Menus bounty retrospective

Dolt is a MySQL-compatible database with branch, merge and diff. DoltHub is a place on the internet to host, share and query Dolt databases.
This blog is a retrospective on the menus bounty that launched on July 14th and wrapped on August 4th. Part of the bounty acceptance criteria was that each pull request contain only one restaurant. This requirement, coupled with the expansive search space of menus data, led us to receive over 50,000 commits and pull requests. Through this process we discovered some rough edges of the tool at scale. Below, I demonstrate how the commit graph that we built contributed to those challenges, but first let's see how we did.
How we did?
| Unique Restaurants | 44,720 |
| Menu Items | 6,479,347 (100%) |
| Unique Menu Items | 2,695,669 (41.6%) |
| Menu Items with Pricing Info | 6,312,564 (97.4%) |
| Menu Items with Nutritional Info | 157,125 (2.42%) |
| Number of cells edits | 26,992,570 |
| Contributors | 6 |
As is apparent from the results, pricing information is a lot easier to come by (and maybe just easier to scrape) than nutritional information. We might run a menus-v2 bounty where we collect nutritional information specifically. The pricing data we do have is interesting on its own. Many of the submissions were from delivery service companies like UberEATS or GrubHub. This data lends itself to competitive pricing analysis by location. For example, HOT AND SPICY MCCHICKEN MEAL variance in price:
menus> select name, restaurant_name, identifier, price_usd from menu_items where name = 'HOT AND SPICY MCCHICKEN MEAL' order by identifier;
+------------------------------+-----------------------------------+---------------------------+-----------+
| name | restaurant_name | identifier | price_usd |
+------------------------------+-----------------------------------+---------------------------+-----------+
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S (RIVERSIDE) | UBEREATS, AUSTIN, TX | 4.35 |
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S (CLARK & ONTARIO) | UBEREATS, CHICAGO, IL | 6.60 |
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S (7TH/ALAMEDA) | UBEREATS, LOS ANGELES, CA | 6.66 |
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S® (7TH AVE & VAN BUREN) | UBEREATS, PHOENIX, AZ | 5.67 |
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S® (MCDOWELL & 7TH ST) | UBEREATS, PHOENIX, AZ | 5.29 |
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S® (3502 ROOSEVELT)® | UBEREATS, SAN ANTONIO,TX | 4.25 |
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S® (703 W HOUSTON AVE) | UBEREATS, SAN ANTONIO,TX | 4.25 |
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S® (2345 EL CAJON BLVD.) | UBEREATS, SAN DIEGO, CA | 8.99 |
| HOT AND SPICY MCCHICKEN MEAL | MCDONALD'S® (1280 12TH ST) | UBEREATS, SAN DIEGO, CA | 8.99 |
+------------------------------+-----------------------------------+---------------------------+-----------+Final Scoreboard
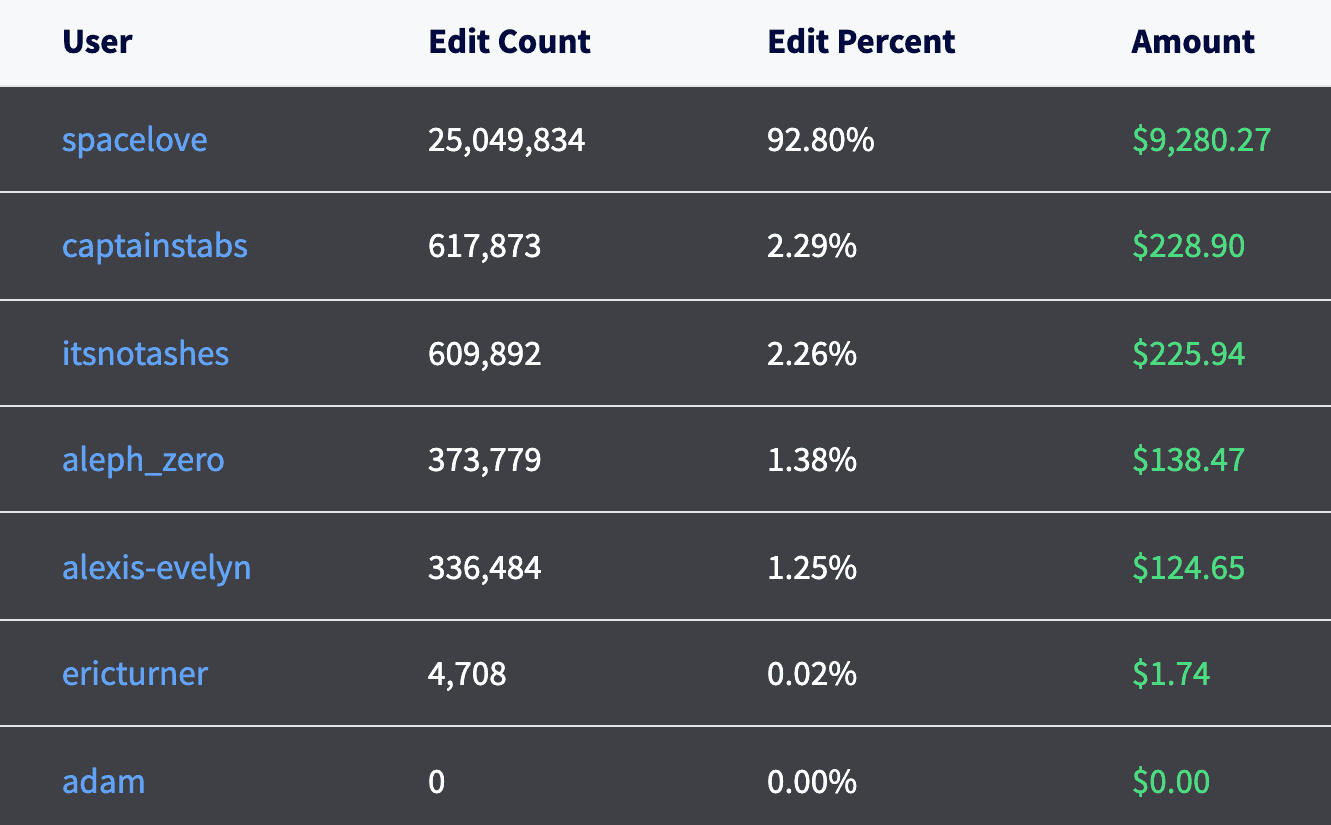
50,000 commits. What's the big deal?
This was our first time generating a database that had over 50,000 pull requests and commits. The good news, you can do it. We did, however, discover that some interactions with a tall commit graph are slow. It's not all bad news, though, as we've already allocated engineering resources to improve these algorithms. The menus bounty may have created the tallest commit graph that Dolt as seen yet, but it certainly won't be the last.
Why might a commit graph be tall?
Of the 50,000 pull requests we received, most contained a single commit whose parent was the first or second commit in the database's history. In other words, contributors tended to branch off of master from the same point early in the commit graph. Doing so meant that each subsequent pull request that was processed required a longer and longer commit walk to find the common ancestor. Finding the common ancestor of two branches gives Dolt a proxy from which to calculate diffs, conflicts and merges. For operations like fetch the implications are similar (we have a tree of the same shape from which we download refs.)
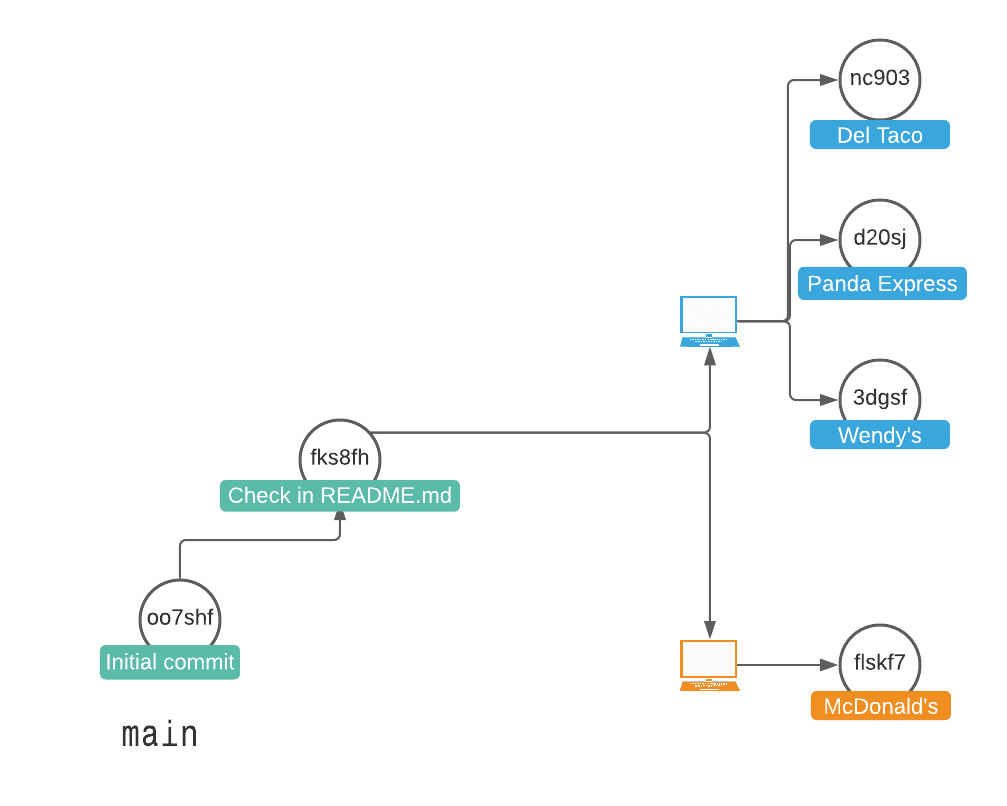
Let's follow a visual example of building a tall commit graph that then needs to be traversed. The blue user creates three pull requests for three restaurants, and the orange user creates one pull request for McDonald's:
From this point, if you merge all of the blue user's pull requests, you'll get three merge commits on master. The following diagram highlights this post-merge state, and the path that Dolt must traverse to merge the orange user's pull request into master.
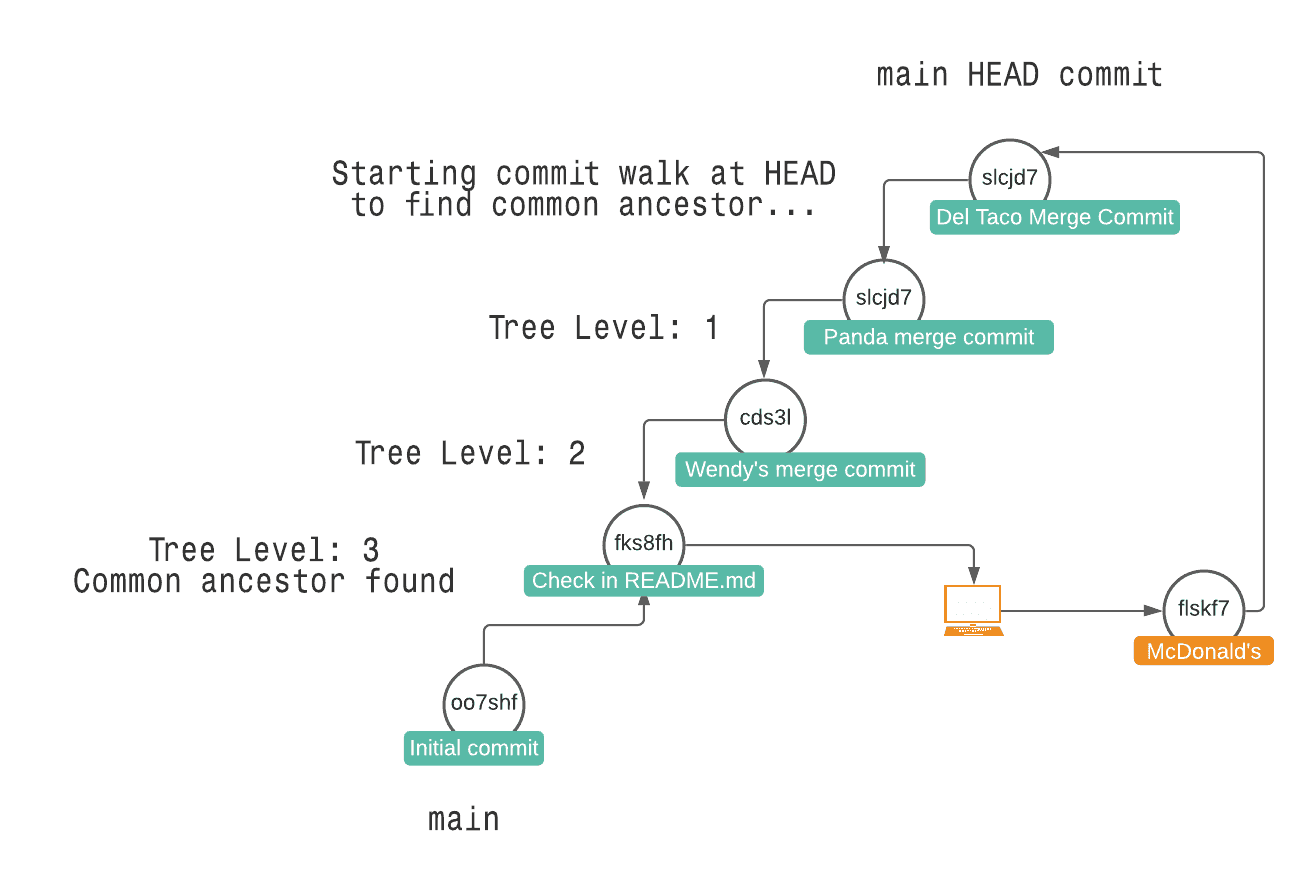
From this reductive example with just four pull requests, you can see how the time it took to calculate the common ancestor increased with each subsequent merge.
Scoreboard improvements
We calculate a bounty scoreboard for each merge commit in the database. The latest scoreboard can always be found on DoltHub. The sharding algorithm that was used to process these scoreboards benefited from some improvements as well, allowing us to efficiently process the scoreboard build queue.
What's next for menus?
The menus database could benefit from some housekeeping, like parsing out delivery service from the identifier and making a strong schema. We might run a second bounty for menus to collect just nutritional information.
Conclusion
If you have interest in contributing to a bounty, join us on the us-schools bounty. That, or come chat with us on Discord.