
We’re writing Dolt, the world’s first version-controlled SQL database. Lately we’ve been focusing pretty heavily on AI agent uses cases, because Dolt is the database for agents. And agents have, in turn, been focusing on Dolt. Ever since Dolt was adopted as the agent memory backend for Gas Town, a leading agent orchestrator, Dolt has been under the microscope by a lot of LLMs.
We love the attention, but it has required us to adapt to dealing with a cyborg customer base. Let me explain.
Agents don’t file issues, they file PRs#
In the trad coding world, when a customer finds a bug in Dolt they tend to file an issue in GitHub, or show up in our Discord server to ask us about it. Either way, we’re attuned to this traditional workflow and get them answers very quickly. Oftentimes, we could solve whatever issue they encountered the same day.
But in the agentic coding world, customers don’t behave this way anymore. Instead, they point their slop cannon at our GitHub repo and tell it fix the problem (which the agent itself probably noticed in the first place). Typically this means that our first point of contact with such a customer is not with the customer at all — it’s with their agent, acting on their behalf. And usually they don’t file an issue, they jump straight to submitting a PR with a fix for the problem they found.
Anyone who has worked with agents know they are incredible tools but frequently make mistakes. So the issue that an agent finds and repairs might be:
- Imaginary
- Misdiagnosed
- Badly addressed
Or some combination of all three. But that’s fine, in an open source project you get all sorts of contributions and it’s your job to make sense of them and get value out of them. Customers don’t understand the project the way the owners do, and the same thing is true of their agents.
So slop-cannon PRs themselves are not a problem per se. The problem was they were sometimes actually critical bug reports masquerading as PRs. In the past month we had two of these come in, both addressing real, serious issues in the product resulting from edge cases in recent encoding changes. But because they were filed as PRs, rather than issues, we didn’t notice them until several days later, after several additional customers had been impacted and contacted us through more traditional channels.
Our various GitHub repos have pretty messy PR queues, full of half-finished work and automated changes working their way through, sometimes dozens at a time. This is manageable to us internally, but it only works because we’re constantly talking to one another, asking for reviews, prodding the process along. We don’t typically treat PRs from outside the company with real urgency, and we often don’t notice them for a couple days unless someone mentions a particular reviewer by name.
In days gone by this worked fine, since we had very few outside contributions to worry about in the first place and effectively none of them were urgent. But agents broke those assumptions. Now agents file urgent bug reports as badly-implemented PRs with lengthy, partialy hallucinated descriptions. This is the world we now live in, and it was clear that we needed to adapt new techniques to cope with it.
A vibe-coded GitHub dashboard#
Our current process was broken. Agent-filed PRs and issues meant we were getting too many to stay on top of with certainty. What we needed was more visibility into customer-initiated issues and PRs in our various GitHub repos, a one-stop shop to see what needed our attention. I decided to try my hand at vibe coding one.
Here’s the prompt I started with:
We have been having trouble keeping on top of new GitHub issues and pull requests. Please write a script to access our github
repositories via the github API and summarize issues and pull requests in each. The info we are interested in seeing:
* New issues (filed in the last 24 hours)
* New pull requests (filed in last 24 hours)
* Customer issues with no response after 12 hours
* Customer issues where the customer last responded and no one in our org has responded since, for over 3 days
* Stale customer pull requests: PRs filed by someone outside our github org that we haven't commented on yet
* Stale PRs: PRs by anyone that have been open more than one month
We want this information for each of the following repos:
* dolthub/dolt
* dolthub/go-mysql-server
* dolthub/doltgresql
* dolthub/driver
* dolthub/vitess
The script should summarize the metrics above for each of the above repos in an HTML repo, then send an email with this info to
zach@dolthub.com. The script should have a command line option to print this info to STDOUT instead of emailing it.
You will need an API token for the github API requests. Here is one you can use: <redacted>
I recommend using perl and shelling out to `curl` to access the github API.After a few rounds of back and forth, I had a tool that I was happy with. It looks like this:
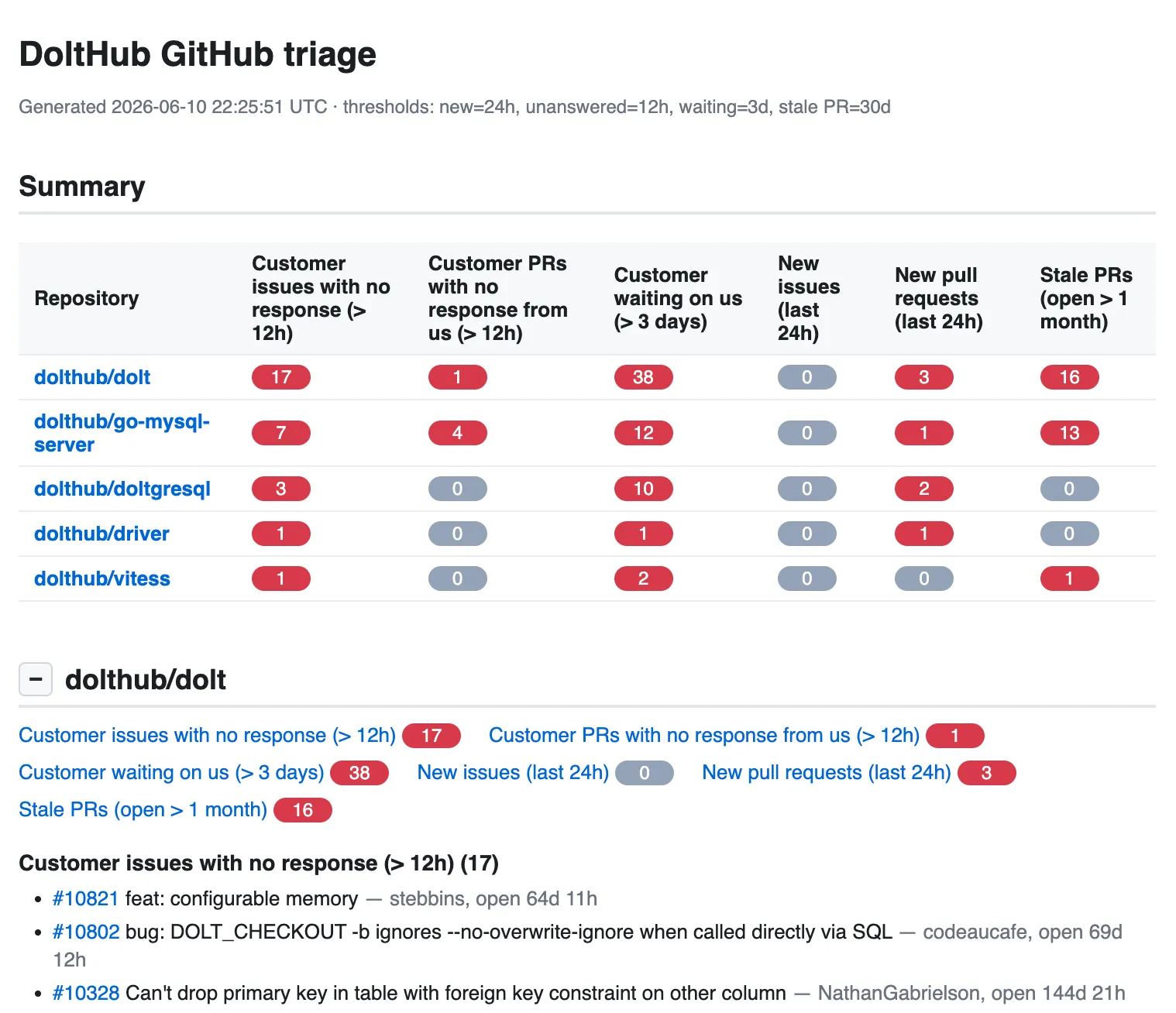
Great. But to be truly useful, I neeed to productionize it, so multiple teammates could have it open in a tab and refresh it whenever they were curious what needed attention.
I just want to host 42 KB#
I’m old, which means that I remember when software deployment was a simple matter. If you wanted to host a single static HTML page that gets generated every hour, you would:
- Provision a server
- ssh into it
- Install apache on it
- Write a cronjob that invoked the script every hour
- Maybe set up a CNAME if you were feeling generous
That’s it, there’s your new dashboard. Give the URL to your teammates to monitor.
But, as with agents, the world has moved on and left greybeards behind. Things are complicated now: there’s AWS, there’s terraform, something called Kubernetes (it sounds fake but they’re telling me it’s real). It’s a lot to take in. When I asked our local infra wizard how to host my 42 KB page generated once an hour, this is what he said.
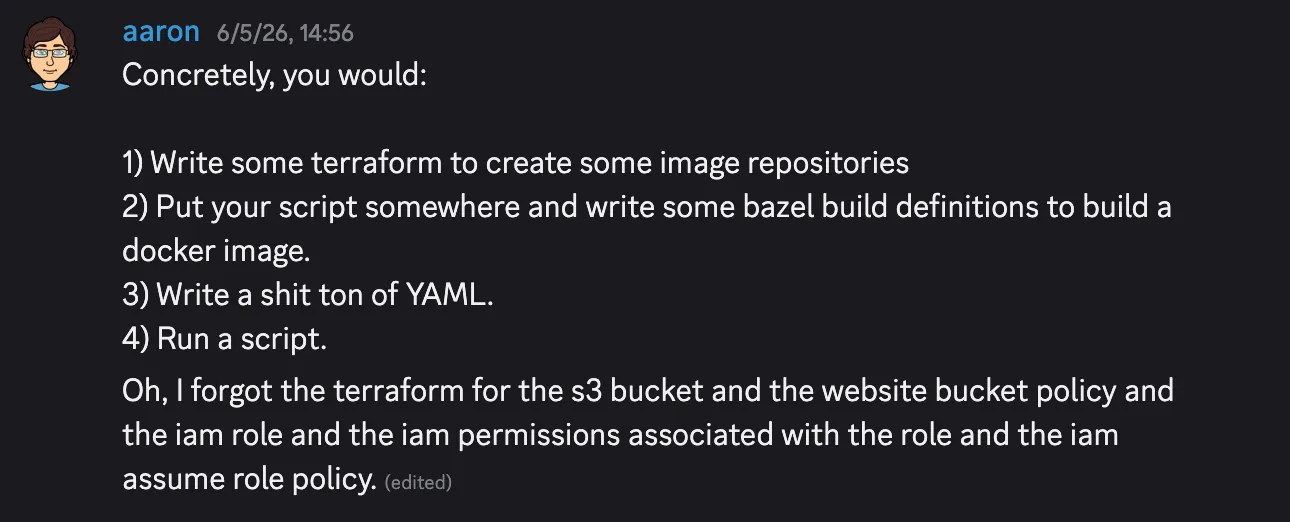
Where have I see this before? Oh that’s right.
Fortunately, one of agents’ absolute greatest strengths is mucking through giant configuration files and adding things to them. They’re great at it. I decided to give it a shot.
We have a script that produces a static HTML page. We want to run it as an AWS lambda with an
eventbridge trigger once an hour, then upload the result to S3 for viewing. Please instantiate
this architecture, using the following information:
* We use terraform to instantiate all of our cloud resources. The YAML configuration files for
this process list in the `terraform` directory. You will need to add new ones as well as edit
existing ones.
* We want a new S3 bucket to host this content. Call it `customer-dashboards`.
* We will need website bucket policy and an iam role and the iam permissions associated with the
role and the iam assume role policy. This can all be accomplished with YAML in the `terraform`
directory.
* We don't care about CloudFront or HTTPS at this point. All the data we care to host is
public. We can revisit this decision later if we change our minds.
* The script to run is `web/github_triage.pl`, and it should be run as a lambda function once an
hour.
* The script should have a dedicated image repository, also defined in `terraform`. You will need
to write a bazel build script to build a Docker image for the script as part of this work.
That should be enough to get started. I haven't provided all the details, but you should examine the
structure and content of enough of the YAML files in `terraform` to make reasonable assumptions about
which accounts, roles, etc. to use in this work. Please get started, and thank you for your hard work
and dedication to this task.I didn’t give the robot all the details because I didn’t want to take the time to understand them myself. I just wanted to host 42 KB.
Lo and behold, a few thousand tokens later, I had a working set of changes to our terraform files, things that look like this:
@@ -0,0 +1,16 @@
+terraform {
+ required_providers {
+ aws = {
+ source = "hashicorp/aws"
+ version = "~> 6.33.0"
+ }
+ }
+ backend "s3" {
+ bucket = "liquidata-terraform"
+ key = "deployments/aws-liquidata-corp/github-triage"
+ region = "us-east-1"
+ shared_config_files = ["../../ld_aws_config"]
+ shared_credentials_files = ["/dev/null"]
+ profile = "corp_admin"
+ }
+}A couple small rounds of back and forth with more knowledgable human beings with the permission to run terraform commands and I was in business.
Conclusion and takeaways#
There are a couple obvious takeaways from this little parable.
First, customer support in an agentic world comes with new challenges. You can try to set up policy and culture to prevent people using agents to submit slop PRs and issues, but that’s probably counterproductive. It won’t work, and even if you can make it work you’re going to alienate a large chunk of your potential customers by imposing it. The world has changed, and open source maintainers need to change to keep up. A majority of your issues and PRs are going to be agent-authored in the near future, and you had better be ready with tools and processes to support that reality.
Second, agents change our bar for what’s possible and what’s worth doing. In a pre-agentic world, there’s only a small chance I would have taken the effort to write this dashboard for my own use, let alone productionize it for the rest of the team to look at. Authoring and deploying this tool with the help of agents took me less than a full work day overall. Without agents, I would have spent a couple days just getting the API calls to work and the HTML output to look reasonable, then spun my wheels who knows how long learning our deployment infrastructure well enough to get it into production. But probably, I simply wouldn’t have bothered. We’re all busy with a giant backlog of things we would like to do, and this wouldn’t have made the cut unless my boss told me to prioritize it. The truly beautiful thing about agents is that they let us all execute many more of our ideas than we could ever justify before. We all have to adjust our ambitions accordingly.
Does this match your own experience with agentic coding? Have questions about customer support in the age of agents? Or maybe you want to learn more about Dolt, the database for agents? Visit us on the DoltHub Discord, where our engineering team hangs out all day to let us know. Hope to see you there.