
Dolt is a SQL database with Git versioning semantics, including branch, merge, revert, and row level diffs. A SQL database that insures against data and collaboration mistakes is novel, but relational databases themselves are old. We recently rewrote our storage format to bring Dolt’s performance closer to MySQL’s, a 30 year old database. We still trail MySQL by a 3-4x performance gap, but we are getting closer.
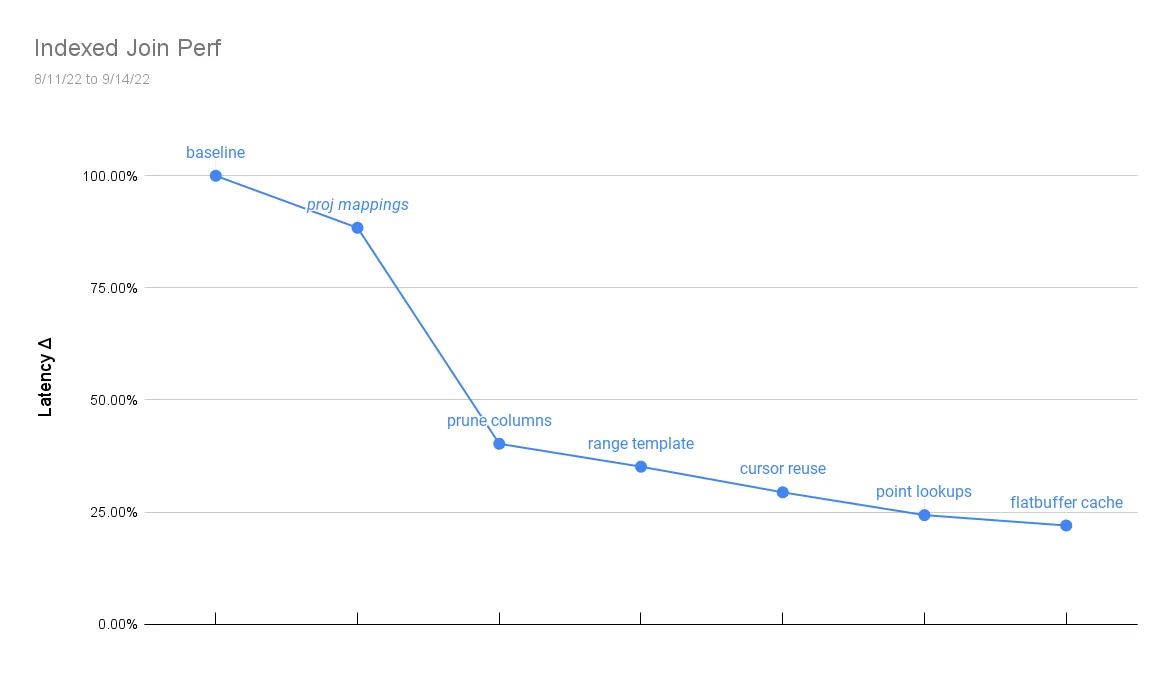
Today we will look at indexed join performance improvements over the last month. We will focus on a single query, an indexed join, that experienced a 4x (78%) total speedup since August.
Many of the optimizations apply more broadly to index access, range building, and projections, but we will consider changes from the lens of joins and take beginner steps through understanding how indexed joins can be faster.
What is an indexed join#
A logical join between a and b multiplies two tables, outputting rows
for every row pairing between a and b that satisfy some join filter:
select a.id from a join b on a.id = b.id
Traditionally this looks like a tablescan of the inner table, followed
by a tablescan of the outer table for every row of the inner table. If
table a has N rows, and table b is M rows, we will read table a once, b N times,
and output up to NxM rows.
Indexed joins are a different strategy for executing the same logical
join. An indexed join will tablescan the inner a, but the second step
runs an index lookup into the outer table b using the join condition.
We can only use this pattern for certain join conditions, which is one
of the reasons why it is important to carefully design indexes and table
relationships. Reading 1 row rather than M over a multitable join is the
difference between a 100ms result and a 10 minute result.
Individual optimizations#
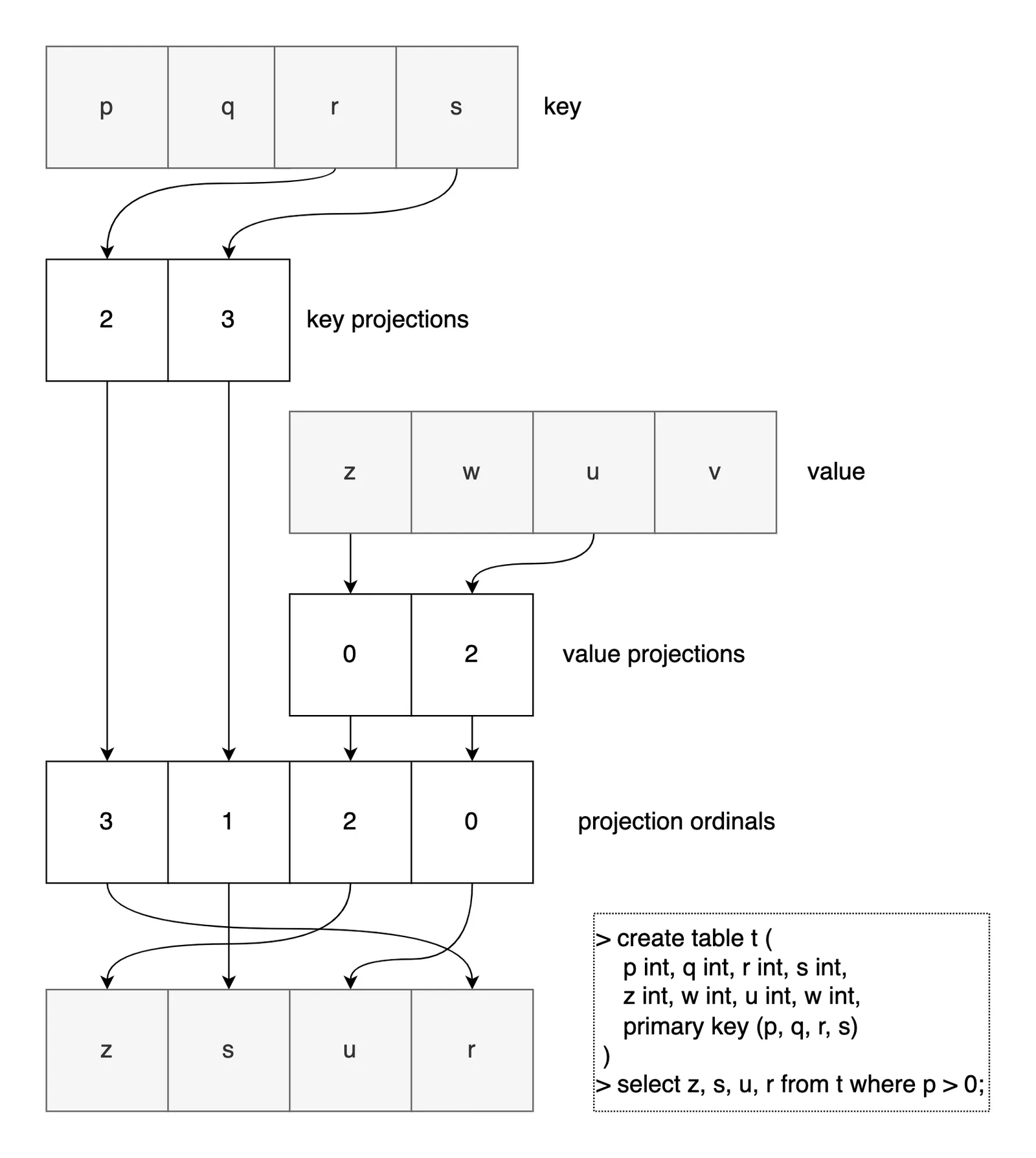
Projection mappings#
Reading rows from disk into memory can be a surprisingly complicated process. Rows are stored as key/value pairs. Different index definitions will have different key and value tuples. Some indexes only cover a fraction of the table’s schema, relying on references to the primary index for backfilling accessory columns.
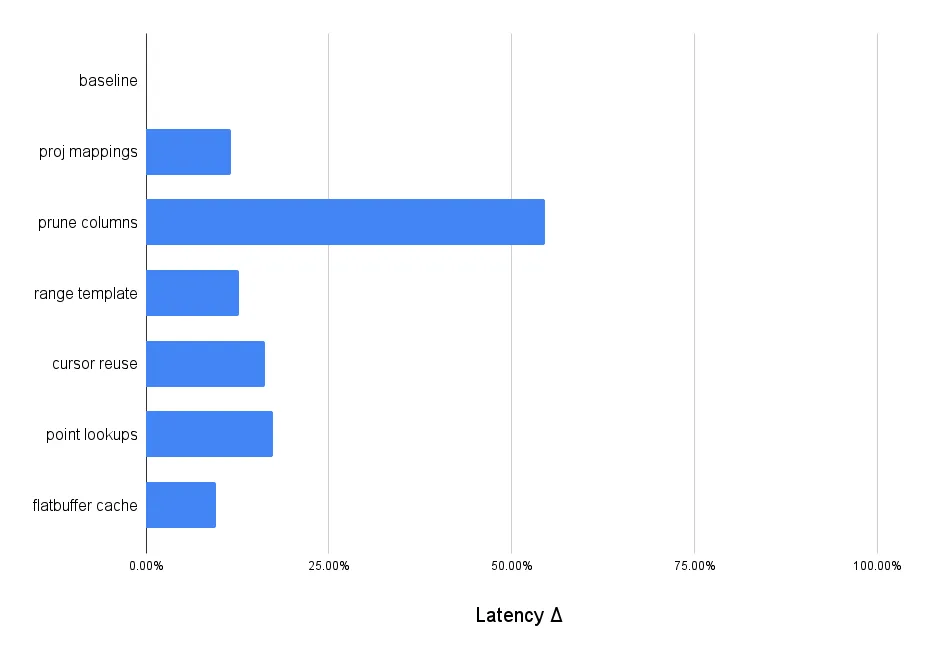
We originally used hash maps to coordinate between key/value tuples on disk and rows in memory. The maps were easy to read, but expensive to build and use. We streamlined the mappings into a lighter array form and cached uses between lookups. The result, summarized below, yielded a modest 12% improvement to the index join benchmark that is shared by all reads.
Prune columns#
A maybe obvious observation is that we rarely read every table in every query. Similar but less obvious is that we rarely use every column in the tables we do read. A naive join implementation reads all rows for every table joined, and at the end projects only the selected columns.
tmp.P9vwSC8R> explain select a.id from sbtest1 a join sbtest1 b on a.id = b.id;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| plan |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Project |
| ├─ columns: [a.id] |
| └─ IndexedJoin(a.id = b.id) |
| ├─ Exchange |
| │ └─ TableAlias(a) |
| │ └─ Table(sbtest1) |
| │ └─ columns: [id tiny_int_col unsigned_tiny_int_col small_int_col unsigned_small_int_col medium_int_col unsigned_medium_int_col int_col unsigned_int_col big_int_col unsigned_big_int_col decimal_col float_col double_col bit_col char_col var_char_col enum_col set_col date_col time_col datetime_col timestamp_col year_col] |
| └─ TableAlias(b) |
| └─ IndexedTableAccess(sbtest1) |
| ├─ index: [sbtest1.id] |
| └─ columns: [id tiny_int_col unsigned_tiny_int_col small_int_col unsigned_small_int_col medium_int_col unsigned_medium_int_col int_col unsigned_int_col big_int_col unsigned_big_int_col decimal_col float_col double_col bit_col char_col var_char_col enum_col set_col date_col time_col datetime_col timestamp_col year_col] |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+By pruning unused columns we now avoid reading, allocating, and garbage collecting extraneous data:
tmp.P9vwSC8R> explain select a.id from sbtest1 a join sbtest1 b on a.id = b.id;
+-----------------------------------------+
| plan |
+-----------------------------------------+
| Project |
| ├─ columns: [a.id] |
| └─ IndexedJoin(a.id = b.id) |
| ├─ Exchange |
| │ └─ TableAlias(a) |
| │ └─ Table(sbtest1) |
| │ └─ columns: [id] |
| └─ TableAlias(b) |
| └─ IndexedTableAccess(sbtest1) |
| ├─ index: [sbtest1.id] |
| └─ columns: [id] |
+-----------------------------------------+This was one of the more impactful but context-dependent changes to our index join benchmark. We saw a 50% boost by eliminating 90% of the rows we were reading, but of course we would have seen a 0% change if we chose to return every column. On the other hand, every query that reads data will experience a similar speedup depending on the fraction of columns referenced.
Range templating#
Index lookups are only one type of lookup. Range lookups can generally include any type of filter or combination of filter expressions. The most common case is a filtered indexed scan.
To give one example, building a range filter over 3 columns x, y, and z will create 3d pockets of range space. The final number of pockets is proportional to the number of OR clauses in the filter. Unioning, intersecting, and overlapping ranges to get to the final ranges is expensive.
Join lookups are unlike static index lookups. Joins have a
fixed structure for inner row to outer table lookup. Therefore, we can
populate a template for every key from the inner table. In our example
query, the range will look something like (<id>, <id>). There is one
range because there is no OR expression. There is one column dimension,
because we are only restricting the id space. And the range is often
an exact key lookup (point lookup).
Reusing a range template via lookup keys gave us a 13% speedup that generalizes to all joins.
Point lookup shortcuts#
We generically convert range representations in Dolt the same way we generically build ranges in go-mysql-server. So similarly to range templating, we can optimize Dolt ranges given our narrow assumptions about join lookups.
The benchmark is a point lookup, which means we will match either one or
zero outer rows for every inner row. Our IndexLookup now computes this
attribute upfront when a range does not violate any uniqueness
constraint:
- The index is not unique
- The column expressions are nullable
- The range has one or more unrestricted column expressions
- A range expression is not an equality
If a secondary lookup is unique and we will always match either one or zero rows in an outer table, then we can skip Dolt’s range conversion, setup, and partitioning. Point lookups are also simpler than range seeking; the latter has to call a series of callback functions rather that simply comparing key to key. The result of these simplifications is a 17.3% speedup on indexed point lookups. If the join index is not unique, the join condition is nullable, or we are using a join index with more columns than the join condition, we fall back to scanning a generic range for multiple outer table rows.
Cursor reuse#
Searching prolly trees is the same as searching B-trees. We start at the root node and compare key spaces moving down towards leaves with increasing specificity. Dolt’s constructs cursor objects at every level of the tree to make it easier to navigate both up and down, but has the downside of creating many objects for a disposable search.
A search that only creates one cursor might be useful in this case. We settled on a reuse approach. Repurposing the same cursor tree for multiple lookup keys yielded a 16.3% speedup. All join lookups are affected by this change.
Flatbuffer optimizations#
Google Flatbuffers’s (FB) C implementation plucks serialized data from a FB message as fast as native C struct access. Unfortunately, the Go implementation runs into compiler snags that impede fast deserialization. It is more expensive to read from a raw flatbuffer message in Go than index into a partially deserialized intermediate format:
goos: darwin
goarch: amd64
pkg: github.com/dolthub/dolt/go/store/prolly/tree
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkNodeGet
BenchmarkNodeGet/ItemAccess_Get
BenchmarkNodeGet/ItemAccess_Get-12 161640123 7.407 ns/op
BenchmarkNodeGet/Flatbuffers_Get
BenchmarkNodeGet/Flatbuffers_Get-12 48060355 25.25 ns/op
PASSAndy’s modifications store offset metadata alongside flatbuffers in our message cache. The metadata is specific to our tuple storage format, boosting index access 4X and the index join benchmark by 10%. Notably, the same optimization decreased the groupby benchmark by 30%.
Summary#
We are working hard to make Dolt fast. Today we talked about specific changes that aggregate to a 4x speedup in our index join benchmarks. Benchmarks are intended to generalize to everyday queries, but of course schemas, indexes, table normalization, tables sizes, hardware, and specific queries affect performance. If you would like to chat, comment, file issues, criticize, or complain, all are welcome on our Twitter, Discord, and GitHub!