
Dolt is a SQL database with Git-like version control features. It presents a familiar SQL interface while exposing Git-like primitives for versioning tables and their data. Doltpy is a Python API for interacting with Dolt in Python. This post details our motivations and goals in creating Doltpy.
Why Python#
Doltpy is the only API for Dolt that is not part of Dolt itself, so it’s worth going over why we chose Python above other candidates. We anticipate most interactions with Dolt taking place via SQL, specifically via MySQL connectors. You can see from our programmatic clients documentation that implicitly means we support using SQL in a lot of different languages.
With such wide language support for the SQL interface, the motivation for a non-SQL API was to expose the Git-like command line interface for managing the version control features of Dolt. Our prior was that this functionality was most interesting to data scientists and data engineers wanting to take advantage of a version controlled SQL database in their existing infrastructure. Our perception was that Python was the language of choice in such contexts, so that’s where we chose to start.
In fact, what motivated me personally to join DoltHub was precisely struggling with implementing reliable data engineering workflows in Python on top of existing relational database solutions. I want to briefly visit those experiences to provide some context for our desire to make Dolt easily available to folks doing data engineering in Python.
Motivation#
Prior to joining DoltHub I worked on the Research Engineering team at a quantitative hedge fund. The team’s objective was to provide the tools and data our researchers needed to produce a portfolio that could beat the market. A major motivation for joining DoltHub was the friction involved with the data delivery component of this work. Too much time was spent on code that loaded the contents of CSV, JSON, and other types of files into our databases. Additionally, data often arrived with errors, requiring “defensive engineering” to account for malformed files and type errors. And even when data was well formed and correctly typed it could still contain factual errors requiring the vendor to republish. The architecture looked something like this:
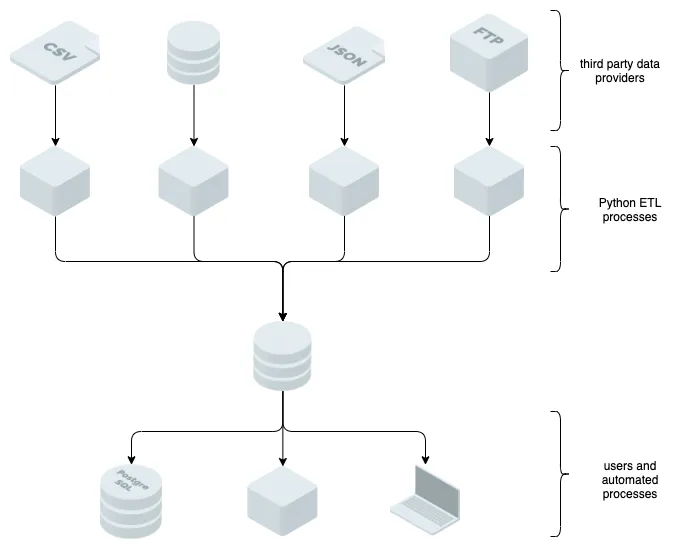
Dolt provides version control tools for your data tables, and can be used to implement a more robust data architecture without writing additional logic into the application layer of your ETL tooling.
Dolt as an Internal Database#
Using Dolt as an ingestion point for external data allows users to preview and debug data issues before merging them into their production copy. This is the value of using a database that natively supports branches. Branches also allow for maintaining local overrides. This was a common need in my case. The diagram below illustrates how to use AS OF syntax to examine different versions of the data. No application layer code is required to achieve this setup, simple writes to Dolt suffice:
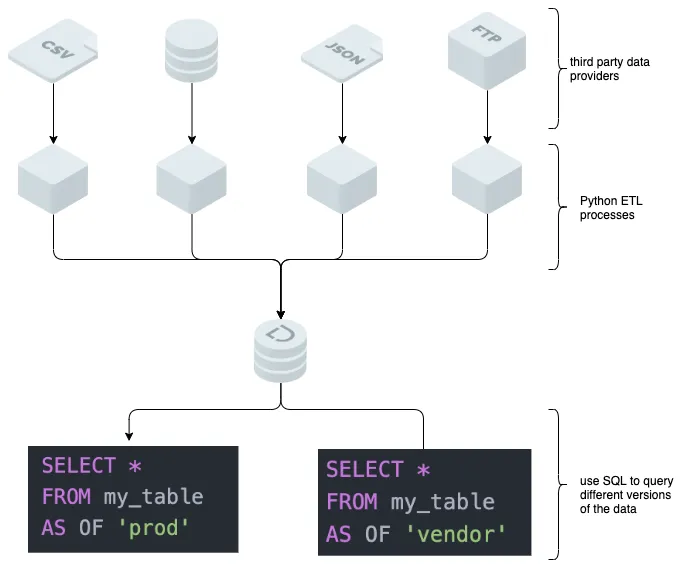
The branching mechanism also lets users work on fixes to a dataset with zero downtime: consumers can can continue to operate seamlessly against the current production dataset while issues in the vendor data are resolved.
The goal of Doltpy is to make it easy for organizations, individuals, and teams that use Python for data engineering to take advantage of Dolt’s unique value proposition.
Installation#
Before diving into the details, we cover installation. Doltpy is published on PyPi, and you can install it easily using pip:
$ pip install doltpyDoltpy Design#
Dolt offers a standard SQL query interface, as well as Git-like command-line interface (CLI) for managing the commit graph used for storage. The goal of Doltpy is to expose all of this functionality in Python.
CLI#
Doltpy implements top level functions on the doltpy.core.Dolt class to mirror almost all of the command line. Where appropriate, Doltpy returns data structures which can be inspected programmatically. By way of example consider the dolt ls command which lists the tables in the current database context, that is the Dolt database stored in ./.dolt.
First, let’s look at the output from cloning a database and running dolt ls at the command line:
$ dolt clone dolthub/doltpy-example && cd doltpy-example
cloning https://doltremoteapi.dolthub.com/dolthub/doltpy-example
8 of 8 chunks complete. 0 chunks being downloaded currently.
$ ls -ltra
total 16
drwxr-xr-x 3 oscarbatori staff 96 Oct 26 10:13 ..
drwxr-xr-x 6 oscarbatori staff 192 Oct 26 11:52 .dolt
-rw-r--r-- 1 oscarbatori staff 87 Oct 26 11:53 .sqlhistory
drwxr-xr-x 5 oscarbatori staff 160 Nov 1 11:19 .
$ dolt ls
Tables in working set:
testThe Doltpy equivalent would be:
from doltpy.core import Dolt
dolt = Dolt.clone('dolthub/doltpy-example')
tables = dolt.ls()
for table in tables:
print(table.name)Executing this code block produces the following output:
testNote that we saw two Dolt commands here, clone and ls, mapped to two Python functions. Let’s look at the signature of clone, noting this is a static function on the Dolt class that returns an instance of Dolt class:
@staticmethod
def clone(remote_url: str, new_dir: str = None, remote: str = None, branch: str = None) -> Dolt:On the other hand ls is a method bound to an instance of the Dolt class:
def ls(self, system: bool = False, all: bool = False) -> List[DoltTable]These two functions show how we model the fact that the Dolt CLI offers commands for creating and cloning Dolt databases, and then commands for interacting with those databases. Essentially, static methods and constructors return a Dolt instance, while methods bound to an instance interact with a specific Dolt database.
There are three ways to get a Dolt instance:
Dolt.clone(...)returning an instance ofDoltrepresenting the database that has just been clonedDolt.init(...)creating a Dolt database in current working directory and returning an instance ofDoltbound to thatDolt('path/to/db')returns an instance ofDoltbound topath/to/db
Having covered how the Dolt CLI is exposed in Python, we move on to SQL.
SQL#
Doltpy’s SQL functionality is built on top of SQL Alchemy, something we have previously discussed in the context of using the SQL Alchemy expression library to sync Dolt with other SQL implementations (Postgres, MySQL, Oracle). To start using the SQL interface via Python let’s return to the test database from the previous section and start the server:
$ dolt sql-server
Starting server with Config HP="localhost:3306"|U="root"|P=""|T="30000"|R="false"|L="info"The Dolt class has a method called get_engine that returns an instance of sqlalchemy.engine.Engine. Let’s get an instance of Dolt, and then use get_engine to interact with the database:
dolt = Dolt('~/doltpy-example')
engine = dolt.get_engine()
with engine.connect() as conn:
res = conn.execute('show tables')
for row in res:
print(row)This produces the following output:
11-01 12:37:30 doltpy.core.dolt INFO Creating engine for Dolt SQL Server instance running on 127.0.0.1:3306
('test',)You can read more about SQL Alchemy’s engines here, but this quote gives the basic idea:
The typical usage of create_engine() is once per particular database URL, held globally for the lifetime of a single application process. A single Engine manages many individual DBAPI connections on behalf of the process and is intended to be called upon in a concurrent fashion. The Engine is not synonymous to the DBAPI connect function, which represents just one connection resource - the Engine is most efficient when created just once at the module level of an application, not per-object or per-function call.
In our example, we used the default server config (127.0.0.1:3306), but this and other server configurations can be specified. The Dolt constructor takes a doltpy.core.ServerConfig parameter, which can be used to configure the specifics of where your server is running (hostname, port, etc.), and it exposes all the configurations that the dolt sql-server command provides.
Read and Write Utilities#
Doltpy also offers some convenience functions for common reading and writing operations in doltpy.core.write and doltp.core.read. For example, you can import a list of dictionaries as follows:
def import_list(repo: Dolt,
table_name: str,
data: List[Mapping[str, Any]],
primary_keys: List[str] = None,
import_mode: str = None,
batch_size: int = DEFAULT_BATCH_SIZE)The doltpy.core.write module also has import_dict for importing a dictionary of lists, with a list representing a column.
Examples#
We have written elsewhere about how to make use of Doltpy. We revisit a few examples.
Notebook#
We recently published a blog showing how to use Deepnote, a cloud hosted Jupyter Notebook runtime, alongside Doltpy to acquire and analyze data. We believe that being able to clone a database in a single command, and then update your data simply by calling Dolt.pull is vastly superior to sullying your analysis with data munging logic. Furthermore, writing data munging and analysis code that seamlessly absorbs updates is far easier when data preparation is a mere SQL query.
You can find the notebook itself here. This example would work just as well in a local Jupyter runtime.
ETL#
An extension of Doltpy is the doltpy.etl module that builds on top of doltpy.core to offer functions for common ETL patterns. You can find an example of this in the dolthub-etl-jobs GitHub repository. The linked file is Python code that we run on our internal Airflow instance to regularly populate a Dolt database with updated IP to country code mappings.
SQL Sync#
The SQL Sync module of Doltpy, doltpy.etl.sql_sync, provides tooling for syncing to and from Dolt and other relational databases. In conversations with customers we frequently heard that while they were excited about Dolt’s features, they needed Dolt to play nice with existing relational database infrastructure. SQL Sync attempts to bridge this gap for our users.
Suppose we wanted to sync some data from a running MySQL instance to the Dolt database we cloned earlier in this post. SQL Sync makes it relatively straightforward to replicate the data and schema, allowing us to version an existing database:
import sqlalchemy as sa
from doltpy.etl.sql_sync import (sync_to_dolt,
get_dolt_target_writer,
get_mysql_source_reader,
sync_schema_to_dolt,
MYSQL_TO_DOLT_TYPE_MAPPING)
mysql_engine = sa.create_engine(
'{dialect}://{user}:{password}@{host}:{port}/{database}'.format(
dialect='mysql+mysqlconnector',
user=mysql_user,
password=mysql_password,
host=mysql_host,
port=mysql_port,
database=mysql_database
)
)
# Sync the schema
sync_schema_to_dolt(mysql_engine,
dolt,
{'revenue_estimates': 'revenue_estimates'},
MYSQL_TO_DOLT_TYPE_MAPPINGS)
# Execute the sync
sync_to_dolt(get_mysql_source_reader(mysql_engine),
get_dolt_target_writer(dolt),
{'revenue_estimates': 'revenue_estimates'})You can read more about SQL Sync here.
Conclusion#
We covered a fair amount of ground. We started by revisiting some of the motivations for Dolt and Doltpy, specifically in a setting where Python is being used for data engineering. I dipped into my professional background to provide additional context. We then examined the design principles used in Doltpy by way of example.
Finally we concluded with some concrete examples of how to make use of Doltpy for some common ETL and analysis use-cases.