DoltHub Redesign

Redesigning DoltHub
Dolt is a database and a data format. DoltHub is a way of hosting and collaborating on Dolt databases. We decided to redesign DoltHub to make it more user friendly. We are excited to announce that we have released the results of that effort. This post describes some of our design goals for the project, and how they relate to our original motivations for building Dolt and DoltHub.
The Motivation for Dolt and DoltHub
DoltHub was founded with the goal of bringing liquidity to the data market, in other words reducing the friction involved in sharing and acquiring data. In practice this is not easy with current data formats: they are, rather perversely, designed neither for human nor computer readability, and offer absolutely no semantics for collaboration sharing. JSON and CSV are examples of such storage formats, FTP and REST APIs are distribution channels they travel across. When taken together these formats lack robust semantics for sharing and collaboration, provide a poor user experience for the data consumer, and require engineering work to automate.
Dolt is an attempt to create a data format that is better for humans and machines. In particular:
- Dolt is a storage format that stores a full version history, which in practice means every committed update is associated with a commit hash and instantly accessible
- Dolt is an ODBC compliant RDBMS that provides a widely adopted query interface, spoken by (a decent number of) humans and (almost all) machines, namely SQL
- Dolt provides a set of protocols that make moving data between machines trivial, much the same way Git eases moving source code between machines
DoltHub is a web application for hosting Dolt repositories. In addition to providing push and pull semantics, familiar to anyone that has used GitHub, DoltHub provides discovery and collaboration tools for allowing users to find and build new datasets.
The Design Goals of DoltHub
These motivations for building DoltHub heavily informed our design decisions. We wanted to ensure that users had the following capabilities front and center:
- discover datasets of interest from an index of data which is either public or to which the user has read permissions
- browse the contents of a dataset in order to decide whether to acquire it, which should happen seamlessly
- easily share and collaboratively build datasets with other DoltHub users
Getting Started
To get the most out of this post, get a copy of Dolt installed, which can be done with a single command:
$ sudo curl -L https://github.com/dolthub/dolt/releases/latest/download/install.sh | sudo bashYou will need to provide your password to drop the binary into /usr/local/bin. Windows users can download an MSI here.
Discovery
The Discover page is an index of repositories that allows users to filter on a preset criteria (owner, organization, etc.), or by keyword search. Whichever the user chooses, they are presented with a list of datasets that meet their search criteria:
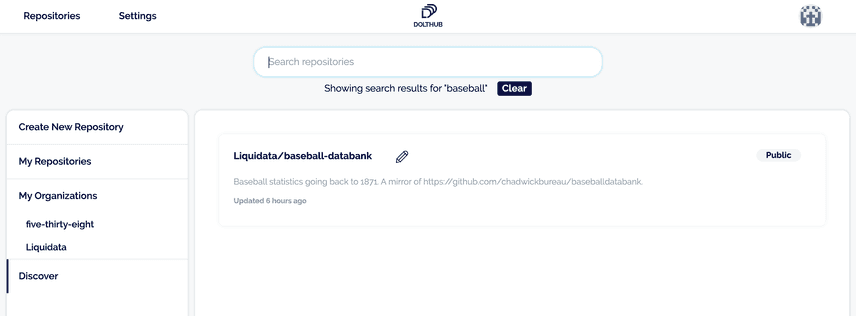 In this case we have surfaced a baseball dataset that we are interested in, the dataset can be found here, and it's public and freely available.
In this case we have surfaced a baseball dataset that we are interested in, the dataset can be found here, and it's public and freely available.
Browsing
Now that we have discovered data that might be of interest, we would like to browse it to get a better idea of what is in that data.
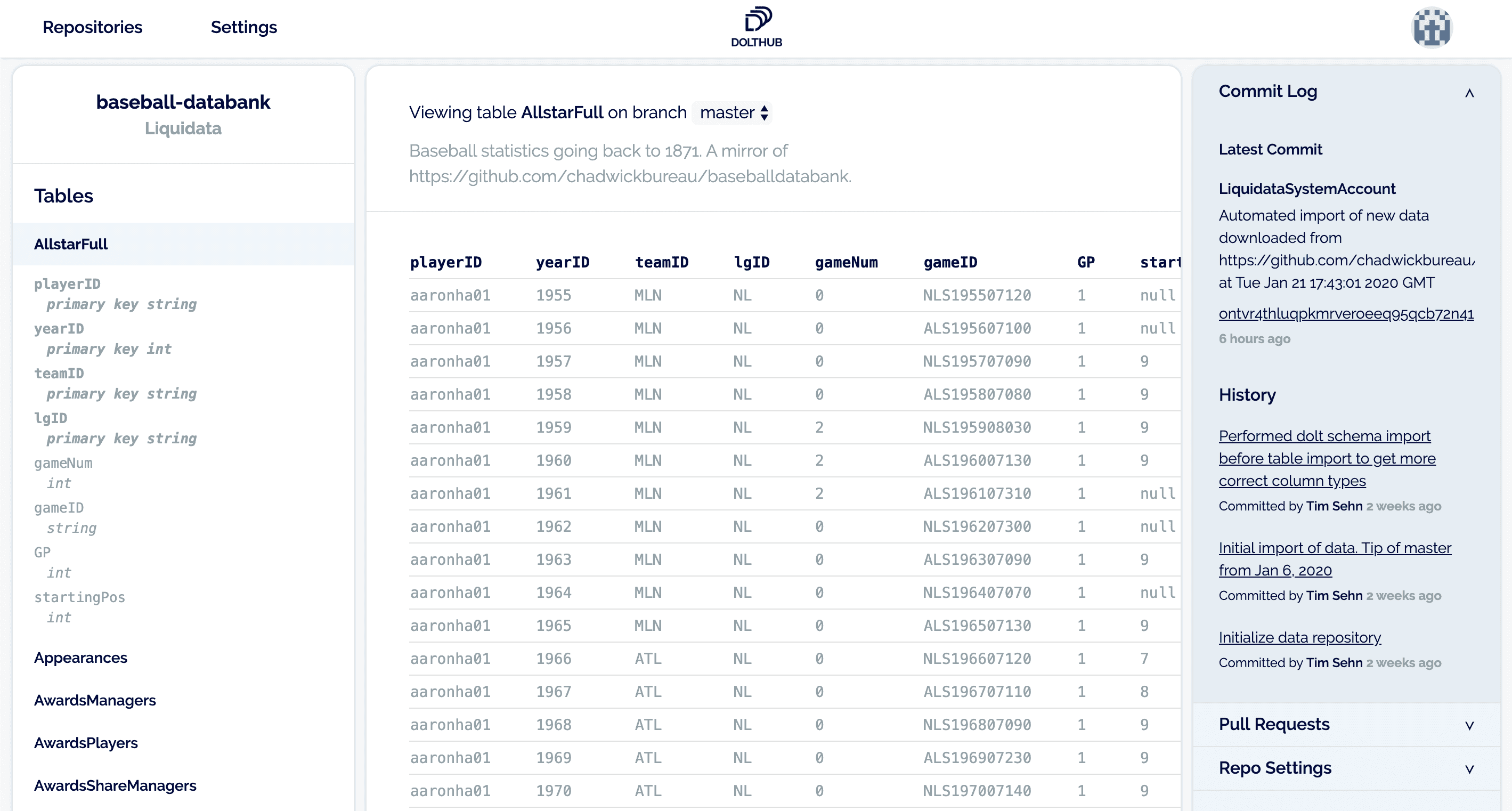 Suppose we find that data interesting, then we can obtain a copy to work with locally (see above for installing Dolt):
Suppose we find that data interesting, then we can obtain a copy to work with locally (see above for installing Dolt):
$ dolt clone dolthub/baseball-databank
$ cd baseball-databank && dolt sql
# Welcome to the DoltSQL shell.
# Statements must be terminated with ';'.
# "exit" or "quit" (or Ctrl-D) to exit.
doltsql> select * from Allstarfull limit 2;
+-----------+--------+--------+------+---------+--------------+----+-------------+
| playerID | yearID | teamID | lgID | gameNum | gameID | GP | startingPos |
+-----------+--------+--------+------+---------+--------------+----+-------------+
| aaronha01 | 1955 | MLN | NL | 0 | NLS195507120 | 1 | <NULL> |
| aaronha01 | 1956 | MLN | NL | 0 | ALS195607100 | 1 | <NULL> |
+-----------+--------+--------+------+---------+--------------+----+-------------+It's that easy to obtain a local copy of a SQL database containing the dataset. If you want to subscribe to updates, just run:
$ dolt pullSince all writes are associated with a commit hash, users can immediately compare the results of analysis against different versions of the data, and trace the source of changes to changes in the data. From a user perspective, we think this represents a radically improved experience for acquiring data.
If you'd prefer a Python interface to your local database, including a Pandas DataFrame based API, check out Doltpy, open source and available on PyPi.
Sharing and Collaborating
We have seen how Dolt can make acquiring and subscribing to data easy, while also encouraging best practices around version control. Suppose now that I have a base dataset that I would like to collaboratively edit, say a set of image labels or some other kind of human scale dataset, and that the base dataset is contained in labels.csv:
oscars-machine $ cat labels.csv
image_id,image_label
1234,cat
oscars-machine $ dolt table import -c --pk image_id labels labels.csv
Rows Processed: 1, Additions: 1, Modifications: 0, Had No Effect: 0
Import completed successfully.
oscars-machine $ dolt sql -q 'select * from labels;'
+----------+-------+
| image_id | label |
+----------+-------+
| 1234 | cat |
+----------+-------+
oscars-machine $ dolt add labels
oscars-machine $ dolt commit -m 'Added a row'
commit 5p7jcprrp21a6oomkhgsvou1hod2b5khThis in turn you can push to DoltHub (or for other remote options, see dolt remote --help), providing you have created an account, and a repo, say oscarbatori/image-labels:
oscars-machine $ dolt remote add origin oscarbatori/image-labels
oscars-machine $ dolt push origin masterNow your collaborator, Alice, can run:
alices-machine $ dolt clone oscarbatori/image-labels && cd image-labels
alices-machine $ dolt sql -q 'select * from labels;'
+----------+-------+
| image_id | label |
+----------+-------+
| 1234 | cat |
+----------+-------+And instantly Alice has a local SQL database to work with. If you add them as collaborators they can make changes, and push those changes back to your repository. Git and GitHub gave us disciplined collaboration for code, Dolt and DoltHub will do the same for data.
In the near future users not comfortable with the command line will be able to do all of this from the browser, and since Dolt is an ODBC compliant SQL database, this can all be done in an automated setting.
Conclusion
We laid out our motivations for building Dolt, and DoltHub. We showed how DoltHub transforms the experience of consuming and sharing data, using a product that implements two familiar interfaces:
- SQL for a friendly type safe query interface
- Git for disciplined sharing and collaboration
We believe Dolt and DoltHub can bring liquidity to the data market by reducing the friction involved in acquiring and distributing data, and we are excited to be bringing these benefits to market