
Dolt is a version controlled SQL database. What that looks like in practice is a SQL engine sitting on top of a commit graph like storage format. Dolt SQL is a superset of MySQL that provides access to the database at every point in the commit graph. Visually that looks something like:
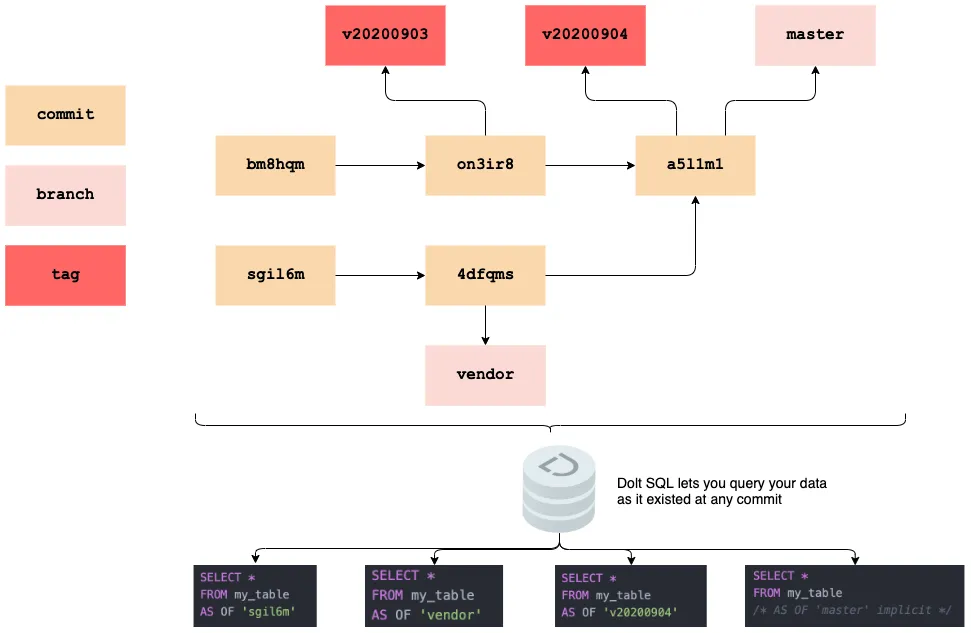
In this post we explore using Dolt as a service for storing third party datasets and ensuring the integrity of your “data environment”.
Motivation#
In the past we wrote about using Doltpy, our Python API, to sync between Dolt and existing relational database implementations. You can find a comprehensive guide in our doltpy repository. Our users were enthusiastic about storing data in a commit graph to get the benefits of version control, but needed Dolt to work seamlessly with their relational database.
Previous posts focused on the technical details of performing a sync using our Python API, this post details how to detect changes in a Dolt database to trigger downstream processes that query data in Dolt:
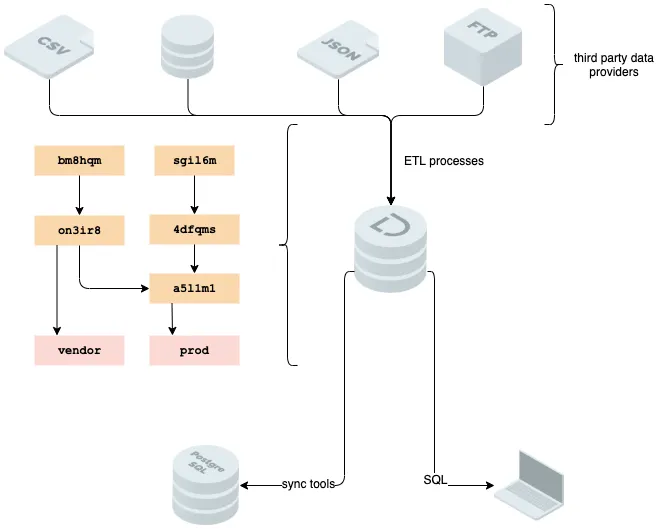
While we think the SQL interface provided by Dolt is useful for exploring data, and works well with existing infrastructure, we recognize that for some use-cases users will want to get data into a system that makes different performance tradeoffs.
Detecting Changes#
We now detail how to augment your Dolt database so that a reader can detect and pull only the changes that arrived in Dolt since the reader last read from Dolt. This allows downstream processes to run an event loop, periodically connecting to Dolt, checking for changes, and then syncing any newly arrived data.
Essentially, each consumer logs its ID, and commit when it consumes the data for a given commit in a pulls table:
CREATE TABLE pulls (
`job_id` VARCHAR(16),
`commit_hash` VARCHAR(32),
PRIMARY KEY (`job_id`, 'commit_hash')
)Note that we chose to store the state in in a Dolt table, however, we could have stored this anywhere. For example, S3 would be another perfectly reasonable choice.
Upon starting the consumer queries the dolt_log system table for any commits that are not in the pulls table as follows:
SELECT
`my_col_1`,
`my_col_2`,
...
FROM
`dolt_history_my_table`
WHERE
`commit_hash` IN (
SELECT
`commit_hash`
FROM
`dolt_log`
WHERE
`commit_hash` NOT IN (
SELECT
`commit_hash`
FROM
`pulls`
WHERE
`job_id` = 'my_job_id'
)
)This will allow the consumer to grab every record at every commit that they have not previously consumed, including those that are updated. Once the consumer has processed the records they can record this in the pulls table:
WITH `commits_consumed` AS (
SELECT
`commit_hash`
FROM
`dolt_log`
WHERE
`commit_hash` NOT IN (
SELECT
`commit_hash`
FROM
`pulls`
WHERE
`job_id` = 'my_job_id'
)
)
)
INSERT INTO `pulls` (`job_id` VALUES `commits_consumed`)Thus consumers can be stood up, and seamlessly catch up with the Dolt database. Job ID is just an arbitrary identifier for a unit of work so that a consumer can re-identify itself. It might be called consumer ID. It merely is a way for a consumer to ensure that it is capturing all the data in the underlying commit graph. This SQL query could be customized arbitrarily to ignore data before a certain point in time, for example:
+-------------+----------+
| field | type |
+-------------+---------
| commit_hash | text |
| committer | text |
| email | text |
| date | datetime |
| message | text |
+-------------+---------Conclusion#
In this post we laid out an architecture for users to implement Dolt as a tool for managing incoming third party data, ensuring it is robustly versioned, and then detecting and syncing changes to existing data infrastructure. We will be creating a more detailed version in our documentation that dives into greater detail.