
Background#
Dolt is Git for data. It is a relational database that implements a storage layout similar to a commit graph, allowing users to clone, branch, and merge structured data. We believe the ability to clone and pull a remote dataset, and instantly have a functioning relational database with a full history, make it the best data distribution solution on the internet.
Speaking to users and potential users, we learned that while many recognized how powerful the distribution model is, they needed Dolt to work with their existing relational database infrastructure. In a recent blogpost we provided a solution for MySQL databases, announcing a release of Doltpy, Dolt’s Python API, that provides simple Python functionality for syncing between Dolt and MySQL. This post is to announce that we have extended that functionality to Postgres, and give a bit of background on why we chose MySQL, some of the differences between MySQL and Postgres from a syncing standpoint.
Why We Chose MySQL#
When we made the decision to offer a SQL implementation for Dolt, we had a storage engine for structured data, and a command line interface. The command line interface closely modeled Git, and the storage engine created a similarly Git-like commit graph for data stored in tables. The command line interface providing semantics for updating the underlying tables and managing changes. Our goal was to offer a relational interface for interacting with that data, both the raw data itself, and the version control data stored in the commit graph. For example, see documentation on Dolt system tables that allow users to query the history of values a cell has taken over time, as well as other metadata from the commit graph. Our vision is for a full superset of MySQL that surfaces all version control functionality in SQL. We are moving rapidly towards that goal.
We made the decision to build on top of an existing dialect, and the dialect we chose is MySQL. The primary motivation for doing so is that it’s by far the most widely adopted free-to-use relational database. Postgres has a strong following, and for good reason, but it does not have nearly as wide an adoption net. We figured that given how similar most SQL dialects, we could write “glue code”, such as the code this blog post is announcing, to make it straight forward for our users to make Dolt work with their chosen relational database.
Our vision is to implement a full superset of MySQL, which includes Dolt specific features, such as system tables containing data from the commit graph. You can read more about Dolt’s system tables, which are already released. Let’s drill into the differences specifically between our chosen dialect, MySQL, and the target of the sync code this blogpost is about, Postgres.
ANSI SQL#
SQL databases are implicitly assumed to to implement the SQL Standard, which is in fact an ISO standard (see here for the latest version). In reality each implementation implements a dialect. For example, Postgres supports many native data types that MySQL does not, a summary of which can be found here. For example, Postgres natively supports some more esoteric types of geospatial data that MySQL does not.
Most of the basic language features across Postgres and MySQL are the same, though even some simple statements are somewhat different there are subtle differences even in basic functionality. For example, consider the example of limiting the result set to a certain count, first MySQL:
SELECT TOP n columns
FROM tablename
ORDER BY key ASCAnd Postgres:
SELECT columns
FROM tablename
ORDER BY key ASC
LIMIT nWhile MySQL also supports the LIMIT keyword, Postgres does not support TOP n
syntax. The underlying point is that to effectively sync between servers that
offer these similar-but-different SQL dialects we had to write some “glue code”
that abstracted away the underlying differences.
Postgres Support#
With regard to syncing to Postgres, these differences in SQL implementation
pertain to how Postgres stores metadata, and the syntax for updating values on
duplicate primary keys. MySQL supports statements such as SHOW TABLES and
DESCRIBE my_table, which make it easy to retrieve a tabular data structure
containing all pertinent information about what tables exist, which columns they
have, and whether those columns are primary keys. Postgres requires diving into
the information schema and putting together some slightly more complex queries
for achieving the same result. Doltpy wraps all this up so you can focus on
getting value from syncing data to and from Dolt.
A good example of the “similar but different” nature of SQL implementations is
the syntax for updating. First MySQL DUPLICATE KEY syntax (not yet supported
in Dolt):
INSERT INTO my_table (col1, col2, ...)
VALUES (val1, val2, ...)
ON DUPLICATE KEY UPDATE
col1 = VALUES(col1),
col2 = VALUES(col2), ...;
Which is identical to the Postgres code up until you have to deal with updating a duplicate primary key. Here we see subtly different syntax for updating Postgres duplicate primary keys:
INSERT INTO my_table (col1, col2, ...)
VALUES (val1, val2, ...)
ON CONFLICT (pk1, pk2, ...) DO UPDATE SET
col1 = excluded.col1,
col2 = excluded.col2,
...;We used much of the same code for both MySQL and Postgres, but allowed for certain behaviors to be specified by implementation specific code where a different SQL syntax or metadata data access pattern was required.
Let’s move onto putting the sync code to use on real DoltHub data!
Example#
Dolt to Postgres#
Suppose that you or your organization uses Postgres for your internal data, but you would like to source some useful data that is distributed in the Dolt format, perhaps via DoltHub. An example might be the IP-to-country mapping dataset that we maintain. Actually acquiring the data is as easy as:
$ dolt clone dolthub/ip-to-countryUpdating that data is also trivial:
$ cd path/to/ip-to-country && dolt pullOur Python API provides tooling for scripting all of these DoltHub interactions.
You can read about about acquiring data using Python here.
Let’s bring this together in Python, and assume we want to sync the
IPv4ToCountry
table into our production database. First we create a Postgres table with a
matching schema. It’s easy enough to find the schema using
DESCRIBE IPv4ToCountry from the SQL console, and you can also do it in the
DoltHub web interface:
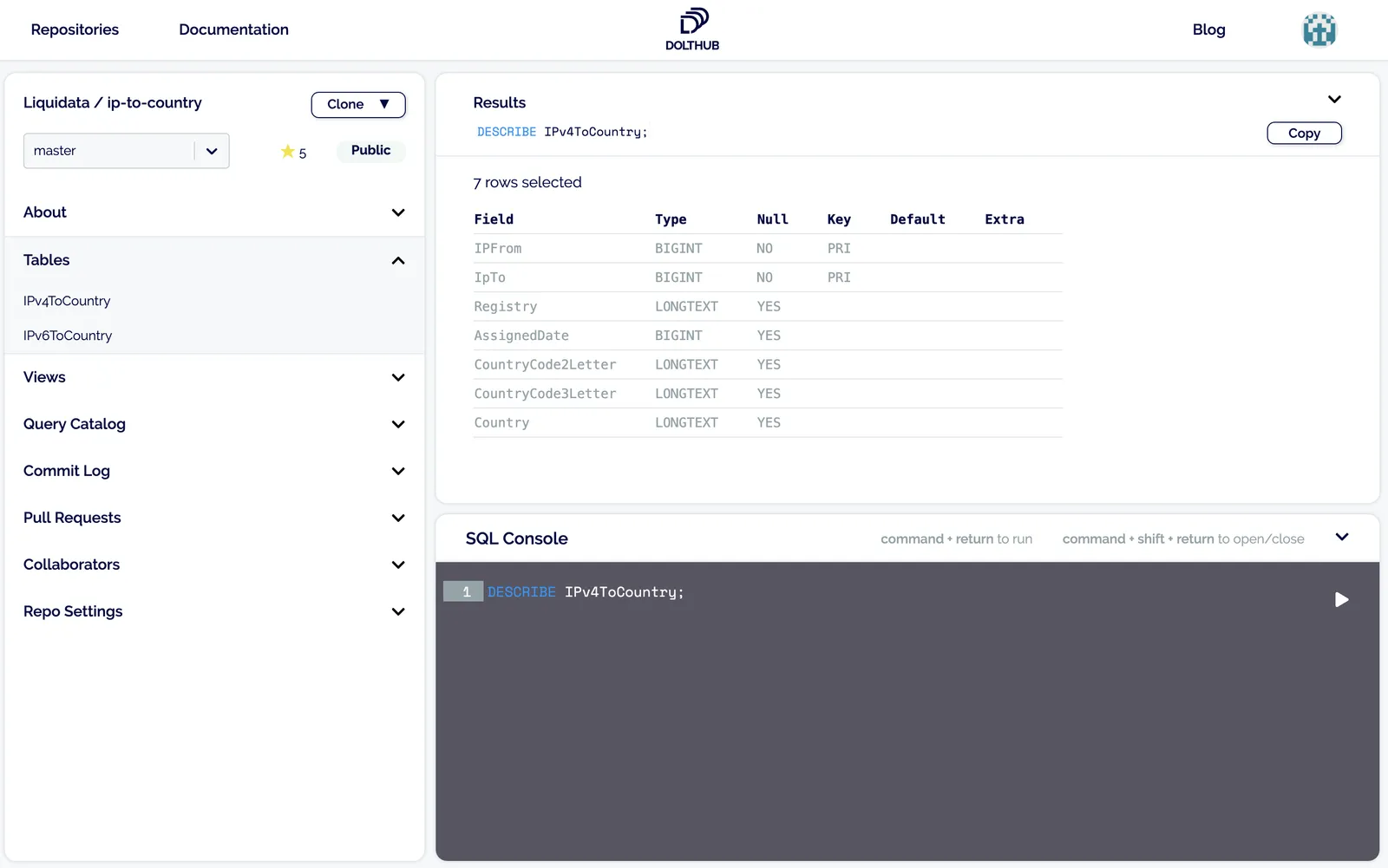
If you’re not sure about Postgres to MySQL type mappings, check this useful documentation out.
Assuming that table has been successfully created in Postgres with the same
name, IPv4ToCountry, we can write relatively simple code to do the sync:
from doltpy.etl.sql_sync import sync_from_dolt
from doltpy.core import clone_repo
import psycopg2
from doltpy.etl.sql_sync import (get_postgres_target_writer,
get_dolt_table_reader,
get_dolt_source_reader)
dolt_repo = clone_repo('dolthub/ip-to-country')
dolt_repo.start_server()
pg_conn = psycopg2.connect("host=db_host dbname=pg_db user=pg_user password=password")
target_writer = get_postgres_target_writer(pg_conn, True)
table_reader = get_dolt_table_reader()
sync_from_dolt(get_dolt_source_reader(dolt_repo, table_reader),
target_writer,
{'IPv4ToCountry': 'IPv4ToCountry'})
dolt_repo.stop_server()This executes a number of steps:
- executes required imports and creates required database connections
- fires up the Dolt MySQL Server instance
- clones the remote repository
- executes the sync, writing the current tip of master from Dolt repo to Postgres table
Note, that for subsequent updates we would use pull instead of clone.
Zooming out a bit, let’s remove the imports and database connections and isolate
the sync code itself:
target_writer = get_postgres_target_writer(mysql_conn, True)
table_reader = get_dolt_table_reader()
sync_from_dolt(get_dolt_source_reader(dolt_repo, table_reader),
target_writer,
{'IPv4ToCountry': 'IPv4ToCountry'})It’s actually relatively simple, and the earlier complexity introduced by differences between Postgres and MySQL is abstracted away in Doltpy. We believe this is a powerful model for data distribution that can negate the need to spend valuable engineering hours acquiring data by instead landing data as functioning SQL database that can be synced to existing relational database infrastructure with minimal effort.
Postgres to Dolt#
Suppose instead that you have data you would like to distribute inside your Postgres database, for example a production dataset that you would like to make available to the data science team for experimentation. It’s easy enough to define a sync that writes it into Dolt. First create a Dolt repository, and create a table matching the schema of your Postgres data. The sync code is very similar:
from doltpy.etl.sql_sync import sync_from_dolt
from doltpy.core import init_new_repo
import psycopg2
from doltpy.etl.sql_sync import (get_dolt_target_writer,
get_postgres_table_reader,
get_postgres_source_reader)
repo = init_new_repo('path/to/repo')
pg_conn = psycopg2.connect("host=db_host dbname=pg_db user=pg_user password=password")
target_writer = get_dolt_target_writer(dolt_repo, True)
sync_to_dolt(get_postgres_source_reader(pg_conn, get_postgres_table_reader()),
target_writer,
{'revenue_estimates': 'revenue_estimates'})
dolt_repo.stop_server()The steps here are as follows:
- executes the required imports and creates the required database connections
- creates a new repo as the target for the sync
- executes the sync, writing the state of the specified Postgres table to the Dolt repo
Again, the code is relatively simple when excluding the database connection setup and import statements:
target_writer = get_dolt_target_writer(dolt_repo, True)
sync_to_dolt(get_postgres_source_reader(pg_conn, get_postgres_table_reader()),
target_writer,
{'revenue_estimates': 'revenue_estimates'})Now share that data by pushing it to a DoltHub repo:
repo.add('my-org/my-remote')
repo.push('origin')Consumers of this data will be able to acquire a functioning SQL database with a single command!
Conclusion#
In this post we announced the extension of Doltpy SQL Sync tooling to work for Postgres. That means you can now sync between Dolt and Postgres, in either direction, with just a few lines of code. We also explained why we chose MySQL as our the dialect for our SQL implementation, and outlined some of the subtle deviations from the ANSI SQL standard that must be accounted for in syncing.
The overarching goal of this work is to supplement Dolt’s powerful data distribution model and version control features with tooling that enables it to work for your organization. We will continue enhancing this functionality, both in scope and depth, over time.