
The bad old days of software development#
If you’re under 40, you’ve probably heard tell of a time, way far back
in the mists of ancient history, when software developers didn’t
commonly use source control. And I don’t mean that they didn’t use
git, I mean they didn’t even use p4, or svn, or even cvs. They
just made copies of the source files, made some changes, then FTP’d
them back to the master server afterwards.
I know, it’s hard to believe. But people really worked this way. Find the oldest, most grizzled greybeard in your office and ask them if the legends are true. They’ll have incredible war stories about how this workflow failed. This time of myths and legends produced truly harrowing catastrophes.

To make up for the fact that it was really hard to merge concurrent work streams under this workflow, people developed cultural workarounds.
- Segment the code base into disjoint components, and make sure
only one person is editing each component at a time. Later source
control systems like
p4formalized this custom, and made you declare to the server that you intended to edit a file withp4 edit. - Keep edits small and frequent to minimize the chance that somebody else makes changes that might conflict with your own. (This might be a good idea for other reasons, to be fair.)
- Shunt unavoidably large changes onto hard forks, then spend days laboriously merging them back in while everyone else waits for you.
Over time, as the software discipline matured, practitioners came to their senses and adopted source control. But while early source control systems mitigated these problems, they didn’t eliminate them.
- cvs,
released in 1990 (!), was the first commonly used source control. It
built on top of RCS, which could only track file-level changes. It
could (badly) merge changes from the server to the client via the
cvs updatecommand, but there was no equivalent merge from client to server. And ironically enough, it had fatal concurrency bugs that could corrupt the repository. - svn, released
in 2000, set out to fix the problems in
cvs, especially the repo-corrupting bugs. It used the same model ascvsand had similar (bad) merge capabilities. - helix (originally
known as perforce or
p4) is a commercial source control offering released in 1995 and widely deployed at many large software companies, including Amazon and Google. (Google’s internal source control store is a clone of perforce that scales better).p4’s innovation was server-level file locking: you had to tell the server you were editing a file withp4 edit, and anybody else who did the same would be warned you were working on it. You could also prevent anyone else from editing the file withp4 lock, which is as crazy as it sounds and shows how bad the merge problem was in those days. You could merge branches usingp4 integ, but this was every bit as difficult as withcvsorsvn.
All of these solutions helped software development scale up to larger teams, but they just weren’t good enough. As a professional discipline, we didn’t even understand how badly they were lacking, until grandpappy Linus showed us a better way.
The git commit graph changed everything#
![]()
Linus Torvalds released Git in 2005 to relatively little fanfare. The buzz that accompanied it was about how it was distributed as opposed to centralized, and in fact because back then git had a viable competitor (mercurial) the term DVCS (distributed version control system) was coined to refer to them. If you were in industry during this time, you surely remember the debate in these terms: distributed systems were obviously better than centralized ones, and we should all prefer them. But programmers at the time also balked at the unfamiliar model and the unwieldy syntax of the new tool. Git usage began to really pick up in a big way after GitHub launched in 2008, and made the process of hosting repositories and merging changes easier, by slapping a GUI and a change management workflow (pull requests) on top of it. At this point, GitHub became a centralized component in what was sold as a distributed system. So why did it take off?
Because the winning feature of git was never its decentralized nature, but its commit graph model.
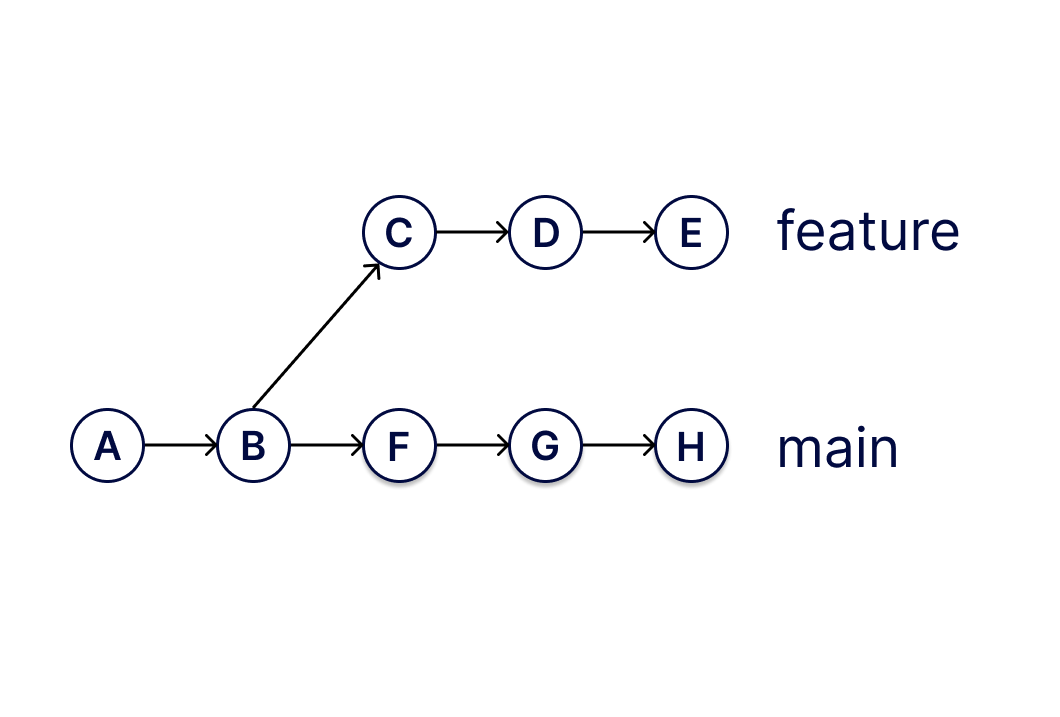
It’s git’s commit graph that allows merges in git to work so much
better than they do in cvs or svn or p4, which used simple
textual analysis to attempt to merge different files together. The
commit graph lets git reason about which changes have already been
incorporated into a file, making it possible for merges to be seamless
unless both parties edited the same lines of a file.
It’s hard to understand how much of a game-changer git was unless you have experience working in source control systems before it. It’s not just that things got easier, although they did. It’s that entirely new workflows became possible, especially the sane maintenance of long-running feature branches.
Git made it feasible to develop on a branch or fork for months at a
time if you wanted, because you could periodically git merge master
to avoid a painful and time-consuming merge to get your changes back
into the central repo (and to reassure yourself you were on the right
track throughout).
The bad old days are still here#
What I’m going to say next will blow your mind: when it comes to
database technology, we are still in a pre-source control world. Not
only do we not have git for databases, we don’t even have cvs for
databases. Don’t believe me? Read this round-up of technology that
claims to be “database version
control”.
The lack of true version control in the database world leads to all the same problems with database application development that plagued software development for so many years. All the cultural workarounds for a lack of version control have become enshrined as best practices for database development!
- Segment the database into disjoint units and operate on a single unit at a time. If you don’t do this, then any long-running transaction will hit locks from other transactions, or be forced to roll back and start over. Reducing row-level lock contention is a primary consideration in schema design.
- Keep transactions small and frequent. If your logical unit of work is too big, meaning that it takes too long (the user is filling out a complex form), or touches too many rows and tables, you have to come up with clever strategies at the application layer to avoid hitting locks or being forced to roll back by other transactions. These strategies typically involve committing smaller transactions into dedicated, separate tables, then manually merging those back into the real tables when the logical unit of work concludes. This is so much work and so hard to get right that application developers usually just rule out any workflow that would require it.
- Take an outage for unavoidably large transactions, like adding indexes or other schema changes, or changing your domain model.
Sound familiar? This is exactly analogous to how software engineers managed source code before version control was adopted.

But it’s actually even worse than that: database sessions typically can’t be held open for longer than a few minutes, since you can’t count on keeping a network connection alive that long. Imagine if your unit of work when writing software was 10 minutes, and if you took longer than that without committing and pushing, you might lose all your work or find it unmergeable. That’s the current state of the art with database transactions.
A better world is possible#
We’re building Dolt, a version controlled database with the same revision control model as git. This means you can branch and merge, fork and clone, push and pull your database (both schema and data) just like you can your source code. It’s the only SQL database with these features, and we built the storage engine from the ground up to make this possible.
When we tell people about this, there are two typical responses:
- That’s really cool, how come nobody has done this before?
- What would I use that for?
Sometimes the same person has both reactions!

Just like it was hard for software developers to understand what they were missing in a pre-git world, it’s not obvious to a lot of engineers how they would use version control in a database. What’s it for?
We have quite a few
answers
to this question, but today we’re going to focus on one of the most
interesting and powerful ones: branches in Dolt give you an atomic
unit of work that lasts as long as you want. With dolt, you can have
a “transaction” that goes on for months. And you can even share that
same unit of work between multiple users, allowing them collaborate on
the same set of changes before merging them back to main.
This is all possible without any major changes to a normal database application development workflow.
How does this work?#
Branches in Dolt work just like branches in git, just on tables instead of files. So in order to give yourself a “transaction” that goes on as long as you want, you do this:
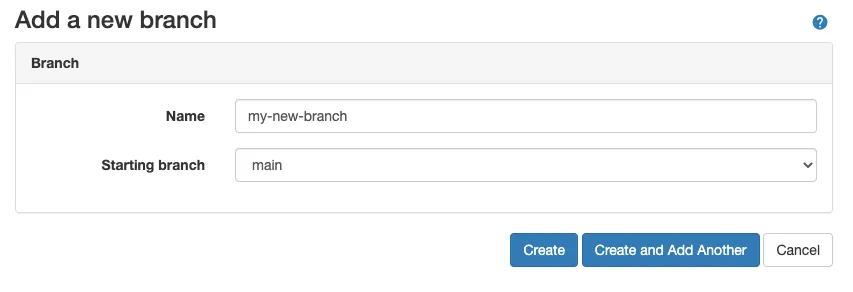
- Create a branch for the customer (or other unit of work). There
are multiple ways to do this, but the easiest way is to use the
DOLT_CHECKOUT()function, like so:SELECT DOLT_CHECKOUT('-b', 'myBranch');. This the start of your month-long “transaction”. - Connect to that branch going forward. You can use
DOLT_CHECKOUTin each session, or use a connection string for that branch, such asmysql://127.0.0.1:3306/mydb/myBranch COMMITas many SQL transactions as you need, using a logical unit of work that makes sense for your application. More than one user can participate, connecting to the same branch and editing it simultaneously. Repeat until you’re done making changes.- Merge
main(optional). This will allow you to resolve any conflicts in this branch, rather than on main. There are lots of ways to do this, but usually you will use theDOLT_MERGE()function. You’ll also want to check for and resolve any conflicts that result, just like with a git merge. - Merge this branch back to
main. This is equivalent to committing your month-long “transaction”, and means that other users can now see the changes you’ve been working on.
That’s it! Using this workflow you can create persistent, long-running “transactions” that can be broken up into many smaller, durably committed units of work. Users can close your application and return later to pick up right where they left off, or even collaboratively edit together.
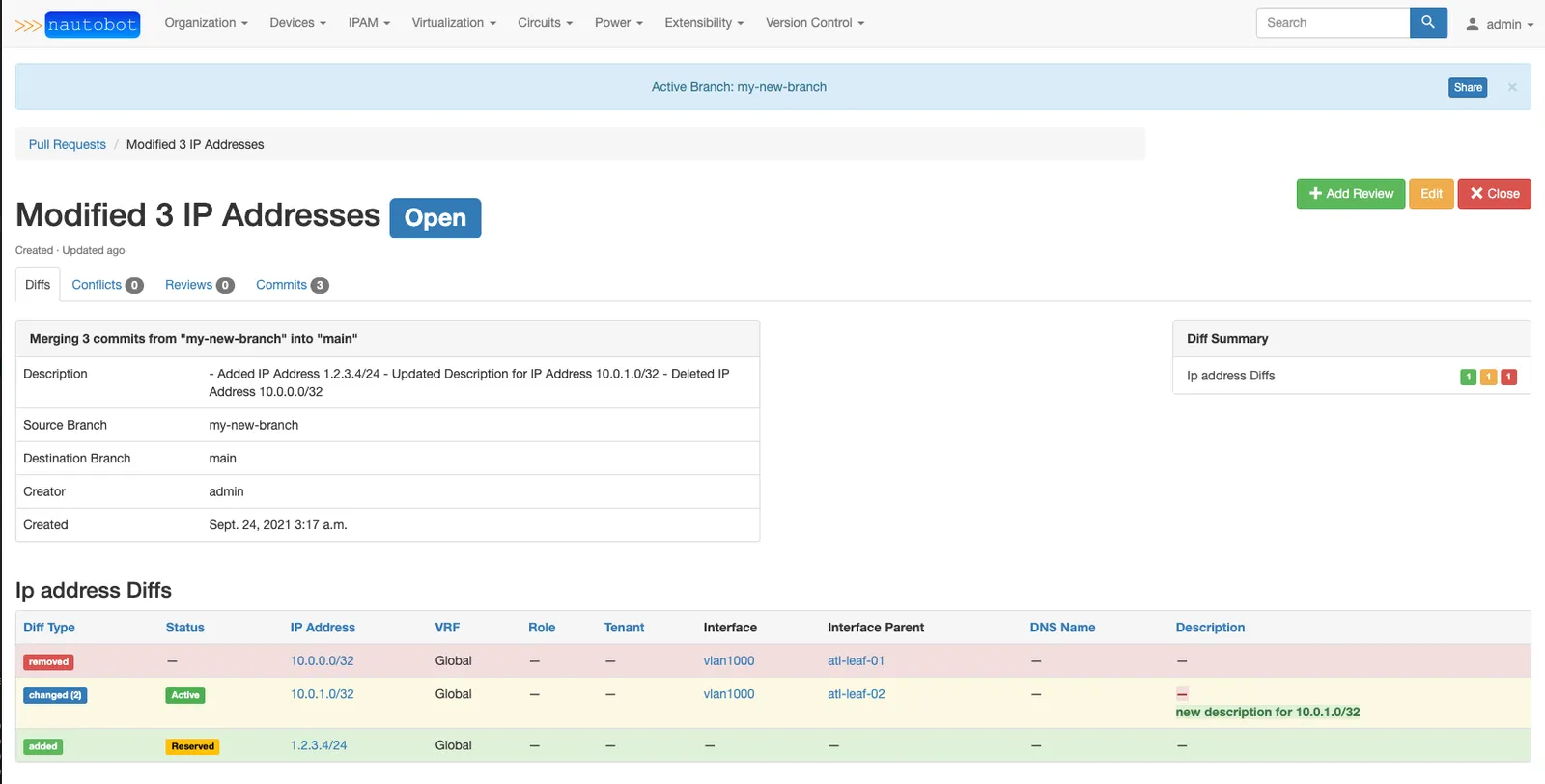
Example: Nautobot#
Last month we announced our collaboration with Nautobot, which is network configuration software. They integrated with Dolt to give their customers the branch / merge workflow when editing their their network configuration data. In this case, they chose to make the branching model explicit, rather than modeling it as a workspace or other “uncommitted” change.

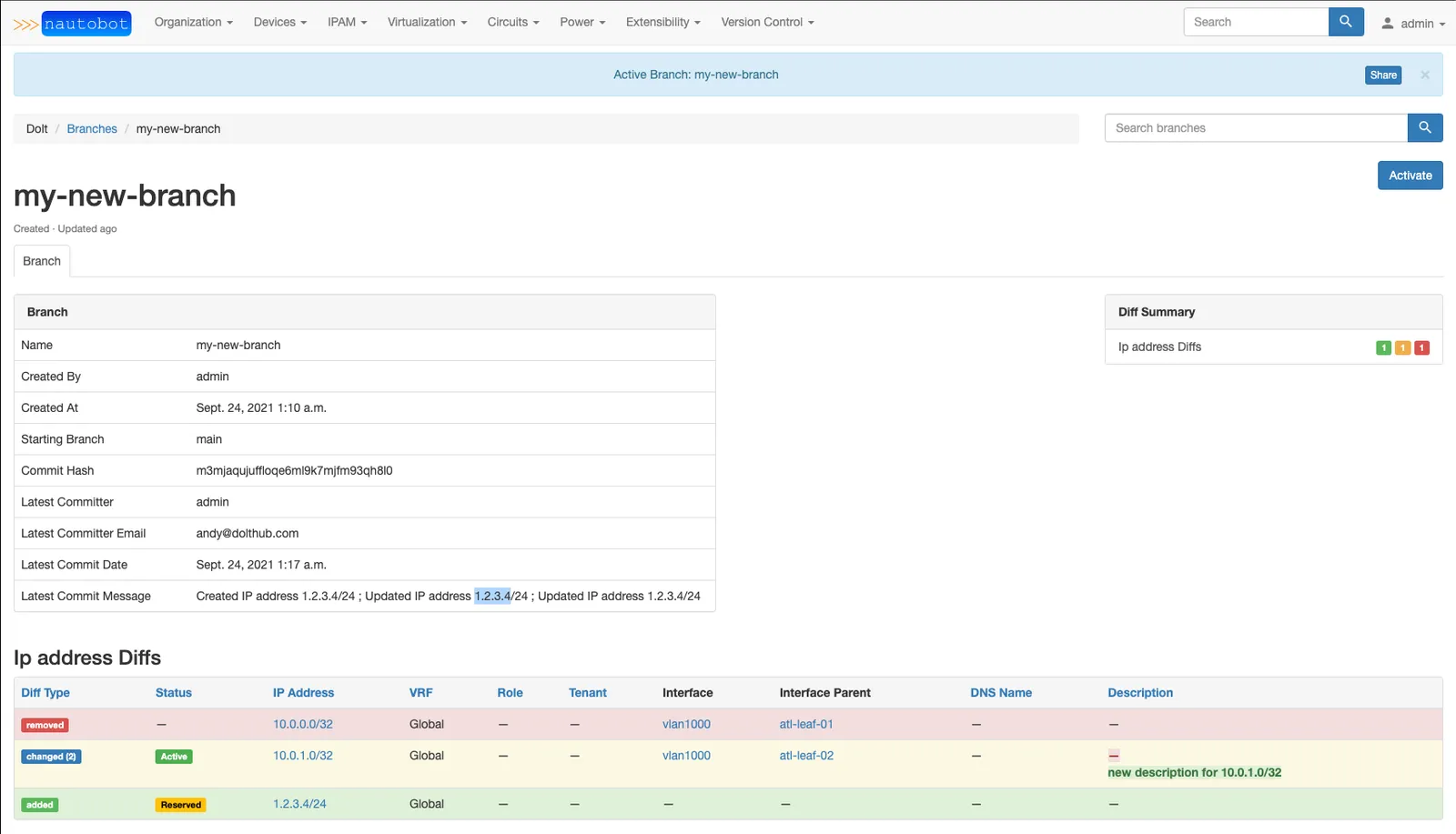
After creating a branch, the customer proceeds to make edits to the network configuration, using the same UX workflow as before the Dolt integration. But now their changes are confined to their personal branch, so no one else in their organization sees them (unless they want to). This can go on as long as they want, across multiple database sessions, spanning months if desired.
When the customer is happy with the changes they’ve made, they can view a diff of the changes. This functionality is built into Dolt and accessible via special system tables.
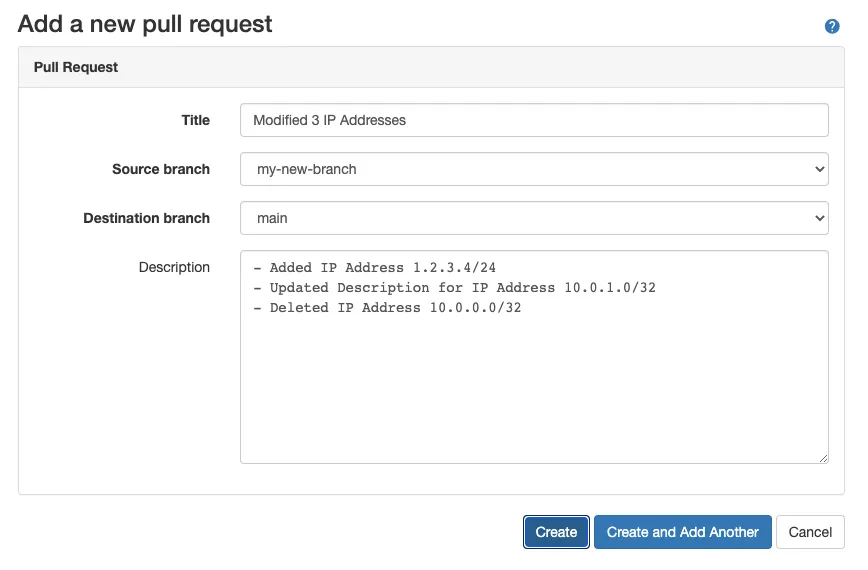
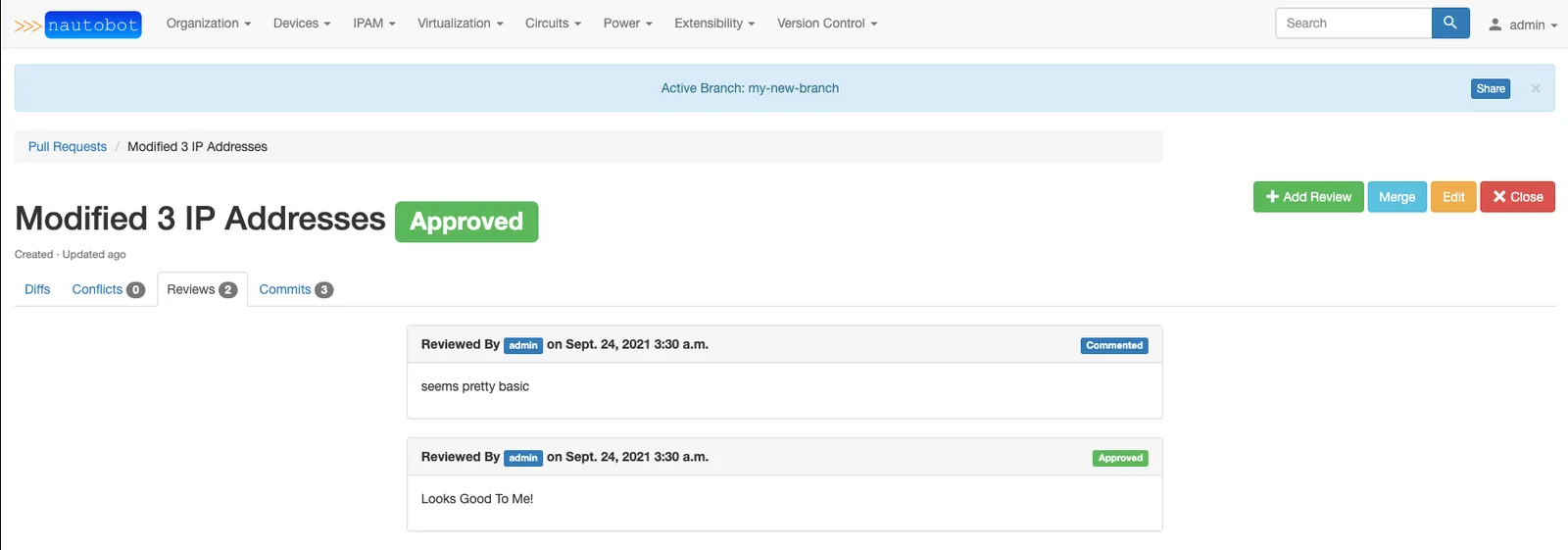
Finally, before committing their changes back to main, the customer opens a pull request to allow their colleagues to review it for mistakes, make comments, etc.
Other use cases#
The same basic pattern above is useful whenever you have an application that could benefit from the ability for the user to complete a unit of work in more than one sitting. In our (biased) opinion, most applications would benefit from this ability. But there are some use cases where Dolt is especially compelling.
- Large schema changes with no downtime. Why take an outage? Create that giant index on a branch, then merge it when you’re done (indexes are merged along with schema and data). Nobody had to stop using your application.
- CMS. Nautobot is an example of a CMS, a change management system. Wikis are another, and so are blogs. Give your users as much time and as many sessions to make their changes as they want, then let them merge at their leisure.
- Creativity tools. This includes website builders, photo editors,
etc. Save the user’s work with
COMMITfrequently so they don’t lose it when the browser dies, thenMERGEit back tomainwhen they are ready to publish their changes. - Giant config files. I encountered these frequently at Google, and they were giant, often 100,000 or more lines. When I asked more senior engineers why the configuration data was managed in such an unwieldy way, instead of with a web GUI, the answer usually included, “because this way we have change management on the data.” No excuse now, Google.
Conclusion#
It’s not 1990 anymore. Software development and databases have come a long way. It’s time to re-imagine how database application development should work and free yourself from obsolete constraints, like a 10 minute transaction. With Dolt your transactions can go on as long as they need to.
Interested? Come chat with us on our Discord. Let’s get you started building your next application on top of a Dolt database.