
Dolt is a SQL database with Git-style versioning. DoltHub is a place on the internet to share Dolt databases. In this blog post we discuss our search for Dolt’s Linux.
Git#
Git was built to manage the Linux open source project. Lore has it that Linus Torvalds, the eponymous creator of Linux and Git, became enraged at BitKeeper and wrote Git in a week as a replacement. But Git always had Linux, the world’s most popular open source project for support. Would Git be as popular if not for Linux?
Adoption certainly would have been an uphill battle. Git has a notoriously weird interface. git checkout both switches branches and restores files?!? Git’s model takes a bit of getting used to. For instance, the concept of and push, pulling, and cloning remote repositories is pretty alien to classic version control systems. Maybe Git would have become the world’s default version control system without Linux, but it seems less likely.
Dolt#
Dolt is the first database where you can merge two copies, the fundamental piece of version control that allows for distributed collaboration. Merge is a tricky technical challenge and we designed Dolt from the ground up to be good at it. We cloned the interface of Git, but applied the operations to tables, not files. For Git users, Dolt will feel very familiar.
Once we released Dolt in August 2018, we knew the best way to show off its capabilities was to put data in it. Since then, we’ve developed some expertise on open data, what exists, what formats does it live in, and how often it is updated.
Can Dolt be successful without an extremely popular open data project akin to Linux? We think so. The tool is extremely useful for sharing data within teams. Diffs on your database are an incredible tool. But we also think we can hasten Dolt’s adoption with an extremely compelling open data use case. What would that look like?
The State of Open Data#
The open data world feels a lot like the open source world did pre-Apache. Effort is really distributed. You have to search really hard to find things you might be interested in. We have not agreed on a distribution format. It’s not even clear whether open data model will “catch on” in a mainstream way like open source has.
Generalizing, there seem to be two forms of successful (ie. used, discussed) open data projects. The first is government data. The second is what I like to call “*NET” (ie. WordNet, ImageNet, etc) data used as benchmark datasets for machine learning models.
Government data is data maintained published by various layers of government in different countries. Being based in the US, most data we encounter is from the US Federal government or large city governments. Notable datasets are the National Oceanic and Atmospheric Administration (ie. NOAA) weather dataset and the Internal Revenue Service Statement of Income (IRS SOI) dataset. Government data tends to be of high quality but the format of distribution varies and it is difficult to find. During the Obama administration a big push to move data to data.gov was an attempt to solve both these issues.
The *NET datasets started as datasets published by academia to benchmark some sort of machine learning task. How well does your algorithm perform against this standard set of data? Recently, machine learning organizations within private companies have also released these style datasets. Examples of this category of open data are WordNet and ImageNet. ImageNet is probably the most famous open data project, widely credited with spurring the rapid advancement in computer vision in the last decade.
There are other cool open data projects that do not fall into the above two categories. Open Street Map is one my teams have used in the past when sourcing location data. Wikipedia could even be thought of as am open data project though it is not generally presented in the form of data.
Open data lacks a central channel for enthusiasts to collaborate. The closest is Kaggle. Kaggle started by hosting Machine Learning competitions and the associated *NET style data associated with the contests. Recently, Kaggle has evolved into more of a data hub, allowing users to publish data not associated with contests.
You also have CSVs (and other file types) distributed on GitHub, treating open data like open source. For instance, [FiveThirtyEight.com] publishes all the data they generate for their articles this way. Publishing data as files on Git is a half step towards true versioning of data. You get easy distribution but you don’t get purpose built diff and merge functionality for data. Two people editing the same file will have a hard time collaborating.
As you can see, the space is fragmented and messy. This was the inspiration for starting DoltHub. Could we build a tool that brought together all this fragmented interest? We thought a key missing ingredient in the open data community was a data format designed specifically for data collaboration. So, we built Dolt.
Our Data Journey#
What have we done to find the Linux of datasets? We started simple and worked up the difficulty curve. ImageNet seems to be the most famous open dataset. How could ImageNet have started on DoltHub?
We have imported hundreds of datasets into Dolt over the past year. Our strategy was to start easy, get some experience with Dolt, and work up the difficulty curve. Secondarily we optimize for how cool the data would be in Dolt. Is it updated? What would the diffs look like? Would a SQL version make the data more accessible? Is it a reasonable size so that queries won’t take too long?
We find interesting datasets through search or social channels. When we think Dolt would add value to a dataset, we start the process of importing it. This generally means understanding the distribution format and the data itself. What is the schema? How are the values represented? We write an import script with the intent of turning it into a recurring job for our Airflow instance.
Once we get the schema and import correct, we schedule the airflow job and wait for it to fail. When it fails, we fix it. In between failures, we get updates. You can see the progress on the DoltHub discover page and our GitHub repository with our Airflow jobs. Just managing Airflow (or another competing job scheduler/executor) is non-trivial.
This is tedious work that is repeated by everyone trying to ingest these datasets into their environments. Every data scientist or engineer has learned to hate NULL. Dolt’s promise is that we solve the NULL problem (and other classes of the weak schema to strong schema data translation) once as a community and move on to actually analyzing data. To do this, we should share the data in a more descriptive format. Dolt is that format. First, we’ll consume published data the same way as everyone else. Eventually the format will catch on and publishers will publish directly in Dolt format. That’s the plan anyway. The data exists in a strongly schemaed place in the first place. Why write code to take it out and code to put it back in the database? Just share the database. If the data is too raw, just make a SQL View of the thing you want to share. Views are versioned in Dolt.
Through this work, the following pattern has emerged. The more difficult the import, the more value Dolt adds exponentially. The format of the dataset implies an import difficulty. We started with easy imports and have been working our way up the value curve.
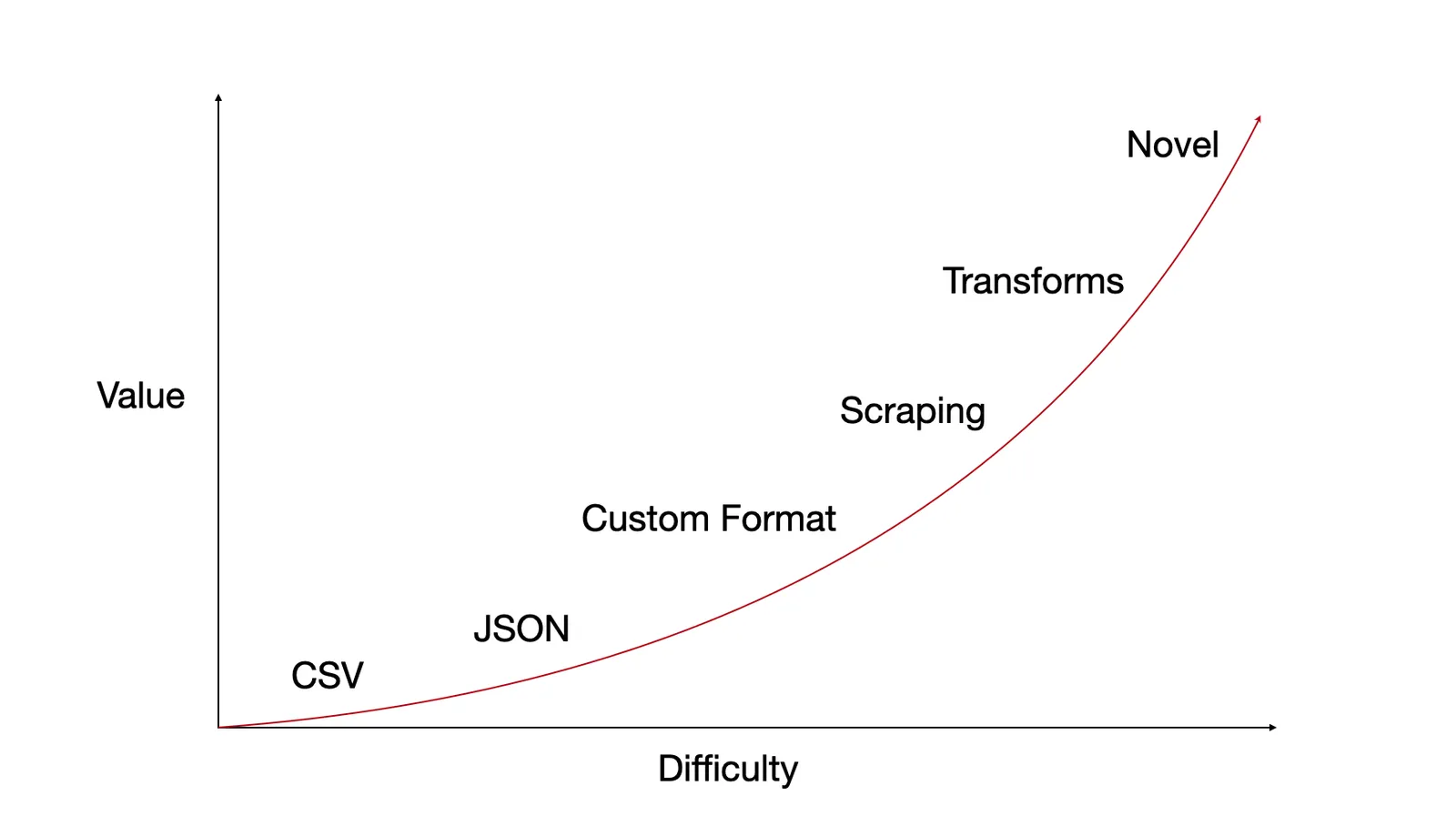
CSV files are generally pretty easy to put in Dolt. The data already looks like a table. You have some schema wrangling to do but dolt schema import does a pretty good job getting the schema correct. Putting CSVs in Dolt allows for a SQL query interface and one command distribution. You also can see diffs if the dataset is updated. That said, the utility of Dolt has not seemed to attract as much interest as going directly to the source to get the CSV. It’s unlikely taking data already distributed as a CSV and putting it on Dolt will generate a Linux open data project.
The next level of challenge is JSON. JSON data is often hierarchical so in that case, you need to write some parsing logic to flatten the data into tables to put it into Dolt. Once your done, you still get all the benefits of Dolt: SQL, types, easy distribution, diffs. Again, deconstructing JSON back into a database form is unlikely to yield the open data Linux.
This is where the search for the open data Linux starts to get interesting. There is a lot of interesting data, especially government data, that is distributed in some pretty esoteric formats. This data tends to get ignored because it’s so hard to consume. Could transforming it into an easier to digest format make it more popular? The NOAA weather data or WordNet is a good example of this class of data. Dolt adds a ton of value to these datasets. You get SQL right out of the box or on the web. Still, as with CSV and JSON distributed datasets, these datasets don’t seem to drive much Dolt interest. People seem to want to go directly to the data source. This may change as Dolt grows its brand and awareness.
Now, we’re getting onto the part of the curve where Dolt is starting to do something novel. Dolt starts to be the only place to get the data it is serving. “Scraping” is the process of extracting data from websites. For our purposes, we’ll also include scarping APIs, which is a little easier. Some examples of datasets obtained by scraping are the COVID-19 case details dataset and the NBA player statistics dataset. We have more scraped datasets in the pipeline. Stay tuned. The cool thing about scraped datasets is that repeated scraping allows for a pretty rich version history. Did updating to the latest data break something? Just roll back to the previous commit and use the diff to debug. Want to present an analysis of how the data changes over time? The history is all there in the Dolt repository. Dolt’s Linux potentially is a really popular scraped dataset.
Transforms take a dataset distributed in another form and perform some logic on it to produce a novel dataset. A good example is Wikipedia n-grams. We have taken a Wikipedia dump and performed a few different types of n-gram extractions on it. We think there is a lot of interesting datasets to be built from Wikipedia this way. Joining two datasets is another example of a cool transform. We joined the ImageNet and Google Open Images label space.
Finally, we get to novel datasets. These are datasets where human curation is involved. These datasets cannot be gathered purely programmatically. We haven’t ventured into this space much mostly because our tools don’t support some of the things we think would make building a novel dataset on Dolt and DoltHub easy. We need Forks for distributed collaboration, edit on DoltHub, and improved edit integrations with spreadsheet tools. Once we have these tools, we think Dolt and DoltHub could produce truly novel datasets that could not be built any other way, much like open source produces software.
What’s Next?#
We hope that we gave you some perspective on our data journey. Hopefully, Dolt’s Linux is out there. If you have any data you would like in Dolt, please let us know. Or, if you just think Dolt and DoltHub are useful tools, that’s ok too. Download Dolt and start versioning your databases.