
Dolt, the world’s first SQL database with Git-like versioning, uses a write-ahead journal to ensure data integrity and durability. However, in rare cases, the journal itself can become corrupted or experience data loss. In this post, we will explore how Dolt detects and repairs journal data loss to maintain the integrity of your data.
Computers Hate Data#
Before jumping into the specifics of Dolt’s journal, I’d like to highlight how fragile computer data can be. There is a great usenix talk by Chris Sinjakli of PlanetScale which highlights how data loss can occur in unexpected ways. For example, many disk drives, including SSDs, can cache writes in volatile memory for performance reasons. If there is a power loss, these writes can be lost even though the OS thinks they are all done. Operating systems handle the fsync in subtly different ways, and PostgreSQL has had trials with it that are well documented.
Durability, the assurance that once a write is acknowledged it will not be lost, is a complex topic. Dolt uses a write-ahead journal to help ensure durability, but even the journal can be subject to data loss in some situations.
Understanding the Journal#
There is a file in every Dolt database with this name:
$ find .dolt -name "*vvvvv*"
.dolt/noms/vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvThis file is the journal. This file contains two types of entries:
- Chunk Records: These entries contain the actual database data - your tables, schemas, etc. Chunks are the fundamental unit of storage in Dolt’s data.
- Root Records: These entries mark points in the journal where the database state is committed to disk. When a root entry is successfully written to the journal, it indicates that all prior chunk entries are now durable.
Every record is a binary sequence of bytes which starts with a 4 byte length prefix, followed by the data, and ends with a 4 byte checksum. The checksum is a CRC32 checksum of the data bytes, which allows Dolt to look at an arbitrary slice of bytes and determine if it is a valid record or not.
When Dolt starts up, it reads the journal file from the beginning, gathering chunk entries to reconstruct the database state. It keeps track of the last successfully written root entry to indicate the state of the database.
In picture form, a healthy journal looks like this:
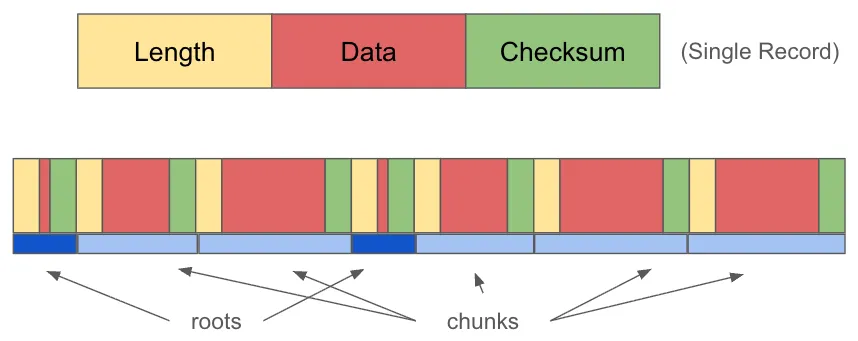
During the course of a transaction, Dolt writes chunk entries to the journal lazily as a performance optimization. The root entry is written at the end of the transaction to mark the transaction commit point. All chunk entries before the root entry are considered durable because the fsync system call to write the root completes before we acknowledge the transaction to the user.
Note that the chunk records which come after the last root record exist because Dolt was writing them lazily, but they may have never been part of a committed transaction. While they exist in the datastore of the database, they will get cleaned up by background garbage collection later if they never become part of a committed transaction.
Detecting Journal Data Loss#
Until release 1.78.6, Dolt was fairly aggressive in throwing out data it didn’t understand in the journal. There were two main scenarios where this would happen:
- NULL Bytes: Due to a pattern established long ago, we initialized new journal files with null bytes. When reading the journal, if we encountered 4 null bytes where we expected a length prefix, we would stop reading and consider the journal complete.
- Malformed Records: If we encountered a record where the length prefix or checksum didn’t make sense, we would stop reading and consider the journal complete. This could happen if a write was incomplete in normal operation.
Both of these scenarios were considered normal, and Dolt would simply stop reading the journal at that point. However, this was too permissive. We had a user present a journal file to us which looked like this:

There were valid records at the beginning of the journal, but then there were a series of null bytes in the middle of the journal. After the null bytes, there were more valid records. In previous versions of Dolt, the journal reader stopped at the null bytes, and the valid records after the null bytes would be ignored.
How a journal file ends up in this state is not entirely clear. We are currently working on a test harness to abruptly power down hosts to reproduce the behavior. It could be due to disk corruption, a buggy filesystem, or some other unexpected failure mode. Check out that usenix talk referenced above for all the horrors of writing files to disk. Regardless of the cause, we needed a better way to handle this situation. The existence of valid records after the point of unparsable records indicates that data loss has occurred, and we need to handle it more carefully.
With the 1.78.6 release, we made the following changes:
- Search for Valid Records: Instead of stopping at the first unparsable piece of data in the journal, we now scan forward in the journal to look for the next valid record. Even if we encounter null bytes or an unparsable record, we will continue to the end of the file looking for records which have a valid length prefix and checksum. If a root record is found followed by a second record of any type, we will halt the server startup and report an error.
- Partial Repair: The
fsckcommand has a new option,--revive-journal-with-data-loss, which will attempt to repair a corrupted journal by truncating it at the first sign of trouble. It will save a backup of the original journal file before making any changes. You will be encouraged to create an issue if you should ever need to use this option. - No Null Padding: We no longer initialize new journal files with null bytes. This eliminates the possibility of encountering null bytes in normal operation. It was a performance optimization which is no longer necessary.
- Journal Truncation: When we encounter null bytes or malformed records, we now truncate the journal at that point. This means that any valid records after the point of corruption are discarded, but it prevents us from writing into the middle of the file which is never the desired behavior. This operation is only performed if no data loss was detected (see point 1).
Behind the Curtain#
There is a command we added to investigate such issues in the future. It’s part of a small set of admin commands which are completely undocumented and unsupported. But hey, it’s open source, so you could discover these things for yourself if I didn’t point them out!
/tmp $ dolt admin journal-inspect -c -r /workspace/test_dolt_db/.dolt/noms/vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv
INFO[0000] Read 2978 bytes with sha256 sum: a4a14a1c01e956bde4f9e5f85800385679b3160e5a89011580e505f9e09b2696
INFO[0000] --------------- Beginning Journal Scan ----------------
INFO[0000] Resumed healthy reads at offset 0
INFO[0000] First Root Record Found 9q5ki2f47b28fl8l9jtj0mphapi8h1a8 (40 bytes)
INFO[0000] Chunk Record Found 52qkcc17dcqtblc9aml4so2jrooun338 (102 bytes)
INFO[0000] Chunk Record Found 8tsjiu5fcsvchoo4re8bgftuuogl7ko1 (294 bytes)
[...]Do with this information what you will. Long live open source!
Conclusion#
There are more improvements to be made in this area. Ensuring we never produce a bad journal is important, but detecting that we have a bad journal is equally important. We are actively working on improving our testing and validation processes to ensure we raise the robustness of Dolt in the face of unexpected failures. Having a reliable database is our top priority - there is no faster way to lose user trust than to lose their data.
Interested in getting more under the hood with Dolt? We have a few more admin commands we can share with interested users. Come by our Discord server!