Actions, you already know 80% of the build and test processes of many open source projects. Likewise, projects that use GitHub Actions immediately have a wide pool of potential contributors who know how to clear PR quality hurdles.
Matrix Tests are Integration Tests#
We finish with one of the common difficulties in emerging open source projects. Pytest is simple for writing a handful of unit tests, but becomes tedious for hundreds or thousands of functions. Developers invariably write code to generate tests instead.
When done well, the result looks like Golang’s table driven tests. The linked examples might look something like this using pytest parametrize.
flagtests = [
("%a", "[%a]"),
("%-a", "[%-a]"),
("%+a", "[%+a]"),
("%#a", "[%#a]"),
]
@pytest.mark.parametrize("flag,want", flagtests)
def test_flagparser(flag, want):
for i, test in flagtests:
got = flagparser(flag)
assert got == wantLoop iterations are individually identifiable tests,
and individual rows can be tested using argument filters. With these
additions, the experience
for new contributors is easy. To add a new test example, we simply add a
row to flagtests. As long as we can filter the new test using its flag
field, we can switch between code improvements and tests in a tight loop.
The more common pattern we have seen in big projects is matrix tests. In a testing matrix, code is subdivided into a handful of argument buckets (ex: [sequential, parallel, graph], [low memory, med memory, high memory], […]) and executed once for each combinatorial combination of arguments. Test matrices avoid code duplication and achieve high testing coverage, the two immediate drawbacks of pytest functions.
The downside is that matrix tests are integration tests. You cannot tweak and test only one portion of the system. The entry barrier for newcomers is high. A lack of unit tests alienates open source contributors. At the same time, it is irresponsible to commit new code without testing important interactions within and between codebases. A balanced approach is best. Small PRs run integration tests but have equally small test additions. Disparate systems should have separate processes for integration testing and bumping version dependencies.
All of this sounds obvious, but I do not think the Python community gracefully tests large projects. And even static languages that force good patterns and run hundreds of tests a second struggle with this balance, as we do with Golang and Dolt.
Conclusion#
In this blog, we summarized learnings from building data integrations with open
source Python projects. Although dynamic languages
lack the mandatory quality checks and default toolchains of static languages,
we have observed a tendency for Python projects to
handroll similar quality checks. In turn, we applied these
lessons to our open source Python package
doltpy. Readers are encouraged to
critique, share, and reuse the automation code discussed here.
If you are interested in learning more about Dolt, Doltpy, or relational databases reach out to us on Discord!