
Dolt is Git for data and DoltHub is our web application that houses Dolt repositories. A few weeks ago I wrote about merging pull requests on DoltHub and our roadmap for “edit on the web”. We’re working on reducing friction for collaborating on data using Dolt and DoltHub, especially for users who may not be as familiar with Git or SQL.
Continuing on that roadmap, we just launched our first version of file upload on DoltHub. Users can now create a repo, upload a CSV to create a new table or overwrite an existing table, and create a pull request with the new changes.
Importing files using Dolt#
Until now, the only way to get data on DoltHub was to import a file using Dolt. This is what that looks like:
# initialize dolt repo
$ mkdir test-repo && cd test-repo
$ dolt init
Successfully initialized dolt data repository.
# import data from CSV
$ cat test.csv
id, animal
1, dog
2, racoon
3, bird
$ dolt table import -c --pk=id test test.csv
Rows Processed: 3, Additions: 3, Modifications: 0, Had No Effect: 0
Import completed successfully.
$ dolt status
On branch master
Changes to be committed:
(use "dolt reset <table>..." to unstage)
new table: test
nothing to commit, working tree clean
# add and commit changes
$ dolt add test && dolt commit -m "Create new table test"
commit e9hj7gsgq3u5phuladch2b0gvqdutiu4
Author: Taylor Bantle <taylor@liquidata.co>
Date: Fri Nov 13 11:53:19 -0800 2020
Create new table test
# add remote and push to DoltHub
$ dolt remote add origin test-org/test-repo
$ dolt push origin master
Tree Level: 2 has 3 new chunks of which 0 already exist in the database. Buffering 3 chunks.
Tree Level: 2. 100.00% of new chunks buffered.
Tree Level: 1 has 3 new chunks of which 0 already exist in the database. Buffering 3 chunks.
Tree Level: 1. 100.00% of new chunks buffered.
Successfully uploaded 1 of 1 file(s).While this works great, there may be some hurdles for those who aren’t as familiar with Git, and it also requires installing Dolt (which, like, you should do anyway because Dolt is awesome).
Either way, having more ways to get data on DoltHub only makes everyone’s lives better.
How file upload on DoltHub works#
Due to the timeliness of election season, I’m going to upload some election returns data from MIT Election Data + Science Lab. They have downloadable CSVs for the U.S. President, Senate, and House of Representative election returns from 1976-2018.
First, I need to create a new repository and go to the upload wizard. Since this a new repo, there won’t be any branches to make changes to. If this was a repo that already had branches, you’d be asked to select from the available branches. Changes will not be made directly to the branch you select, but to a new branch so a pull request can be created and reviewed before merging.
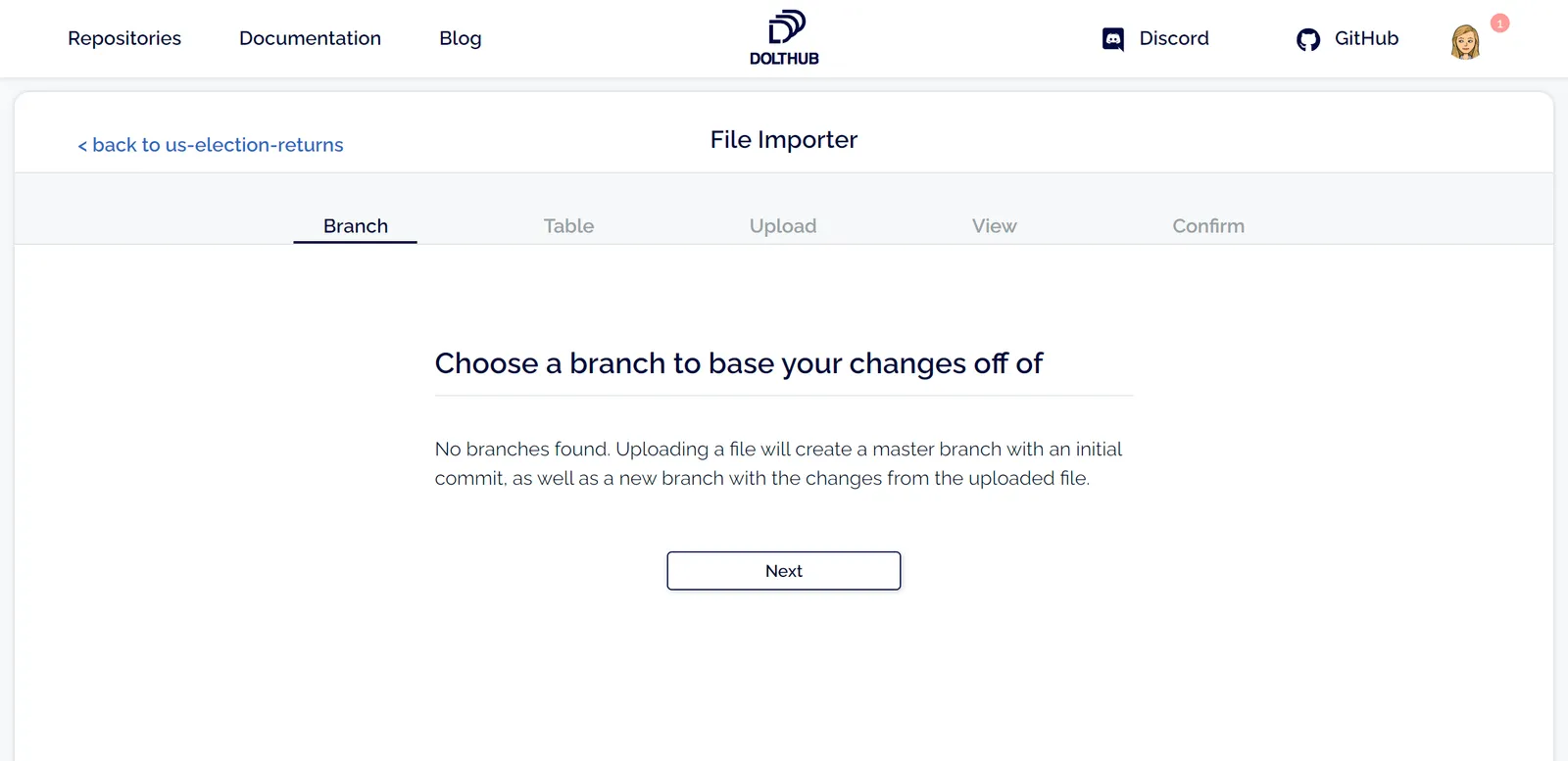
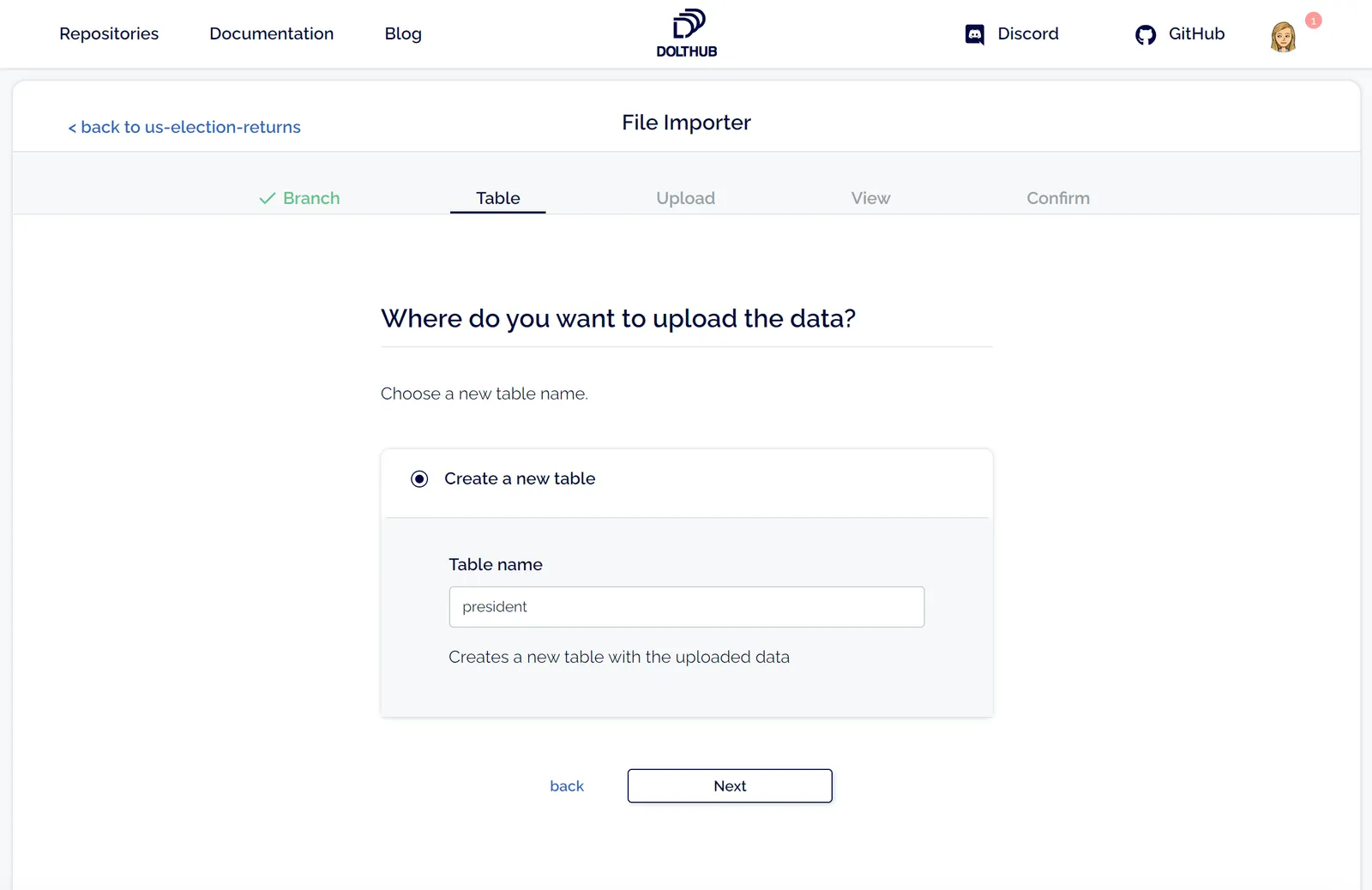
Next, I choose my table name. I’m going to start with presidential election returns, so this table will be named president. If there were already tables on your chosen branch, you would also have the option to overwrite an existing table.
Once I select my CSV, I’m asked to choose primary keys from the column names. These primary key columns should uniquely identify a row. This is what the presidential election returns CSV looks like:
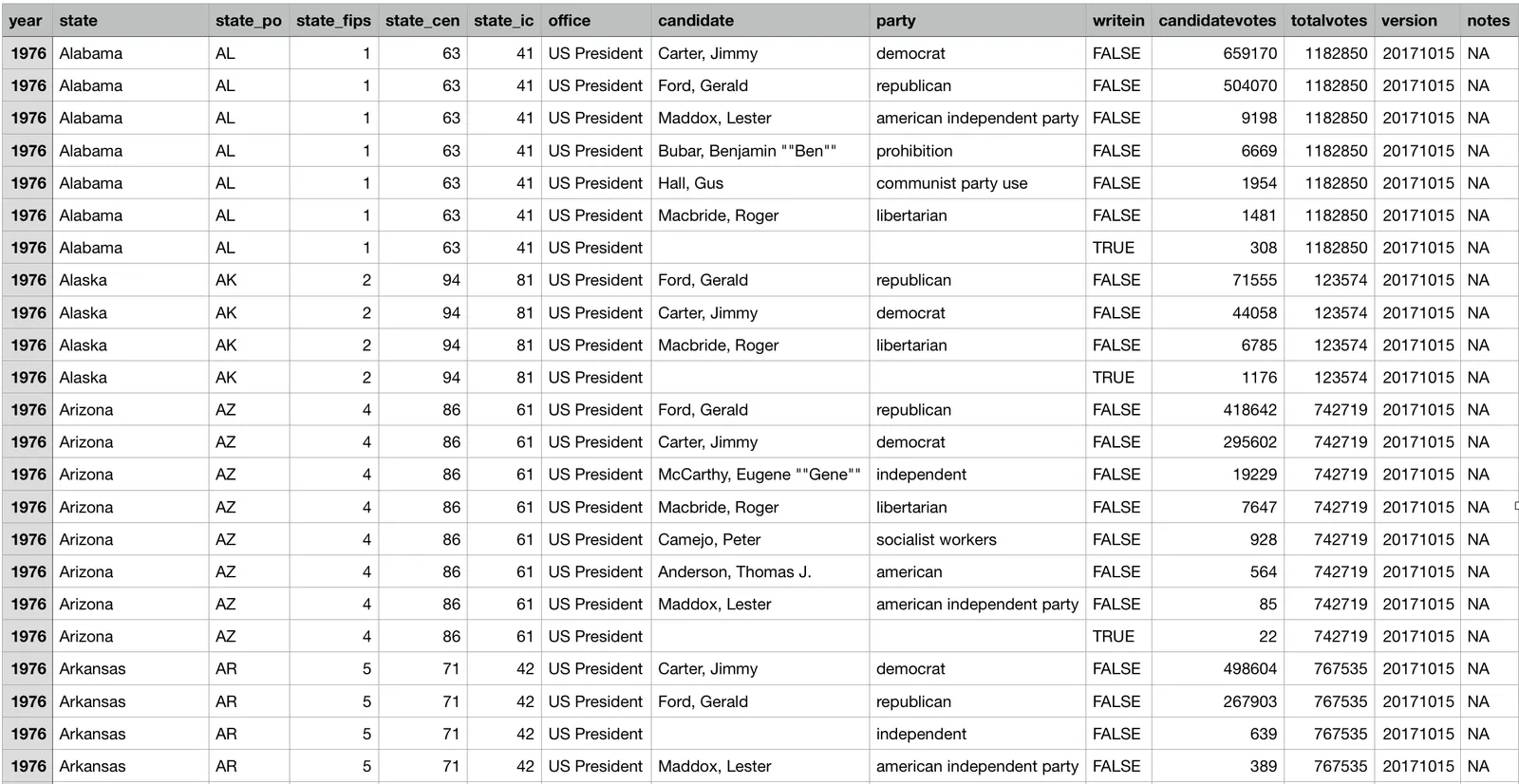
So using the year, state_po, candidate, and party columns as my primary keys seems like a reasonable choice.

As you can see, attempting to create a table with these primary keys resulted in an error. I have more than one row with the same primary keys. Looking at the data again, I realized there are sometimes duplicate rows for candidates for the same year and state for write-ins. Adding writein to the primary keys allows me to successfully view my changes.
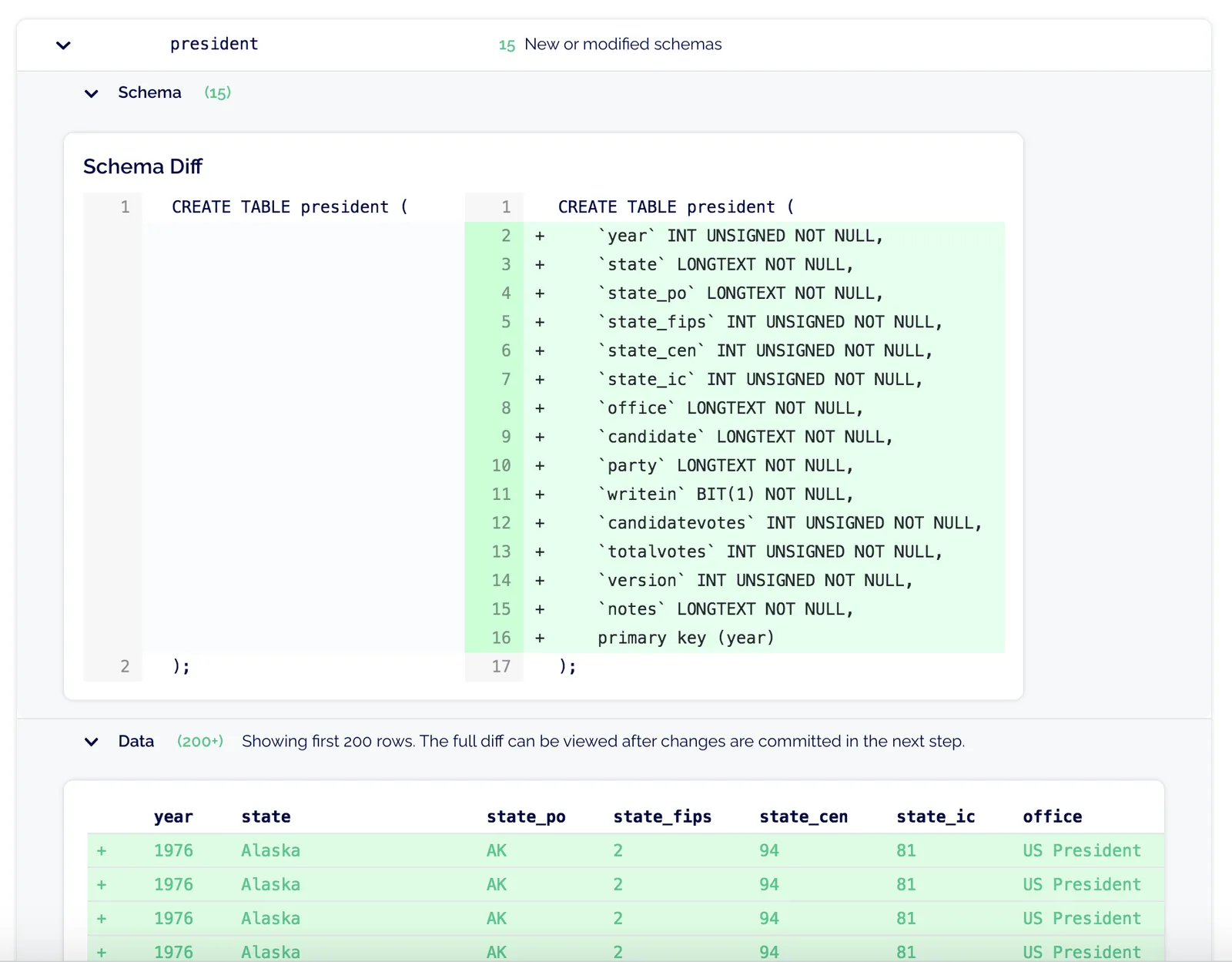
The changes in the diff preview (DoltHub can only show the first 200 rows) look good to me, so I can move on to creating a commit for the new changes.
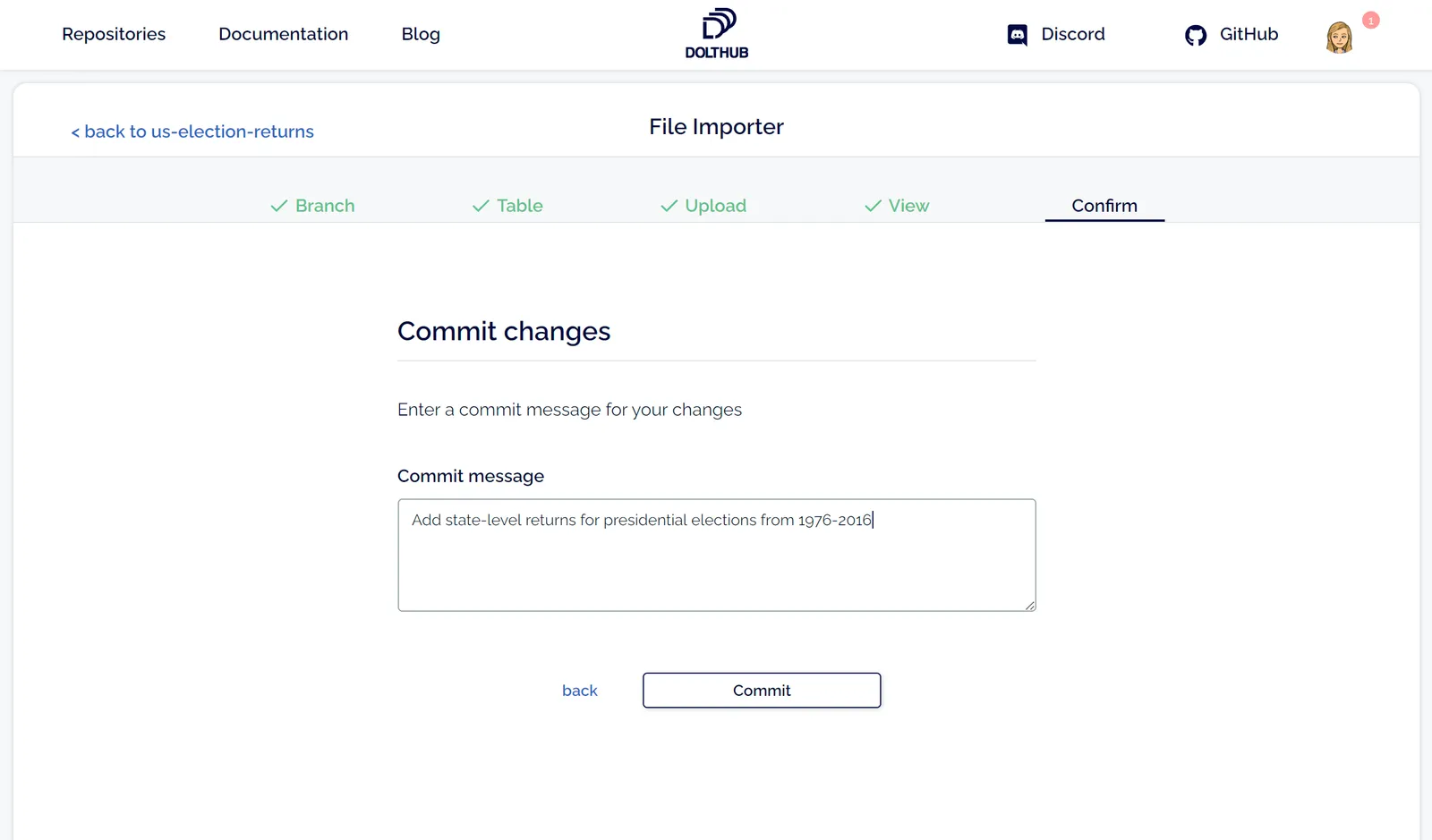
This will create a commit on a new branch. In order to get the commit with my changes in my desired branch (in this case master), I need to create a pull request (don’t forget to cite your sources!).
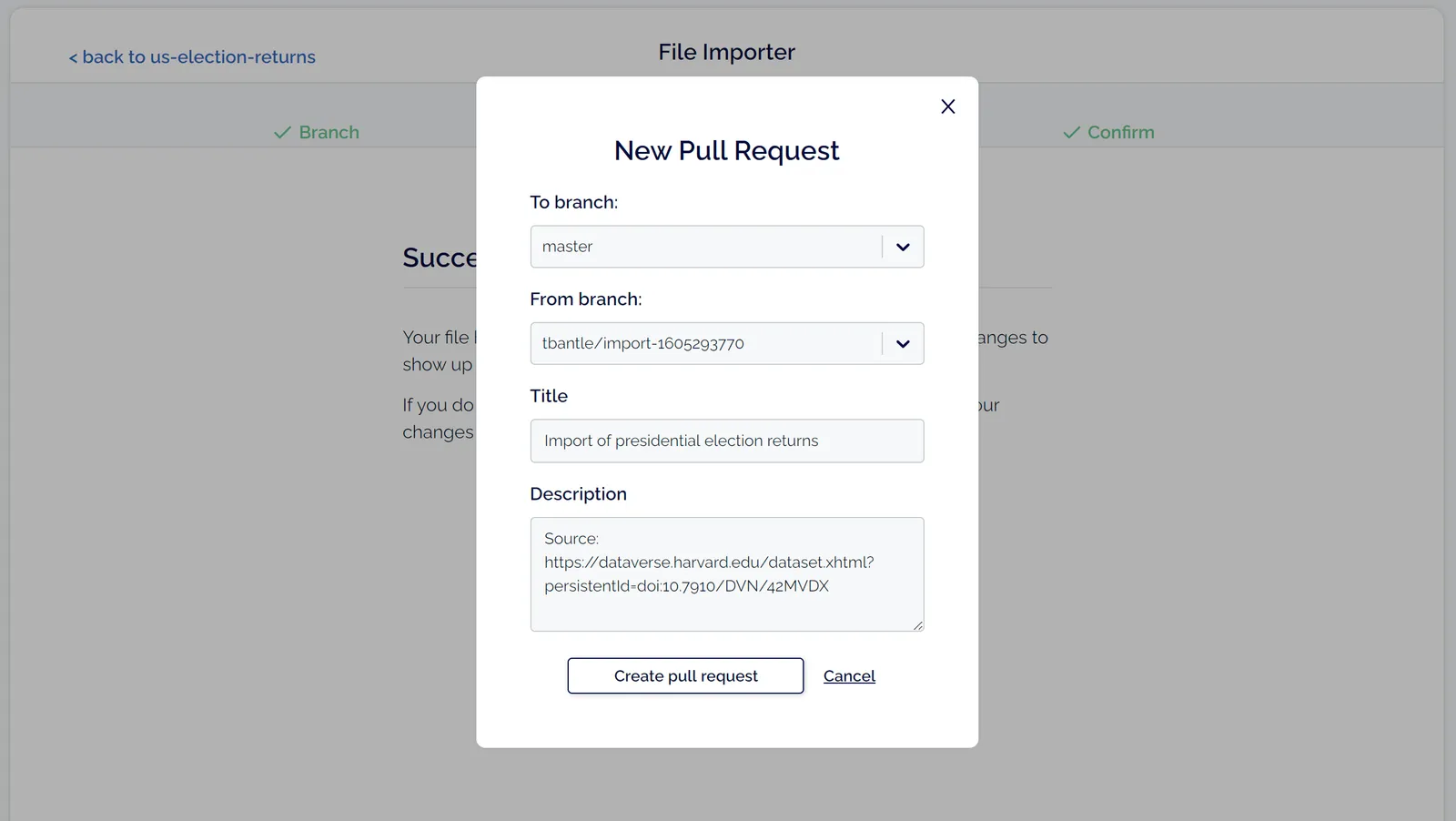
You can view the pull request for my new president table here. You can see that 3,740 rows were added. I merged this pull request, so now my commit with my new table is in the master branch!
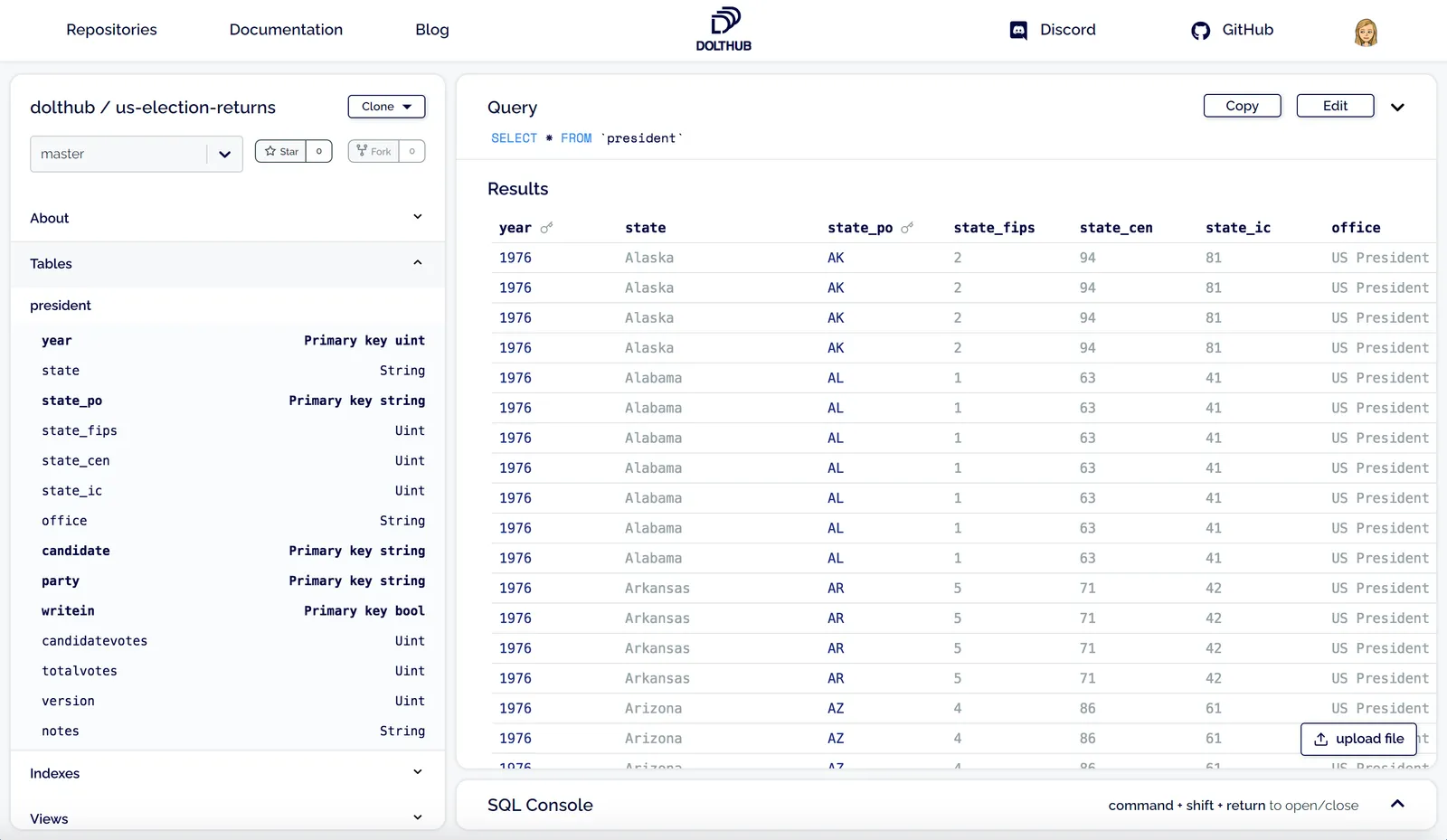
I have since uploaded data for the Senate and House of Representatives election returns. Anyone can now run queries against this data, clone it with one command, or fork the repo and make their own contributions.
What’s coming for file upload#
This is just the first step to make it easier to get data from files into DoltHub. V1 of file upload has some restrictions, and here are some ways we’re going to improve it in the next few weeks:
- Add options to update or replace a table instead of only creating and overwriting tables
- Add support for larger files (current max is about 4MB) and more file types (PSV, XLSX, JSON)
- Ability to update the inferred schema before creating a commit (i.e. change column types or names)
Conclusion#
We’re excited for what’s to come for editing data on DoltHub. If you need a reminder, check out our roadmap for edit on the web. If you have a request for a feature like this or to move up the timeline for something already mentioned, please contact us!