How We Built DoltHub: Front-End Architecture

In the previous article in this series, we took a deep look at the overall system architecture of DoltHub, the online data community powered by the Dolt version-controlled database. In this article, we'll zoom in on the front end and see how the code is organized into packages, linked together, built, and linted.
We have a monorepo
According to Wikipedia:
In revision control systems, a monorepo (syllabic abbreviation of monolithic repository) is a software development strategy where code for many projects is stored in the same repository.
We have a monorepo in two senses:
Firstly, our front-end code is collocated with our back-end code, protobuf definitions, deployment configuration, and a few other things in a single Git repo. This has some advantages:
- Unless it requires a change to Dolt (which has its own public repository), a single pull request can add a feature across the entire stack.
- Protobuf definitions live with their consumers without having to make that a submodule (our
protodirectory already has submodules for the build tools it depends on, which is gross enough). - It's easy to refer across different parts of the project (for example, to look at protobuf definitions or service layer logic while working on the front end), without the risk of checking out incompatible revisions.
On the other hand, it's a big honkin' repo (cloning it currently transfers 170.58 MiB of data, and according to rsync, it's got something like 150k-170k files in it when checked out and full of node_modules and whatnot), and I often have multiple copies of it checked out at once so I can work on different things. It can get a bit unwieldy.
The second sense in which we have a monorepo is that both our front-end and back-end code are broken into packages which are all hosted in this same repository. We'll be focusing on the front-end ones here.
We use Yarn workspaces to manage our front-end packages. This means that each package is just a regular NPM package with its own package.json. We can add our packages as dependencies in one another's package.json files exactly as with any other package, but they are resolved locally and share a single node_modules, which is deduped as much as possible.
web:
babel.config.js
BlogDockerfile
.dockerignore
DocsDockerfile
DolthubDockerfile
.eslintrc.js
.eslintrc.react.js
.gitignore
GraphQLDockerfile
node_modules
package.json
packages
postcss.config.js
.prettierrc
start-dolthub-dev.sh
tsconfig.json
.vscode
yarn.lock
web/packages:
blog
docs
dolthub
dolthub-api
dolthub-cypress
events-api
fakers
graphql-server
ld-proto
loremer
resource-utils
shared-components
tailwind-config
utils
The listing for our web directory and its packages subdirectory, showing the Yarn workspace structure. You can see that a considerable amount of configuration is also shared across the entire workspace.
Using this setup, we have no need to publish packages or fiddle with private NPM repositories or anything like that—everything is local, fast, and secure by default. We used to use Lerna in addition to Yarn workspaces but realized it bought us nothing if we weren't making public releases of our packages (and we're not).
The major downside to all of this is that it required a bit of research and configuration, but now that it's set up, this part of things has been more or less headache-free. In the past, we've run into the dreaded multiple versions of React error trying to use React in a monorepo but on the latest iteration of the architecture we've evaded that so far.
We use TypeScript for everything
We use TypeScript for all of our front-end code and can't imagine going back to untyped JavaScript. Almost all of our front-end packages are written in it. One of the two exceptions is our package of generated protobuf clients and it contains .d.ts files so it can be used with TypeScript. The other is our package of Cypress end-to-end tests.
We have a base tsconfig.json that some of the individual packages extend. Harmonizing and factoring this further is on the to-do list but there are all kinds of packages in here. We have:
- Two Gatsby apps (this blog and our docs website)
- One Next.js application (DoltHub)
- One package of React components and styles shared by the Gatsby and Next apps (
shared-components) - One NestJS application (
graphql-server) - Two packages providing higher-level interfaces to the generated protobuf clients and types (
dolthub-api,events-api) - A custom lorem ipsum generator (
loremer) - Two utilities packages: one general-purpose (
utils), and one for working with DoltHub API resources (resource-utils) - A set of fake data generators for tests and prototyping (
fakers) - And finally, a package for our shared Tailwind CSS configuration (
tailwind-config)
Given this diversity, it's unlikely that we'll ever get to a single base tsconfig.json that all of these projects extend from, but we do intend to move in that direction.
The upsides of TypeScript are numerous. The typechecking is valuable on its own, but at least as importantly, it allows a raft of tooling improvements: excellent editor autocompletion, automatic generation of GraphQL schemas from TypeScript classes, enhanced linting capabilities, etc.
The major downsides are added complexity in setup and in actually using the language. The most obvious point here is that you have to compile it. This introduces a build step which requires tooling and setup, takes time to execute, and increases complexity.
Furthermore, the type system can take some getting used to for JavaScript developers used to dynamic typing, and some patterns are difficult to type properly. Higher-order functions are a particular pain point: functional composition chains and higher-order React components are both relatively difficult to use in TypeScript (though the latter has fallen out of fashion in favor of Hooks anyway).
Also, it's possible to write some seriously brain-bending code, especially using tricky generic features like conditional types, type inference, and the like. It's up to the programmer to know that just because you can do something with the type system doesn't mean that you should.
Overall, though, we think it's a solid tradeoff and you would have to threaten us with unspeakable horrors in order to get us to go back to plain old JavaScript (and even then, we wouldn't crack quickly).
We set up TypeScript project references
Since all our front-end code is in TypeScript, which needs to be compiled, and is separated into many packages/projects, we need a way to specify build dependencies and order.
For example, dolthub depends on dolthub-api, events-api, fakers, graphql-server, resource-utils, shared-components, tailwind-config, and utils (wow). If anything changes in the typings of any of those projects, DoltHub needs to be typechecked again. On the other hand, if we change an implementation detail that doesn't change the types, DoltHub doesn't need to be typechecked again.
Before project references, this was a real pain. If you changed a package, you needed to re-compile it and also re-check any package depending on it, with no automatic detection of whether a change actually changed the types. If your packages needed to be built in a particular order, you were on your own as far as enforcing it. Furthermore, while tsc has had a watch mode since TypeScript's first release, before project references it wouldn't see changes in dependencies.
Previous possible solutions included Makefiles (which can do damn near anything, but ick), package.json scripts (less powerful but more familiar to web devs, but also ick), build runners like Gulp (what is this, 2015?), and other more bespoke solutions. These can solve the build order automation problem easily but detecting whether an implementation change changed the type signatures is harder, and these solutions would still be running tsc multiple times under the hood, with all the startup overhead that incurs.
Project references are designed to solve these woes and more. Setting them up is pretty simple. For example, here's DoltHub's tsconfig.json in its entirety. You can see its dependencies listed as the references key:
{
"extends": "../../tsconfig.json",
"include": ["**/*.ts", "**/*.tsx"],
"references": [
{
"path": "../dolthub-api"
},
{
"path": "../events-api"
},
{
"path": "../fakers"
},
{
"path": "../graphql-server"
},
{
"path": "../resource-utils"
},
{
"path": "../shared-components"
},
{
"path": "../tailwind-config"
},
{
"path": "../utils"
}
]
}DoltHub's tsconfig.json showing the project references configuration
The other main change needed is that each of those referenced projects must have "composite": true in its tsconfig.json. This option has some requirements and implications but the compiler is pretty helpful about guiding you towards compliance.
In the end, the payoff is that you can tsc -b (incrementally build) or tsc -w (watch) your project and TypeScript will automatically compile its dependencies in a correct order and only if needed, before building and typechecking the main project only if needed. This reduced our build times by about half on average and got rid of a really gross and unwieldy set of package.json scripts that we used to specify build order.
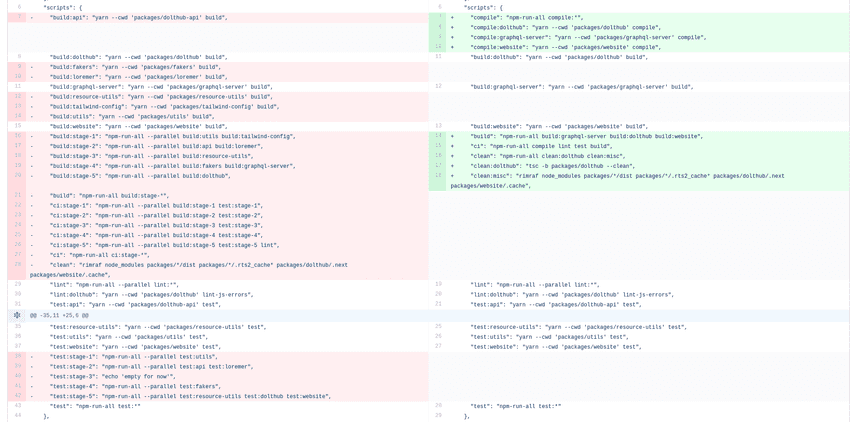
package.json's scripts section before and after project references.
We lint our code with typescript-eslint
In addition to types (which we've covered) and testing (which deserves an article of its own, and will get one), linting is one of the core pillars of our code correctness strategy.
In the past, TSLint was the leading (maybe only) linting solution for TypeScript, and while it took a lot of inspiration from (and shared many similar rules with) ESLint, the leading JavaScript linter, the two tools were not compatible. Worse, TSLint was actually less powerful than ESLint.
This fragmentation was a thorn in the side of TypeScript developers, but relief came in the form of an announcement early in 2019 that Palantir, the backers of TSLint, would be deprecating TSLint in favor of supporting typescript-eslint, which is exactly what it sounds like: an effort to bring TypeScript support directly to ESLint.
We use typescript-eslint and have had mostly great experiences with it so far, though configuration (of the tool itself, not the rules) has been a headache at times. We start by extending Airbnb's TypeScript preset, then add some other rule sets and plugins before our own customizations:
"extends": [
"airbnb-typescript",
"plugin:@typescript-eslint/recommended",
"plugin:react/recommended",
"prettier",
"prettier/react",
"prettier/@typescript-eslint",
"plugin:jest-dom/recommended",
"plugin:testing-library/recommended"
],
"plugins": [
"@typescript-eslint",
"jest",
"jest-dom",
"testing-library",
"react",
"react-hooks"
]The core of our ESLint configuration; beyond this is a bunch of customizations particular to our use cases
Conclusion
We hope this was an interesting and informative look into our front-end architecture. To summarize:
- We have a monorepo, which means our front-end code is divided into many packages which all live in the same Git repository alongside our back-end code
- We use Yarn workspaces, so all packages are resolved locally and we don't have to deal with publishing packages or maintaining a private NPM repository
- We use TypeScript for everything, and setting up project references for fast and sane builds was essential to making that work well
- We use typescript-eslint to lint our code
In the next article in this series, we'll go in depth on our use of GraphQL and discuss some of the challenges and benefits we encountered in switching to it.
In the meantime, if there's anything else you'd like to know, please get in touch with us here—maybe we'll write a blog article on it.
And if you haven't yet, head over to DoltHub, get yourself a copy of Dolt, and let us know what you think. We really value feedback from our users.