
On June 13th, 2016 Microsoft acquired LinkedIn for $26.2 billion due to its ability to successfully monetize the resumes of its users. They have proven the value of a resume database and sell premium services that let recruiters search this database with powerful tools, and contact its users. Users freely give their data to LinkedIn and LinkedIn sells that data. Since 2014 LinkedIn has been pursuing legal action against companies that scrape their site[1] in order to keep that data for themselves.
I don’t want LinkedIn to think they own my data, so I decided to create an open resumes database, and I think this has a lot of advantages.
- More distribution for my resume - My resume is publicly viewable on LinkedIn, but finding it could be difficult for people that don’t pay for LinkedIn’s premium offering. LinkedIn limits the number of searches a user can perform, the number of search results returned, and limits the people in the results based on our relationship. It is possible for my profile to be found via a Google search, but this is not a great strategy for searching resumes.
- Companies can see the market without paying - LinkedIn makes billions of dollars charging companies to access this data. This may help large companies that can pay for the data, but it hurts small companies, and hurts job seekers as it limits the companies that are able to find them and view their resumes.
- It facilitates competition - If the data is open, then newcomers that come into the space and want to compete with LinkedIn start from a much better position than if they had to bootstrap their resume database from scratch.
- Job market research becomes possible - In the meta, people’s resumes (and the changes to them) can be used en masse to do a whole host of research For instance, resumes could be used to get a better sense how the economy is doing or help with analysis of job market shifts. This type of research becomes impossible when the data is locked up in LinkedIn.
Getting my Resume from LinkedIn#
I attempted to download my resume from LinkedIn and discovered that taking my data to another platform was easier said than done. I started by going to my profile and selecting the “More” button where I was presented with the options to “Save to PDF” or “Build a resume”. Now PDFs are great for rendering text for human readers, but extracting data from a PDF and inserting it into a database is not an easy task, so I looked into the “Build a resume” option. If you do build a resume, the only option for saving it is as a PDF.
Now LinkedIn does have a section within settings where you can download your data. There is a lot of data available, and you can customize the data that LinkedIn packages up for you by clicking a few check boxes.
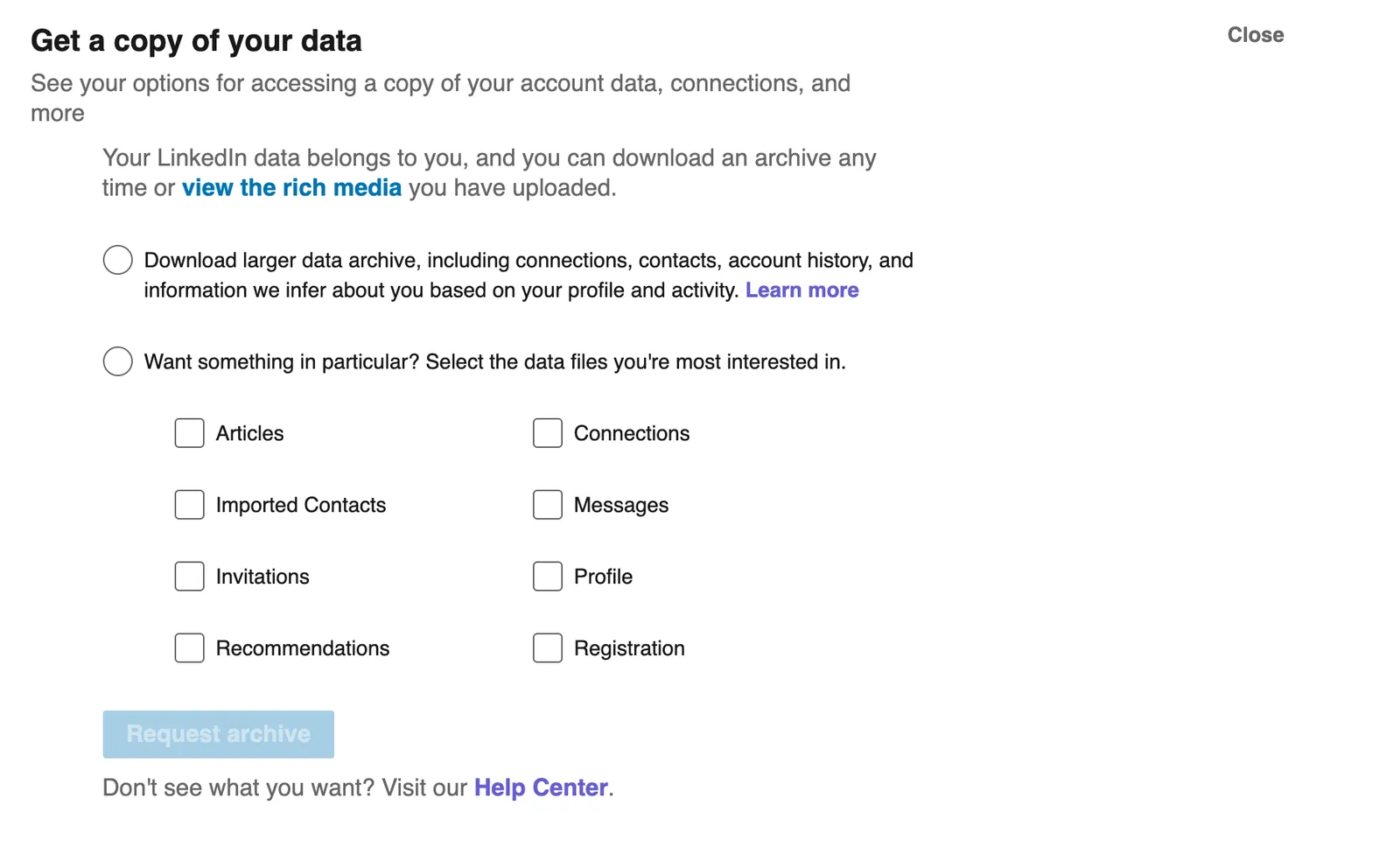
Looking at the options available, it seems like selecting “Profile” would give me the data that I want, so I select it and have to wait up to 48 hours for that data to be available with the hopes that it contains the data I want. It doesn’t, and waiting another 48 hours to try again in the hopes that I can find the right combination of check boxes to get the data I want is unnecessarily tedious. Instead of getting my full profile I get a CSV that contains only this data:
First Name,Last Name,Maiden Name,Address,Birth Date,Headline,Summary,Industry,Zip Code,Geo Location,Twitter Handles,Websites,Instant Messengers
Brian,Hendriks,,,,Software Engineer and Founder at Dolthub,,Computer Software,,"Los Angeles County, California, United States",,,Now a csv with my resume would have been great as it would be easily portable to other resume databases, but LinkedIn doesn’t want that. They make it easy for you to get a copy of your resume that you can print out, email, or for their users to view on the web, but they do not want you to take your resume to another platform, so they make this as hard as possible.
Evaluating my Options#
Because LinkedIn won’t let me have a copy of my data in a format that can be easily imported to another database, I am left with 4 options.
-
Download as a PDF - The pdf version of the resume certainly has all the data that I’m looking for, however I have no experience extracting data from pdf files. There exist several libraries for working with pdf files, but the biggest challenge is getting enough samples to feel comfortable that my scraper will work for most resumes. I’m sure I could reach out to my contacts, and hassle friends to generate these for me, but I would have to do that every time the format changed, or someone encounters an issue.
-
Use the “Build a resume” option and then download the HTML - Now scraping a webpage is something I’m more familiar with, but the issues are the same as 1. I would still need users to generate and submit these html pages so that I could make sure the scraper is up to date and working.
-
Scrape resume from LinkedIn profile page - This page is a little more complicated, as it dynamically loads some of its data using javascript. In order to get all the data I’m looking for web elements will need to be scrolled into view and in some cases clicked. One benefit is that I can visit hundreds of my contacts pages at any time and validate that the scraper is working for a good sample size. Additionally, I have the ability to scrape links to companies and schools while I’m at it, and then scrape their publicly accessible data.
-
Use an existing scraper such as ScrapedIn. Using an existing scraper would have saved a lot of time, however none of the scrapers I looked at would scrape school or company data, and all of them failed on some percentage of the profiles in my contacts. They would have required a lot of work to add the features I wanted, and the projects were primarily in languages that I don’t have a ton of familiarity with.
In the end I wrote my own scraper to scrape resumes, and company and school information.
Open Data Collaboration and Forks on DoltHub#
In building a scraper to allow users to get their data from LinkedIn in a format that can be imported into other resume databases, and an importer to import this data into the dolt Open Resumes database, we ran into a road block. Currently, in order to be able to submit a PR to a repo on DoltHub you need to be a collaborator. This is not a scalable approach for a large open data project where we hope our users will contribute their resumes. In order to support this we need support for forks. Forks are currently in development, and we will be back with part 2 of this Open Resumes blog post once forks are out.
We think Dolt and DoltHub are ideal to host this type of collaborative dataset. A centralized gatekeeper can review submissions for quality. When resumes change, you can see diffs. Diffs are useful for quality control and time series analysis. The data will be easy to download and analyze with a few commands, no messy importing required. Here’s a sample of our company’s data as a preview of open resumes. Stay tuned.