
Application Programming Interfaces (APIs) are the dominant mode of distributing data on the internet. Twitter debates in the data science community about Comma Separated Value (CSV) files vs APIs have flared up lately. We think both of these options are suboptimal for data distribution.
We think we should share data like code, in a forkable, mergeable database in the model of Git. Fortunately, we built one of those. It’s called Dolt. We also built DoltHub, a place on the internet to share Dolt databases.
When we share data in Dolt format:
- We can get a local SQL database in one command.
- We communicate the schema (or types) of the data along with the data itself.
- We can see who changed what, when, and why from the commit log and diffs.
- We can make writes to the data and still get updates from the source.
- We can share our writes back with the data creator if we find a mistake.
- Many people can write in parallel on their own branch.
In this blog, using those themes, I’m going to contrast pulling NBA player data from the NBA.com API with getting the same data using Dolt and DoltHub. The example data I’m using is all season and career statistics for every player ever to play in the NBA.
SQL in one command#
To get this data from the NBA.com API took me about four days of work on and off. I even had a convenient, well documented open source python package to work with.
One of the problems with using the API is rate limiting. Once you make about 50 requests in a row, your requests start timing out. I started one script to pull all player data with a 60 second sleep between requests and retries and it failed after getting through about 3000 players. Finally, I ended up going with a two stage approach, one to pull the data and write it to disk locally so I could preserve progress on a failure, and a second step to import the data into Dolt. Here is the resulting scripts.
In Dolt, I can view the data on DoltHub before I decide to work with it. I can run some sample SQL on the web to get a quick idea what is in the dataset. I can then get a copy of the data locally using dolt clone dolthub/nba-players. The four day process of acquiring data becomes four minutes.
SQL is a very rich interface that allows for all manner of data analysis and tool integration. Many types of analysis can be performed with no code (except SQL if you consider SQL code). If I want the data back in CSV or JSON format I can just pass -r csv or -r json to dolt sql after I build the right table from a SQL query.
Type information#
The second problem I ran into acquiring this dataset was understanding the schema of the data. For instance, the API returns college basketball statistics headers but no data. Originally, I thought the API might not have data for some players but after scraping every player, I realized the college basketball blob was always empty. This is a common problem with APIs, you need to pull a lot of data to ask basic questions about the schema.
With Dolt and DoltHub, I can view the schema of the data before I pull it. I can see what the tables, columns, and types the data distributor intended. If something is strange with the schema or types, the creator can document it in the README. This NBA player statistics database has tables for season statistics for the regular season, playoffs, and all star games. It also has career statistics. There are two additional tables describing teams and players. This is all easy to grok on DoltHub.
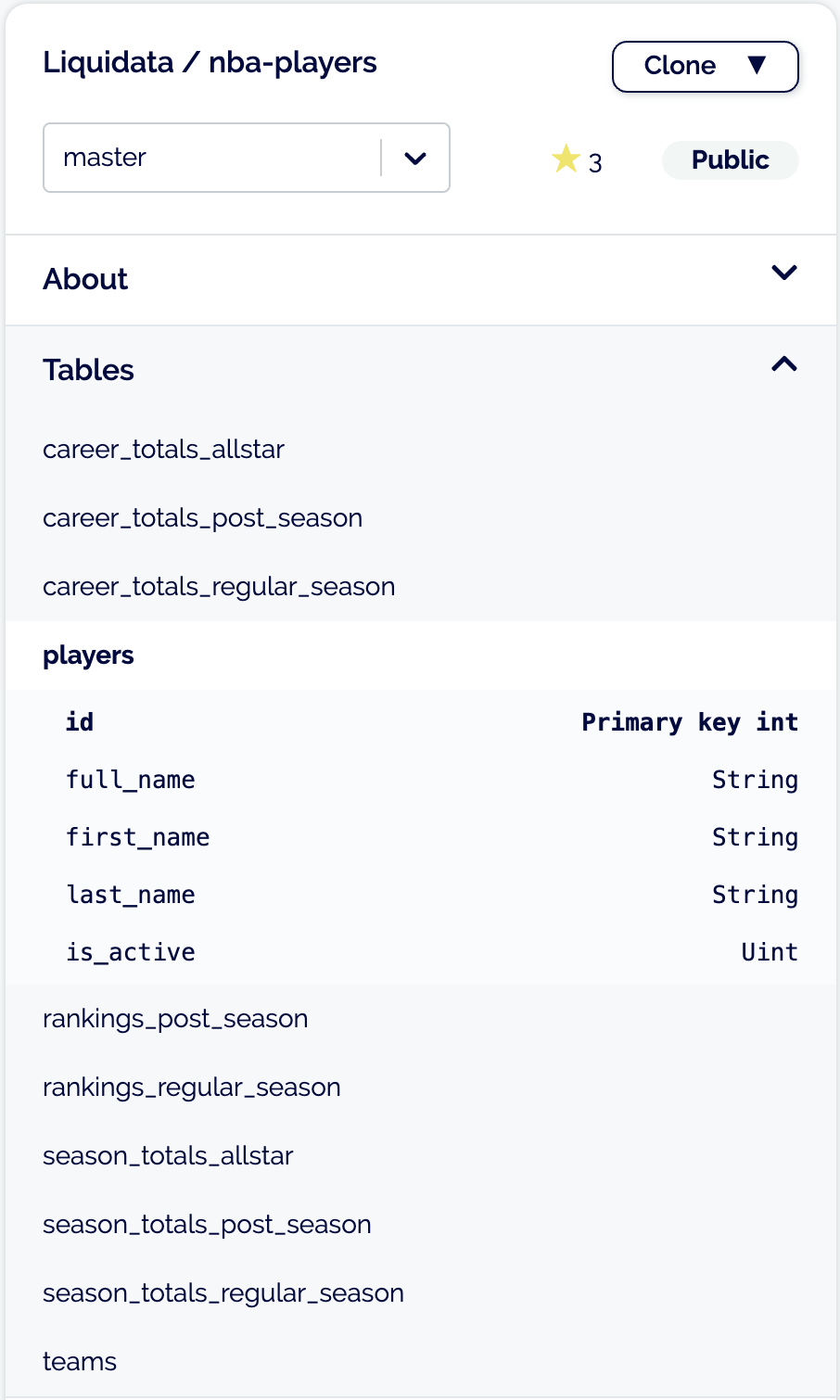
We will add more schema information to Dolt in the next couple months. We will add foreign keys, database size, column coverage, and min/max per column. If you think of other things you need to know about a database you first come across, please let us know.
Commit log and diffs#
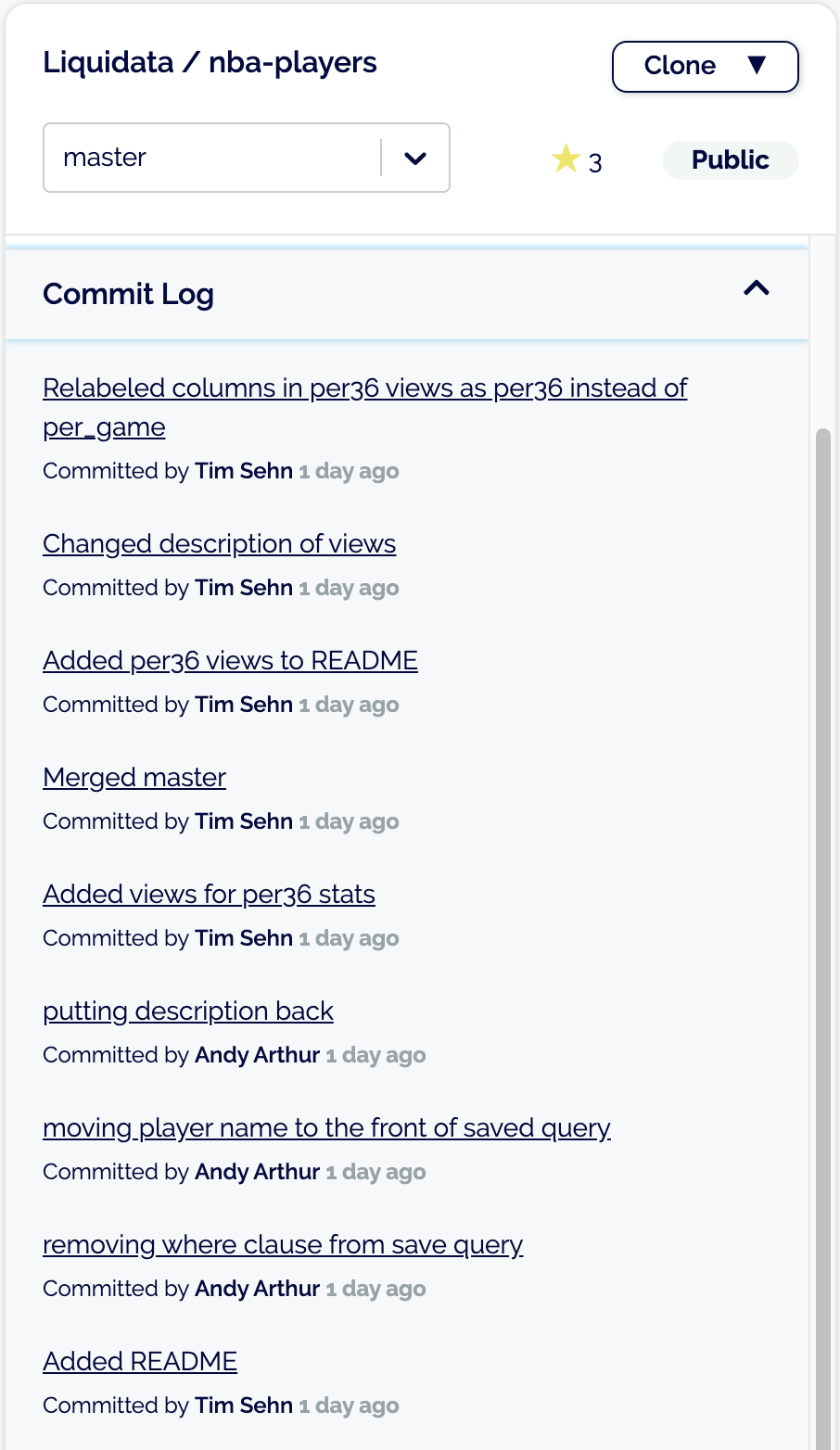
How often is this NBA data I pulled updated? Is the current season statistics updated every day or are season statistics published at the end of the season? If I want to keep this data updated, how often should I pull it? There is no way to tell from the API. I need to run a job daily and see if I received different data than last time. But how do I tell if I received different data? I can’t directly ask the question, “What changed?” to the API. To understand what’s changing, I must devise some clever scheme like recording how many games played there were yesterday and seeing if those were incremented by one for last night’s games played.
With Dolt, you get a commit log and diffs. You can see every change to the database since inception. Each change has an associated diff. You can compare any two commits and easily see what changed. Looking at the commit log for this data, it is not being updated right now. Updates will start when the NBA plays basketball games again.
Make writes and still get updates#
What if I want to modify the data coming from the API? Let’s say I’m a Houston Rockets fan and I really believe that James Harden’s dunk counted. I can make this change locally, but every time I pull new data, I have to remember that I made that modification. Most people would put this special case in the import job. Moreover, I can’t have both versions of the data exist at once in the same database.
Dolt solves this problem. I created a branch called james-harden-basket-counts. I ran two update queries to add two total points to his season and career statistics. I forgot to add a made field goal on my first pass, but I later did that as well. Now, we have two versions of the data existing in parallel with the ability to diff between the two. When new data comes in I dolt merge master and resolve the conflict that will be thrown, assuming James Harden accumulates more statistics eventually. It’s easy to see how this process can scale to a large number of modifications.
Collaborate with the data maintainer#
Now, let’s say I want the NBA to adopt my change so I can avoid merge conflicts in the future. With an API, I have no formal mechanism to request a change to the underlying data. I have to go through some sort of outside channel to get data corrected. This process is so burdensome, it rarely if ever happens.
Contrast that will Dolt. I can submit a Pull Request to the maintainer and lobby for my change to be included in master. The maintainer can review my case and decide whether to update the master copy or leave my change on its own branch.
Large groups of collaborators#
Now imagine all this with a group of hundreds or thousands of collaborators. This kind of workflow is unimaginable in the API world but with Dolt, as with Git in open source software, it can be a reality for databases.
Conclusion#
Collectively, we spend a lot of code taking data out of a database, putting it in an API for sharing, sharing it, and then putting it back in a database format for consumption. Dolt allows you to instead share the database, including schema and views, allowing you to delete all the code used to transfer data. DoltHub provides a convenient web interface for sharing Dolt databases. We think Dolt and DoltHub are a fundamentally better approach to sharing data. Try both today.