Improving Diffs on DoltHub

DoltHub is a place on the internet to share, discover, and collaborate on Dolt databases. Diffing between different versions of data is a big part of what makes Dolt unique as a database, and we revamped our diff page on DoltHub to better show off this feature.
This blog will go through our motivations for adding new features to the diff page on DoltHub, another option we explored for representing diffs, and the final result. But first, welcome our new diff page:
Data bounties
We started running data bounties a few months ago as a way to build interesting, public datasets. We pay contributors a percentage per cell edit of a set reward amount for their work during a specified time period. Currently only our team can run a bounty, but we're hoping in the future this can be a two-sided marketplace where any third party can run their own bounty.
As we've been running more and more bounties, it became apparent that the data submission review process was going to be a roadblock. How do we ensure the datasets we're building have clean, reliable data?
We decided to start with making diffs easier to review. Our diff page wasn't very interactive and getting to the meat of the data was time consuming and sometimes impossible to do on the web. The bounty administrators on our team came up with some pain points that we used to create a list of solutions and desired features.
Desired diff features
Once we identified some significant pain points, we came up with a list of features and improvements to make reviewing diffs easier and more interactive.
-
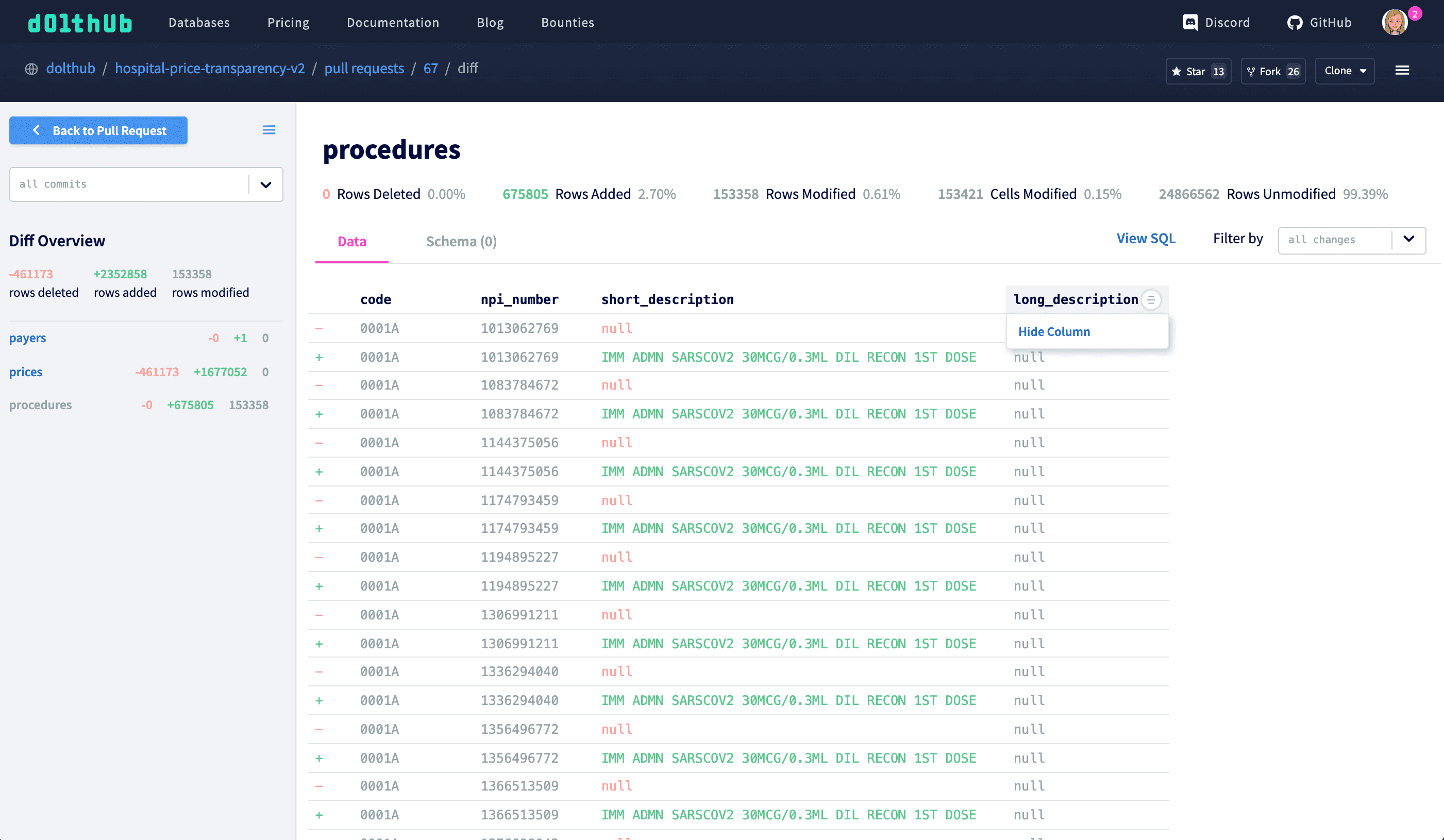
Hiding columns - Diffs of wide tables are especially difficult to review. Our data tables already have the hide column feature, and it made sense to make this work for diff tables as well. Hiding less relevant columns gets you to the important data faster.
-
Filter by diff type - Filtering diffs by only added, removed, or modified rows is another way to get to the meat of the data more easily. For bounties in particular, it's important to double check removed and modified rows to ensure contributors aren't removing or changing other people's work erroneously.
-
Make diff summaries work for all diffs - If you've been using DoltHub for a while, it's likely you've encountered a time out error on the diff page. Fetching a diff summary (the total amount of rows/cells added, removed, and modified) requires calculating the totals on the fly, which can be very expensive for large tables and does not complete. This information is vital to quickly understanding the overview of changes and knowing where to start during the review process.
-
Involve our designer to rework the user experience - Our old diff page was clunky. It was originally inspired by GitHub's diff page (see example), but we've learned that data shouldn't be reviewed in the same way we review code. For starters, you'll (almost) never get a pull request on GitHub with millions of line changes. Wide code files can easily incorporate line breaks instead of relying on horizontal scroll. Our databases have 1-10 tables on average, whereas a repository on GitHub can include thousands of files. While we heavily lean on GitHub for inspiration for some of our other pages, we were optimizing for the wrong things on our diff page. The diff tables were jammed into one pane and the actual real estate to view the row diffs was too minimal. We had a few ideas we could bring to our designer Jan to move a few things around to enhance the data review experience for our users.
-
Run SQL queries against diff tables - Our most recent version of DoltHub was designed with a SQL-first mindset, and what better way to lean into the SQL metaphor than using SQL to query our diff tables. Similar to our data tables, our hide column and diff filter features could generate SQL queries to get the desired rows.
The dolt_diff_$TABLENAME system table
The first idea we had to support all the above features was to use one of Dolt's system
tables,
the dolt_diff_$TABLENAME
table.
This table can be queried to see how rows of a data table have changed over time. Each row
in the result set represents a row that has changed between two commits. This would allow
us to use the SQL Console to control what information we want from our diffs, similar to
our data tables.
For example, the query to generate the procedures table
diff
above would use the dolt_diff_procedures table and look something like:
SELECT diff_type,
from_code,
to_code,
from_npi_number,
to_npi_number,
from_short_description,
to_short_description,
from_long_description,
to_long_description,
from_commit,
from_commit_date,
to_commit,
to_commit_date
FROM dolt_diff_procedures
WHERE from_commit = "ttajqfc87hu9549bd9v9dk7fq67rppp2"
AND to_commit = "qp4rqscufjlv2019mn6tnpb9g40fkt81"Hiding a column could be easily implemented by removing the chosen column from the select statement columns. Filtering by diff type would just be an extra condition added to the where clause.
After some exploration, it became clear there would need to be some major improvements to
the dolt_diff_$TABLENAME table to use it in place of our current diff table. One of the
two main roadblocks discussed were that tables with column type changes translated to
dolt_diff_$TABLENAME tables with multiple versions of each changed column, represented
by tags. Because the procedures table above includes these kinds of column changes, the
dolt_diff_procedures
query
would actually look like this:
SELECT diff_type,
from_code_534,
to_code_534,
from_code_13082,
to_code_13082,
from_code_15851,
to_code_15851,
from_npi_number_1717,
to_npi_number_1717,
from_npi_number_10462,
to_npi_number_10462,
from_npi_number_14113,
to_npi_number_14113,
from_short_description_6601,
to_short_description_6601,
from_short_description_11249,
to_short_description_11249,
from_short_description_11410,
to_short_description_11410,
from_long_description_1877,
to_long_description_1877,
from_long_description_7429,
to_long_description_7429,
from_long_description_8004,
to_long_description_8004,
from_commit,
from_commit_date,
to_commit,
to_commit_date
FROM dolt_diff_procedures
WHERE from_commit="ttajqfc87hu9549bd9v9dk7fq67rppp2"
AND to_commit="qp4rqscufjlv2019mn6tnpb9g40fkt81"Not cute or easy to work with. We intend to fix this eventually, and you can follow along with our open issue with a proposed solution here.
Our second roadblock is that the dolt_diff_$TABLENAME table does not include 3 dot
diffs, which are necessary
for diffs in pull requests.
We ultimately decided to stick with our current implementation of the diff table, and to
add hiding columns and filtering by diff type to our existing ListRowDiffs RPC. The one
drawback of this decision is that using SQL to query diffs was not going to be part of
this version of diffs on DoltHub. However, we're going to keep that on our "eventually one
day" list because it would be really cool.
If you're curious about the dolt_diff_$TABLENAME table, all our table diffs now include
a "View SQL" link, which will generate and route to a dolt_diff_$TABLENAME query of the
current diff (although some queries, like those generated from pull request diffs, will
not return data).
The result
We moved forward with adding features #1-4 to our current diffs. We think it's a big improvement from what we had before, and we will continue to improve this page as more potential solutions come up.
1. Hiding columns
Clicking on a diff table header column will let you hide columns from the diff table.
For our bounty collecting US course catalog data (which is now private), the tables were very wide, and some of the columns were less important to review closely. Before hiding columns existed, we spent a lot of time horizontally scrolling back and forth to check the important columns. Now, we can easily hide less significant columns and view all the data we need in the same pane.
2. Filter by diff type
Every diff table has a filter dropdown that lets you filter diff tables by added, removed, or modified diff rows. This is especially useful for seeing checking if a bounty contributor has mistakenly removed or modified other contributors' (or their own) data.
In the logo classification bounty, contributors were asked to propose new brands and/or categories to add to the Logo-2k+ dataset. In one contributor's pull request during this bounty, they found a new version of brands they had previously submitted. This resulted in a lot of added rows, with a few modified ones. Checking just the modified rows is seamless when the filter is applied:
3. Make diff summaries work for all diffs
The diff reviewing process can be arduous for large pull requests, but it becomes almost impossible to do on the web when diff summaries time out and do not load.
For our hospital price transparency v2 bounty, we started with a cleaned version of our original hospital price transparency database, so this bounty started with a database at around 20GB with millions of rows. This bounty definitely tested the limits of Dolt and DoltHub's capabilities. The review process was especially painful because no diff summaries would load. The bounty administrator reviewing the submissions couldn't tell if a pull request was valid without pulling down the data to review locally with Dolt, which could be unnecessarily time consuming.
To solve this, we started storing materialized diff summaries in our database instead of calculating them on the fly every time the page is loaded. If the diff summary is not found in our database, an asynchronous operation is kicked off that continues to check back to see if the diff summary has materialized and stores it when it has. So now you'll notice that our diff summaries rarely time out (although sometimes they will initially take a hot sec to load).
This is a game changer for viewing diffs in our hospital price transparency v2 database, which is now 165GB:
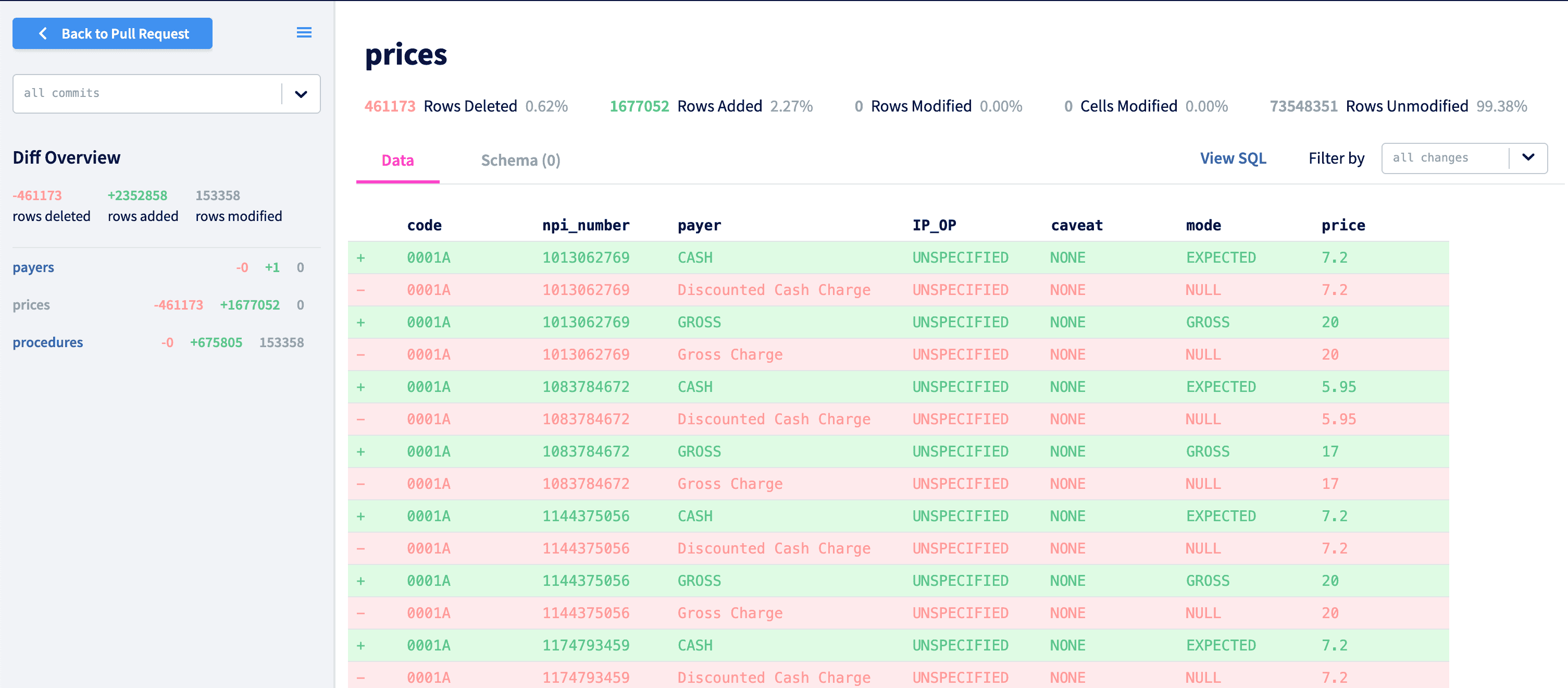
Hello 3 million row changes!
4. Redesign the diff page to make it more review-friendly
With all these new features, the diff page needed a makeover to show off its true inner beauty. The main pain point of the page was that the pane to actually view the data was too small and required clicking a button to load more rows. Also scrolling to navigate between tables could get cumbersome if you've loaded a lot of rows. No more relying on the GitHub metaphor for our data diffs.
We worked with our designer Jan to transform the page. We moved important diff summary information to a collapsible left navigation (inspired by our new database page) and there is now only one table visible within the main pane. This achieves a few things:
- Rows automatically paginate on scroll instead of paginating on clicking "show more"
- Can link to a specific table within a diff
- Focusing on one table at a time makes features such as filtering and hiding columns more obvious
- More room to view the actual data changes
Check it out in action:
Conclusion
We still have more work to do to continue to improve our diff page and the bounty submission review process. One day we want to be able to run SQL against diff tables. There's also more work we have to do to improve the bounty review process so that third parties can administer their own bounties, such as automating scripts to validate data submissions.
Have any ideas or feedback on our new diff page? Come chat with me on Discord in our #dolthub channel.