Assembling a Grand Catalog—A Data Bounty Retrospective

Should you use DoltHub Bounties for your data-wrangling needs? Our bounty partners wanted to assemble a “master” catalog of all the college courses taught in the United States. For them, it was an easy riddle.
To recap, a partner approached us with a request to create a database of US College Course Catalogs. At first we were a bit hesitant because the data wouldn’t be open after the bounty ended. But, we’re intrepid souls, and we ended up giving it a try. We’re excited to share the results in this blog post.
The Virtues of Data Bounties
So far hosting bounties have delivered a flywheel of benefits for DoltHub. First, they incentivize community use and familiarity with the product—we find that Dolt and DoltHub confer compelling new powers for programmers, but only if they overcome the initial hurdles towards familiarity. Secondly, in addition to attracting participants to take part in the collection and curation of the dataset, once acquired, the data itself serves as an attraction to Dolt and DoltHub. Users who wish to peruse or look at the data without needing revision control features are incentivized to acquire Dolt and utilize the in-built sql engine. Lastly, the data is fascinating. It is this potential to source riveting datasets that excites us the most about all that’s enabled by Dolt.
The Results
After running the bounty for one month, with an incentive of $10,000, we received structured course catalog information from 65 schools nearly 7 GB, and spanning as far back as 1984. We received 77 PR’s from 13 different community members, eager to claim their share of the prize, at the cost of under $200 per school.
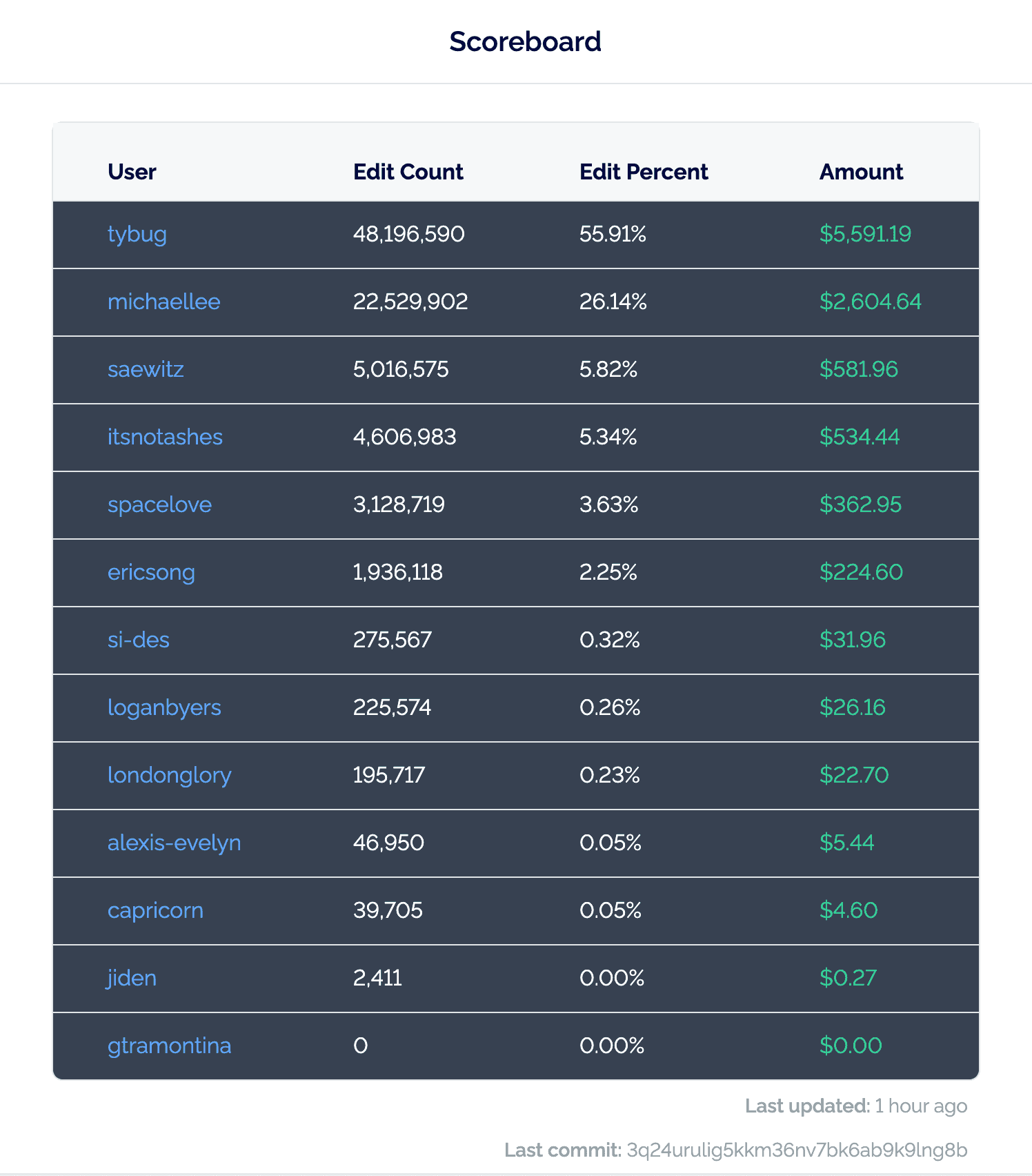
The final scoreboard for our National Course Catalog Data Bounty.
After an initial kernel of work of describing and clarifying the “shape” of the data via a schema, bounties take on a life of their own. After a bit of gamification, the data collects itself! Compare that to the challenges involved with trying to mine this data in-house, either taxing your development team, or outsourcing the project to an agency or freelancers.
Ease and Affordability
It’s important not to underestimate the amount of work involved, to gather the data for each school requires understanding the topology of the online course catalog site and the creation of a custom scraping tool for each one. Although there are shared design patterns across the individualized scrapers, there are limited opportunities for code reuse. In short, there’s no way we could match the affordability and ease of the bounty model with more traditional approaches.
A Transmogrification
Bounty participants are motivated by a myriad of factors. Of course they want to increase their share of the prize; yet we find the force of the dollar is rivaled by that of the friendly competitive spirit, i.e. the desire to outdo one’s collaborators. Furthermore, participants feel a sense of stewardship over the database and anticipate with pride the future use of the dataset they assemble. Self and altruistic interest thus dovetail synergistically here. Our bounty partners in sponsoring the prize pool wished to remain anonymous and asked that we privatize the dataset at the bounty’s conclusion, which dampened community interest a little bit. Even still, the force of the remaining motivators were enough to drive impressive levels of participation.
We’ve stumbled upon something a little magical, a way to transmogrify the tedium and doldrum of data-cleaning into a fun and engaging contest. We’ll be discussing the bounty results with our partners over the next week and you may see a version 2.0 of this bounty. There’s wonderful interest from all corners.

Our top earning participant took home a whooping $5.6k and had an edit count of more than 48 million.
Info-oleum
What information is out there that would advance your projects, existing in an unrefined and latent form? What insights might you gain, if only the laborious process of gathering and cleaning that information could be elided? Our partners wanted deep insight into what’s being taught across the nation, and a data bounty was the answer.. Your questions shall be different, but we are eager to discuss them all the same. Reach out to us via our Discord!
You fund the bounty prize pool, we design, publicize, and administer the data bounty, and out the other side comes structured, massive datasets.
Let’s take a closer look. Suppose we had a dire need for some semi-structured data. Our national course catalog will serve as an instructive example. And suppose that a programmer could maintain a pace of one catalog per five hours when designing and deploying a scraper. If we assigned 4 programmers and allocated 15 hours a week for each programmer, at the end of one month, we’d have data from 48 schools, (not quite the 65 from the bounty!). Those 360 programmer-hours at the low end might cost $22,500, but could reasonably run as much as $36,000. All to fall short of what a data bounty accomplished with an input of only $10,000.
Of course, we’re assuming that the team has the spare bandwidth to pursue this project. Most of us don’t have 4 engineers with 15 free hours a week to dedicate to data acquisition and transformation, realistically an in-house team could only take this on by sidelining existing projects. Instead, this work would need be outsourced, or the in-house team expanded to accommodate this work. Add the cost of talent acquisition to the raw cost of the programmer-hours, and we could easily exceed $50,000 to accomplish the same as the data-bounty.