
We’re building Go to build Dolt, the world’s first and only version-controlled SQL database. The database’s query execution engine uses an iterator type to spool rows between different layers of the execution stack, which looks like this:
type RowIter interface {
Next(ctx *Context) (Row, error)
Close() error
}This is a great general-purpose interface that has served us well for years, but of course we sometimes need to add an adapter layer when using libraries that use different approaches to iteration. A few weeks ago I shared a solution I came up with when I needed to adapt a b-tree library to this interface. The issue was that the library wants to iterate all elements in a range scan in a single function call, like this:
func (t *BTree) AscendRange(greaterOrEqual, lessThan Item, iterator ItemIterator)That iterator callback function gets called for every element in range in the tree. But I needed
elements one at a time, once every time Next() is called on my iterator struct. My solution was to
use a channel to bridge this impedance mismatch, which worked pretty well. You can read the
original blog for
details, or just keep reading for a summary.
I hadn’t really considered the performance impact of using channels this way, since the per-item cost of iteration it was unlikely to be a major bottleneck in this part of a codebase. But several commenters pointed out that channels are pretty slow when used for iteration in this way. That got me curious: how much slower are they? And what’s a better option in a case like this?
Luckily a reader was kind enough to provide just such an option, which uses the iter package
introduced in Go 1.23, which we covered when it was
released. Keep reading for
details on that solution, which is in fact better and (spoiler) faster.
Let’s talk about our experimental setup and then look at the different iterators we’ll be benchmarking.
Experimental setup#
We’ll use the same btree package and write several iterators over a tree. We’ll seed the tree and
the ranges we scan in it like this.
const numElements = 10_000
const numRanges = 100
var randomRanges [][2]int
func init() {
randomRanges = make([][2]int, numRanges)
for i := 0; i < numRanges; i++ {
low := rand.IntN(numElements)
high := numElements + rand.IntN(numElements-low)
randomRanges[i] = [2]int{low, high}
}
}
func seedTree() *btree.BTreeG[int] {
var tree = btree.NewG[int](2, func(a, b int) bool {
return a < b
})
for i := 0; i < numElements; i++ {
tree.ReplaceOrInsert(i)
}
return tree
}
type iterator interface {
Next() (int, error)
Close() error
}
func drainIter(i iterator) {
defer i.Close()
for {
_, err := i.Next()
if err == io.EOF {
break
} else if err != nil {
panic(err)
}
}
}So the tree has 10,000 element in it, and we’re going to scan randomly sized ranges of them. We’re
generating these ranges ahead of time in an init block so that random number generation doesn’t
pollute the benchmark measurement.
Now that we have a tree and ranges to scan, we’ll iterate over those ranges like this:
func BenchmarkChannelIter(b *testing.B) {
b.ReportAllocs()
tree := seedTree()
for n := 0; n < b.N; n++ {
// iterate between 1 and 3 ranges
numRanges := 1 + n%3
rangeStartIdx := n % (len(randomRanges) - numRanges)
iter := newChannelIter(tree,
randomRanges[rangeStartIdx:rangeStartIdx+numRanges],
)
drainIter(iter)
}
}On to the measurements.
Original channel solution#
Here’s the original iterator implementation, which uses a goroutine to send values from
btree.AscendRange over a channel to the next invocation of Next().
type leakyChannelIter struct {
tree *btree.BTreeG[int]
ch chan int
ranges [][2]int
i int
}
func newLeakyChannelIter(tree *btree.BTreeG[int], ranges [][2]int) *leakyChannelIter {
return &leakyChannelIter{
tree: tree,
ranges: ranges,
}
}
func (c *leakyChannelIter) Next() (int, error) {
if c.i >= len(c.ranges) {
return 0, io.EOF
}
if c.ch != nil {
val, valReceived := <-c.ch
if !valReceived {
c.ch = nil
c.i++
return c.Next()
}
return val, nil
}
c.ch = make(chan int)
go func() {
defer func() {
close(c.ch)
}()
c.tree.AscendRange(c.ranges[c.i][0], c.ranges[c.i][1], func(item int) bool {
c.ch <- item
return true
})
}()
return c.Next()
}
func (c *leakyChannelIter) Close() error {
return nil
}Why do I call this leakyChannelIter? After our last publication, a fan of the blog pointed out
that this implementation can leak a goroutine and channel if the iterator isn’t fully
drained. Thanks for the bug report! We fix that issue in the next version.
Non-leaky channel solution#
Here’s the bug fix for the goroutine leak.
type channelIter struct {
tree *btree.BTreeG[int]
ch chan int
stopCh chan struct{}
ranges [][2]int
i int
}
func newChannelIter(tree *btree.BTreeG[int], ranges [][2]int) *channelIter {
return &channelIter{
tree: tree,
ranges: ranges,
stopCh: make(chan struct{}),
}
}
func (c *channelIter) Next() (int, error) {
if c.i >= len(c.ranges) {
return 0, io.EOF
}
if c.ch != nil {
val, valReceived := <-c.ch
if !valReceived {
c.ch = nil
c.i++
return c.Next()
}
return val, nil
}
c.ch = make(chan int)
go func() {
defer func() {
close(c.ch)
}()
c.tree.AscendRange(c.ranges[c.i][0], c.ranges[c.i][1], func(item int) bool {
select {
case c.ch <- item:
case <-c.stopCh:
return false
}
return true
})
}()
return c.Next()
}
func (c *channelIter) Close() error {
close(c.stopCh)
return nil
}We stop the leak by stopping iteration in the callback to AscendRange during Close(), triggered
by closing a new stop channel.
select {
case c.ch <- item:
case <-c.stopCh:
return false
}
return trueThis fixes the potential for a goroutine leak but comes at a price, as we’ll see in a second.
A better solution: use iter.Pull#
Another helpful reader commented that we should be using iter.Pull method instead, which is much
faster and easier. And he was right on both counts. Here’s an iterator that uses iter.Pull.
type pullIter struct {
next func() (int, bool)
stop func()
tree *btree.BTreeG[int]
ranges [][2]int
i int
}
func newPullIter(tree *btree.BTreeG[int], ranges [][2]int) *pullIter {
return &pullIter{
tree: tree,
ranges: ranges,
}
}
func (p *pullIter) Next() (int, error) {
if p.i >= len(p.ranges) {
return 0, io.EOF
}
if p.next != nil {
val, valReceived := p.next()
if !valReceived {
p.stop()
p.next = nil
p.stop = nil
p.i++
return p.Next()
}
return val, nil
}
p.next, p.stop = iter.Pull(func(yield func(i int) bool) {
p.tree.AscendRange(p.ranges[p.i][0], p.ranges[p.i][1], yield)
})
return p.Next()
}
func (p *pullIter) Close() error {
if p.stop != nil {
p.stop()
}
return nil
}This is quite a bit cleaner. It avoids starting a new goroutine, so there’s no worry about leaking
one. If a caller doesn’t remember to clean up an iterator with Close() in the case they don’t
fully drain it, the channel-based iterator leaks a goroutine. The iter.Pull based iterator handles
a similar concern by calling stop() in Close(), but based on a reading of the go docs I don’t
think this is actually necessary to avoid a leak. I would need to dig deeper to confirm this though.
Which brings up an interesting topic: why didn’t this solution, which struck many people as obvious, occur immediately to me as well? My blog on the topic of range iterators is currently the #3 Google search result for the term “golang range iterators”, so while I’m not an expert I certainly know more about this than most people. So why the blind spot?
Frankly I didn’t see how it could be possible to accomplish this feat at all without either caching
the values, or spinning up a goroutine. And I was pretty sure nothing in the iter package creates
goroutines for iteration. But as it turns out, this is only mostly true. iter.Pull doesn’t use
goroutines, but it does use a form of coroutine. From the go
source:
// A coro represents extra concurrency without extra parallelism,
// as would be needed for a coroutine implementation.
// The coro does not represent a specific coroutine, only the ability
// to do coroutine-style control transfers.This is the magic that lets iter.Pull transfer control between the current goroutine’s execution
and the yield function: it calls coroswitch and does some fun unsafe.Pointer operations to
jump between two function stacks in the same goroutine.
next = func() (v1 V, ok1 bool) {
race.Write(unsafe.Pointer(&pull.racer)) // detect races
if pull.done {
return
}
if pull.yieldNext {
panic("iter.Pull: next called again before yield")
}
pull.yieldNext = true
race.Release(unsafe.Pointer(&pull.racer))
coroswitch(c)
race.Acquire(unsafe.Pointer(&pull.racer))
// Propagate panics and goexits from seq.
if pull.panicValue != nil {
if pull.panicValue == goexitPanicValue {
// Propagate runtime.Goexit from seq.
runtime.Goexit()
} else {
panic(pull.panicValue)
}
}
return pull.v, pull.ok
}Pretty neat! But coroswitch is only for the go runtime and core libraries, if you try to use them
the linker will refuse to build the binary.
That was a long aside. Let’s look at the benchmarks for these three different implementations.
Results and discussion#
I ran the benchmark 10 times:
% go test ./... -run='.*' -bench=. -count=10 > benchmark.txtThen I used the benchstat tool to crunch the averages for me.
$ benchstat benchmark.txt
goos: linux
goarch: amd64
pkg: github.com/dolthub/dolt/go/scratch-iters
cpu: AMD EPYC 7571
│ benchmark.txt │
│ sec/op │
ChannelIter-16 6.148m ± 3%
LeakyChannelIter-16 4.275m ± 2%
PullIter-16 1.840m ± 0%
geomean 3.643m
│ benchmark.txt │
│ B/op │
ChannelIter-16 8.120Ki ± 5%
LeakyChannelIter-16 5.453Ki ± 2%
PullIter-16 2.739Ki ± 0%
geomean 4.950Ki
│ benchmark.txt │
│ allocs/op │
ChannelIter-16 279.0 ± 5%
LeakyChannelIter-16 187.5 ± 2%
PullIter-16 94.00 ± 0%
geomean 170.1So the iter.Pull method of iteration is about 2x faster than a potentially leaky channel-based
approach and over 3x faster than one that doesn’t leak. It also allocates dramatically less memory.
But interestingly, while the speed advantage remains constant with smaller collections, the memory advantage actually reverses. Here’s 1,000 elements:
$ benchstat benchmark-1000.txt
goos: linux
goarch: amd64
pkg: github.com/dolthub/dolt/go/scratch-iters
cpu: AMD EPYC 7571
│ benchmark-1000.txt │
│ sec/op │
ChannelIter-16 619.6µ ± 2%
LeakyChannelIter-16 435.0µ ± 2%
PullIter-16 187.6µ ± 0%
geomean 369.8µ
│ benchmark-1000.txt │
│ B/op │
ChannelIter-16 511.0 ± 0%
LeakyChannelIter-16 358.0 ± 0%
PullIter-16 536.0 ± 0%
geomean 461.1
│ benchmark-1000.txt │
│ allocs/op │
ChannelIter-16 8.000 ± 0%
LeakyChannelIter-16 6.000 ± 0%
PullIter-16 15.00 ± 0%
geomean 8.963And here’s 100:
$ benchstat benchmark-100.txt
goos: linux
goarch: amd64
pkg: github.com/dolthub/dolt/go/scratch-iters
cpu: AMD EPYC 7571
│ benchmark-100.txt │
│ sec/op │
ChannelIter-16 78.97µ ± 2%
LeakyChannelIter-16 58.35µ ± 2%
PullIter-16 27.29µ ± 0%
geomean 50.10µ
│ benchmark-100.txt │
│ B/op │
ChannelIter-16 433.0 ± 0%
LeakyChannelIter-16 304.0 ± 0%
PullIter-16 512.0 ± 0%
geomean 407.0
│ benchmark-100.txt │
│ allocs/op │
ChannelIter-16 6.000 ± 0%
LeakyChannelIter-16 5.000 ± 0%
PullIter-16 15.00 ± 0%
geomean 7.663Since it’s a fair bet that most readers want an iterator implementation that can’t leak goroutines when used correctly (even if it’s slower), we’ll disregard that implementation and only compare the two safe ones. Here it is graphically, note the log scale.
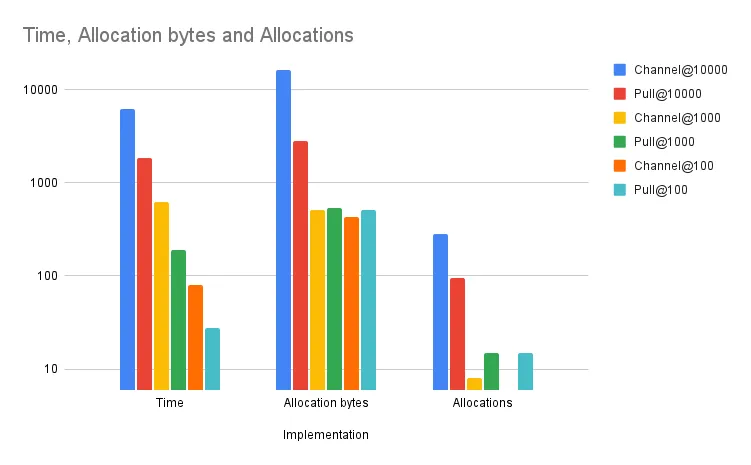
The small advantage in allocations for channel-based iteration at smaller iteration sizes probably isn’t worth the massive difference in speed for most applications. It’s hard to say definitively until you profile on your workload, but it’s clear that for most developers, using channels is a worse choice.
You can find the full code for the benchmark here if you want to play with it yourself.
Conclusion#
The haters are right: using channels for iteration is slow. I knew this was likely to be the case, but I was surprised by how dramatic the difference is. Whether this is a deal breaker for your use case is pretty subjective, but in general I would consider it a pattern to avoid where possible.
Have a question about iteration in Go, or about Dolt? Come by our Discord and talk to our engineering team. We hope to see you there.