
Last Monday, we released our first data bounty to earn a share of $25,000 by wrangling US Presidential Precinct-level data. This blog will update you on the progress and encourage you to participate. Finally, we’ll get a little meta and let you know how we’re thinking about bounties moving forward.
Dolt is a SQL database with Git-style versioning. It’s the first SQL database you can branch and merge. DoltHub is a place on the internet to share and collaborate on Dolt databases. Without both, data bounties would not be possible.
The Results#
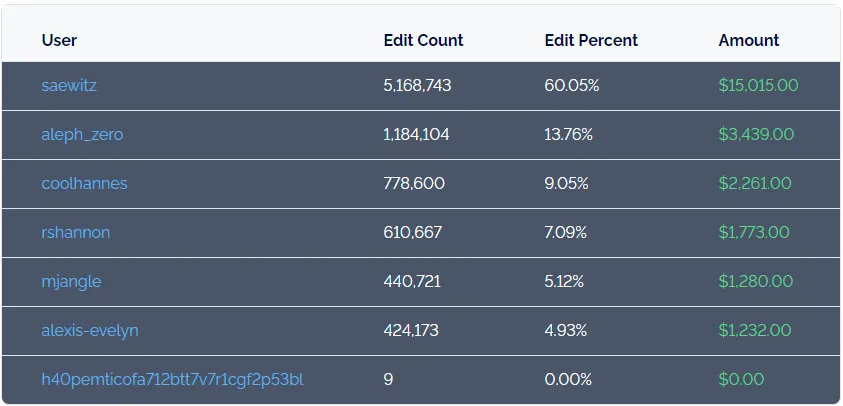
The bounty results so far have been fantastic. 6 people had 32 Pull Requests accepted. We’ve had over 8.6M cells edited in the database. All 50 states from 2016 are covered. 15 states from 2020 are covered.
If the bounty ended today, our top contributor would earn just over $15,000. Every participant would earn over $1,000. You can follow current payouts on the live scoreboard. Data wrangling for bounties can be lucrative work.
Feel free to clone the data and start analyzing it even if you don’t want to contribute. As updates are published just run dolt pull to get the latest results. Run dolt diff to see what changed. This is the power of using a version controlled database.
More to be done#
There’s plenty more work to do and thus, bounty to be won. The data from 2016 requires some cleaning. Where total vote counts are off a secondary source we need to figure out why and correct the data. As more states release precinct level data for 2020, that data needs to be added to the database. Some may have already released the data and a bounty participant can make a share of the bounty importing the data into Dolt right now.
For instance:
- There are all the missing 2020 states. Some Departments of State have published data that can be imported.
- If the state has not published data, large counties in the state may have. For instance Pittsburgh and Philadelphia have published precinct level results and we have accepted Pull Requests for those cities.
- Where the sum of votes in state as shown by this view does not match a secondary source like the New York Times, you can figure out why and make the necessary adjustments.
Read more about what needs to be done in the README.
Getting Meta#
We believe data bounties are a useful tool to create datasets. For $25,000, in one week we were able to assemble all of 2016 precinct data and about 20% of 2020 data. Not all of the 2020 data is even released yet. The low cost and speed of getting this dataset assembled should be attractive to data buyers everywhere. We need to get this story in the hands of people buying data and have them try running their own bounties.
We’re assessing options for our next bounty to start in mid-January. We’ve had requests for a machine learning focused bounty. We’ve also had customers ask for a US schools dataset. Those are the two leading contenders for the next bounty. If you have any strong opinions, hang out on our Discord and let us know.
Conclusion#
We’re going to be running more bounties soon. Bounties are really fun and collaborative. Work on open data, have fun, make friends, and get paid! Join us on Discord and let’s talk about how you can help.